






本文参考了:
- https://courses.cs.washington.edu/courses/cse378/09wi/lectures/lec15.pdf
- Cache performance measurement and metric
- Cache placement policies
简述
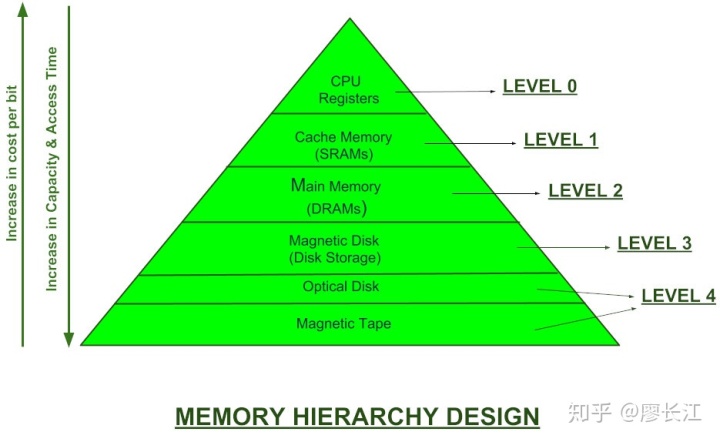
相信你肯定对这一张图很熟悉了(如果还是第一次听说就请关掉此页面吧:))。越靠近 CPU,速度越快,但是容量小且价格昂贵。如何能够高效利用缓存(LEVEL 1),是操作系统中非常重要的一环。
上篇文章中,我们有讲到同一个 CPU 中的 core 之间会对 last-level cache产生竞争,从而影响系统性能。UMA 架构下,假如一个 CPU 里面有多个 threads 运行在不同 core 中,可以将其中一个 core 上的 thread 移动到其他核,从而缓解了对 last-level cahce 的竞争,达到提高速度的目的(我们也讲了这种方法在 NUMA 架构中不适用,具体原因请看上篇文章)。
Last-level cache 竞争给性能带来影响的原因是显而易见的,因为 cahce 大小有限,其中一个 thread 占据一部分 cache,很有可能是会把其他 cache 的挤占掉的。这种现象是 cache miss中的一种。cache miss 的大小是衡量缓存效率的重要指标。
此篇文章将先讲讲 cache 一些基础的知识,后面再逐步深入。
Direct Mapped Cache
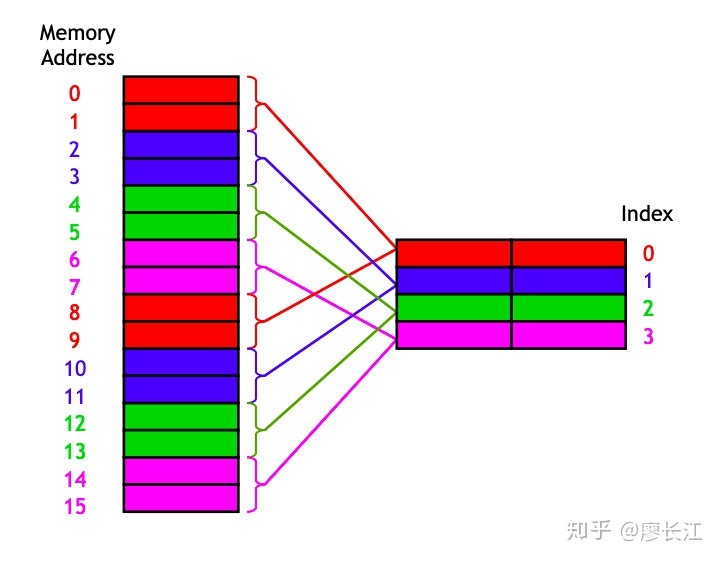
下图中,main memory 有16个 bytes,cache 有4个 bytes。
