





导读
我在《IN字段查询多少个值最合适?》中讲到:MySQL基于索引的查询成本分析主要包含两个方案:扫描索引树和索引统计。那么在这一章节中,我将详细讲解MySQL优化器是如何通过这两种方案,完成成本的分析的?
在讲解MySQL优化器如何完成查询成本分析之前,我们先明确一下查询成本是一个什么概念?
查询成本
在MySQL中的查询成本主要包含下面两部分:
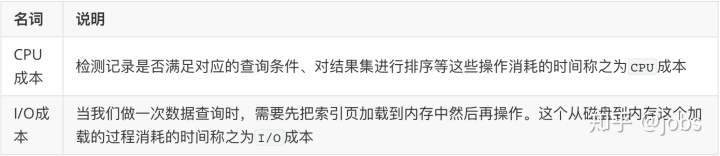
- CPU成本
检测记录是否满足对应的查询条件、对结果集进行排序等这些操作消耗的时间称之为CPU成本。
- I/O成本
当我们做一次数据查询时,需要先把索引页加载到内存中然后再操作。这个从磁盘到内存加载的过程消耗的时间称之为I/O成本。
MySQL中定义加载一条记录到内存花费的成本常数是1.0,即一条记录的I/O成本为1.0。检查一条记录是否满足查询条件的成本常数是0.2,即一条记录的CPU成本为0.2。
假设我们现在的用户中心系统有一个筛选功能,一个用户希望使用该功能筛选出年龄大于等于16,且小于25的用户,筛选结果按年龄升序展示,但是,由于表中满足条件的记录太多,为了保证查询性能,该功能采用分页的方式展示满足条件的用户。
很明显,我们发现上面这个筛选功能,我们可以使用下面这条SQL实现:
SELECT * FROM user WHERE age >= 16 AND age < 25 ORDER BY age LIMIT 0, 20那么,今天我就结合上面这个例子,讲解一下MySQL优化器是如何通过扫描索引树和索引统计两种方案,完成查询成本分析的?
在思考这个问题的时候,我们首先会想到,咦?MySQL优化器在做查询成本分析时,不可能两种方案都使用吧,因为这两种方案都是用来做成本分析的,互斥啊!所以,这里,我们就先结合上面的SQL,来看下MySQL优化器在什么情况下使用扫描索引树的方案,什么情况下,采用索引统计的方案?
这个问题,我在《IN字段查询多少个值最合适?》这一章中有讲过,这里,我在提一下:在MySQL中有一个配置参数eq_range_index_dive_limit,它的作用如下:
- 如果一个字段的查询条件是一个等值查询(比如:in查询,=查询),其等值条件数大于等于该配置参数,则查询成本分析使用索引统计的方式完成。
- 如果一个字段的查询条件是非等值范围查询或者是等值查询,其中,是等值查询时,等值条件数小于该配置参数,那么,这个范围查询和等值查询的查询成本分析使用扫描索引树的方式完成。
现在我们建一个索引:
index_age_birth:该索引是一个辅助索引,其中,第一个列是age,第二个是birthday。
结合eq_range_index_dive_limit的作用,我们可以判断,上面的这条SQL中:
age >= 16 AND age < 25为非等值范围查询,所以,使用扫描index_age_birth索引树的方式分析查询成本。
基于扫描索引树的分析
现在我就结合age >= 16 AND age < 25这个查询条件,以及索引树index_age_birth,讲解MySQL优化器是如何扫描索引树,完成查询成本分析的。
这里有两个概念,我先说明一下:
- 条件区间下限:指一个范围查询的最左条件,比如,上面条件
age >= 16 AND age < 25中的16。 - 条件区间上限:指一个范围查询的最右条件,比如,上面条件
age >= 16 AND age < 25中的25。
所以,这里,我把age >= 16 AND age < 25转化为[16,25),其中[表示>=,即包含16,)表示<,即不包含25,这样更直观一些。
下面,我们来看下这张图:

- 见图中