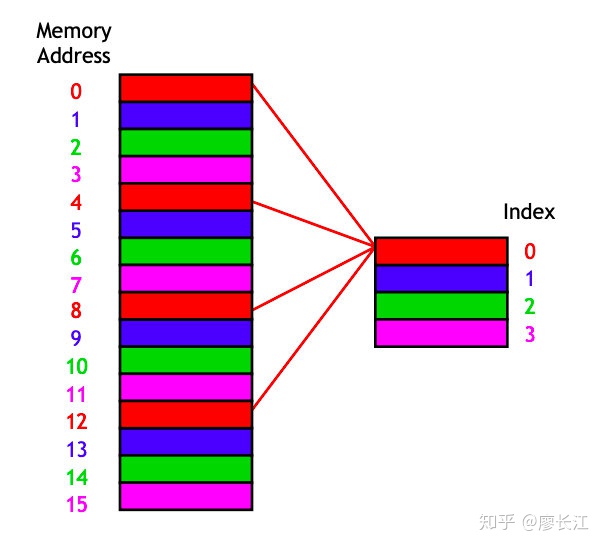
简单来讲,就是把main memory 中的 0,4,8,12映射到 cache 的0;1,5,9,13映射到 cache 的2… 对,就是取模运算。这回答了我们的第一个问题。
这种方法叫做Direct Mapped Cache,是最简单的一种 map方法,效率也不是最高的,还有几种可以通过以下链接查看 : https://en.wikipedia.org/wiki/Cacheplacementpolicies
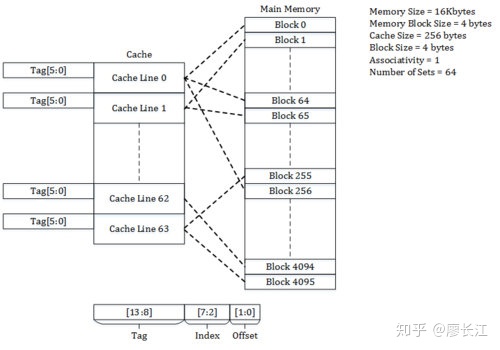
如果要是复杂点,可以看下维基百科上的这张图,原地址如下: https://en.wikipedia.org/wiki/Cacheplacementpolicies
从 cache 中读数据
用上面的方法,可以很容易知道 main memory 某个 byte 的数据在 cache 的什么位置,但是要知道有很多个不同的 block 指向cache 里同一个位置。
可以把 main memory 的最高位作为 tag,存在cache 里面,如图:
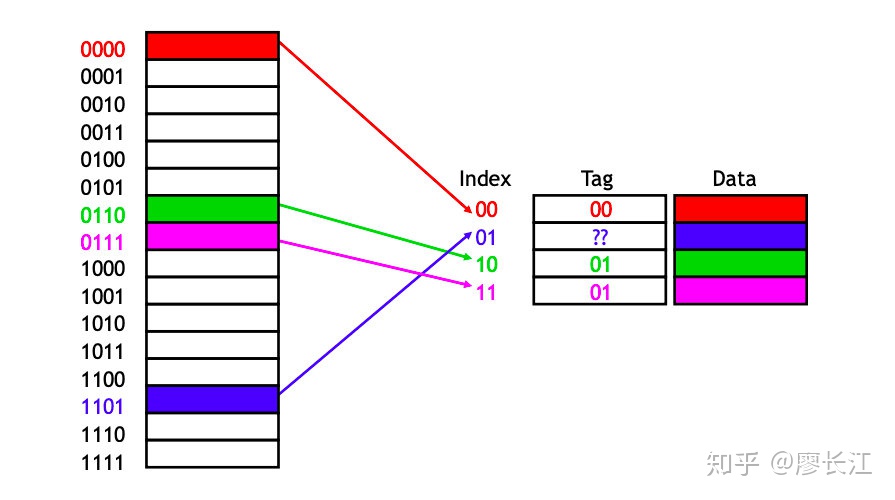
这样,比如cache 中一个 entry 的 index 为 01,他的 tag 为 11,对应的 main memory 地址就是 tag+index,即 1101。
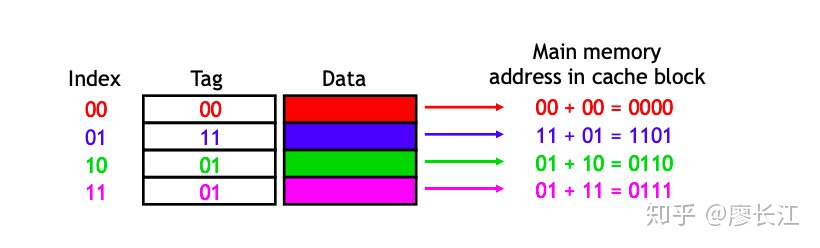
再进一步,加上一个 valid bit,用来表示该 cache block是否是合法的。
- 最开始的时候,cache 是空的,所以这个 bit 都是0.
- 当有数据被 load 到这个 block 的时候,这个 bit 就变成了1.
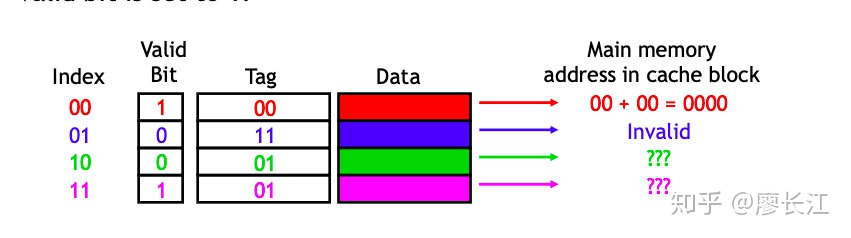
cache hit 的时候会发生什么?
我们已经知道该如何通过 main memory 的地址从 cache 中找数据了,如果正如我们所意,确实成功在 cache 中获取到了,这一段发生了什么呢?
当 CPU 需要从 memory 中read 数据的时候,地址会发送给 cache controller:
- address 的最低几位会对应到 cache 中的某个 block
- 如何 valid bit 是1,且tag 位是匹配的,就说明cache 成功 hit 了,就可以把data 返回给 CPU 了
如下图:
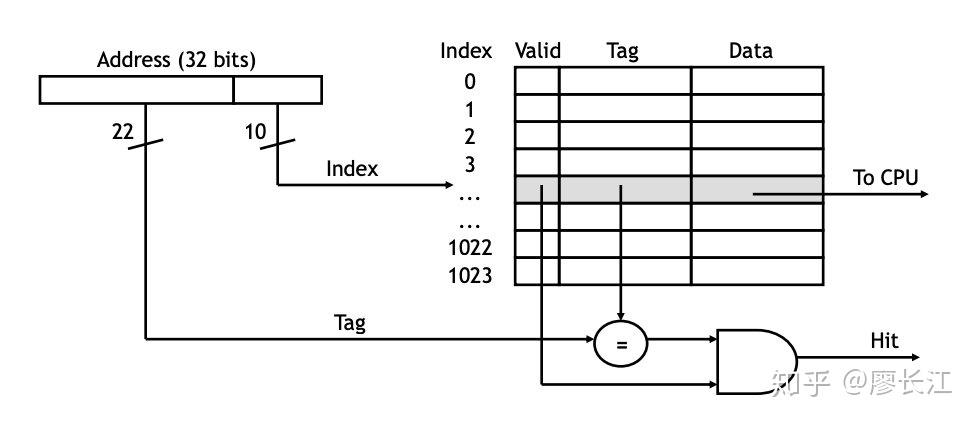
cache miss 的时候会发生什么?
CPU 从cache 中获取数据可以达到 ns 级,如果是 cache miss 了,就得先把main memory 的数据load 到 cache。 现在 data 已经从 main memory 中读取到了,通过以下步骤load 到 cache:
- 低位的 k 位指定了cache block的位置
- 高位的(m-k)位存在 cache block 的tag 位
- main memory 的 data 数据拷贝到 cache 的 data field
- 将 valid bit 置为1
如图:
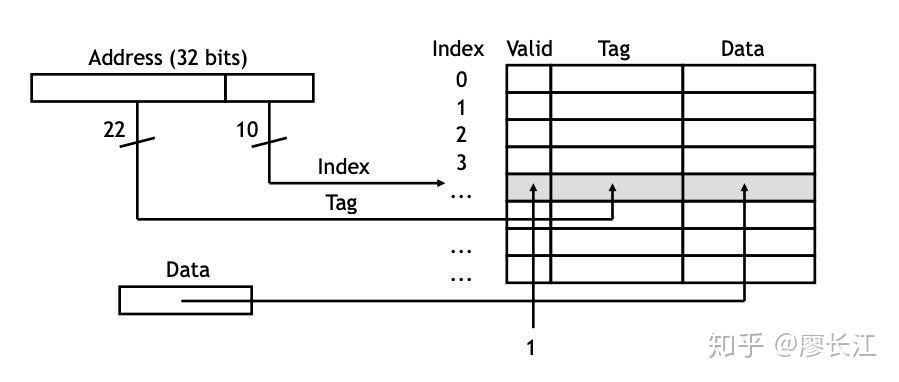
再讲讲cache miss
首先 cache miss 相比 cache hit 的性能差异是数量级的,应该尽可能减少 cache miss 的几率。cache miss 有很多种原因,这里讲最主要的两种,详细列表请看: https://en.wikipedia.org/wiki/Cacheperformancemeasurementandmetric
- 无法避免的 miss:所有的 cache 最开始肯定都是不在 cache 中的,所以这必然需要先从 main memory 中 load 进来。(除非试用 prefetch: https://en.wikipedia.org/wiki/Cache_prefetching )
- 冲突导致 miss:这种 miss 之前该数据已经在 cache 里面,但是被另外的程序抢占了。(回顾一下上篇文章讲的 last-level cache 竞争~这种可以通过调度来解决)
Spatial locality
前面都是一个 byte 为一个 block 的。我们有一个这样的假设,访问一个 address,下一次访问很有可能会访问临近的某一个 address。这个假设大多数情况下都是正确的。这个假设就叫做Spatial locality,那该如何实现这种假设?可以增加每个block的大小。
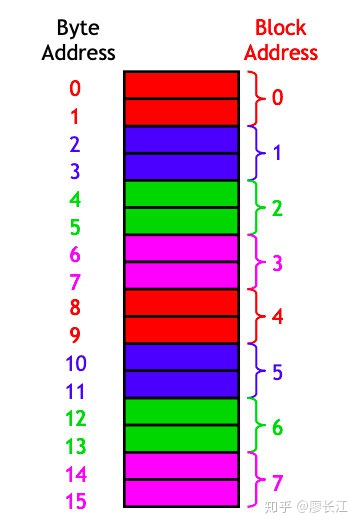
现在将每个 cache block 的大小设置为2个 bytes,于是我们就可以一次性 load 两个 bytes 的数据。当我们要 load 位置12的数据到 cache 的时候,同时也会把位置13的也 load 过去。
这时候,可以把 main memory 也划分成两个 byte 一个 block。byte address 和 block address 的对应关系也很简单,0和1对应一个 block address: 0。
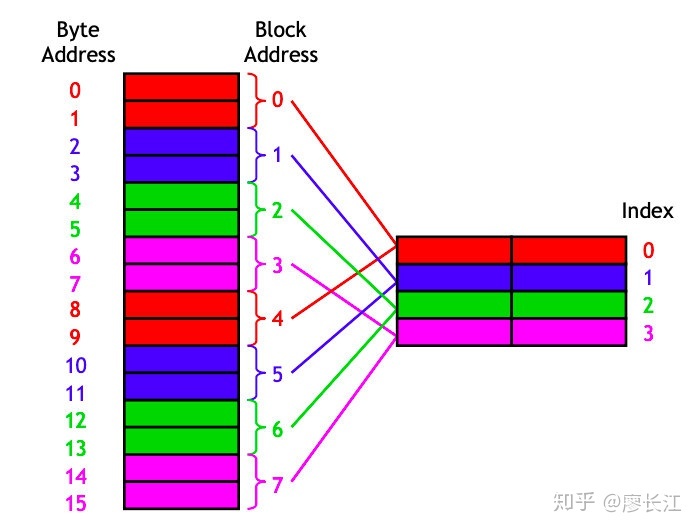
导入 cache 的过程也很之前一样,没什么好赘述的:现在从 main memory 中 load 第12或者第13个byte,都会同时12,13这两个 byte load 过去。
总结
Cache资源对于整个系统性能的影响巨大,关于如何设计 cache,调度 cache 资源的方法、论文层出不穷。此文讲的Direct Mapped Cache是最最简单的,但是对于我们理解 cache 有很大帮助。后面我们还会继续深入学习一下 cache。
最后,gakki 式求赞~


广告时间,欢迎大家关注我的微信公众号。同时本文同步于 github: https://github.com/liaochangjiang/TechDaily
















 5453
5453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









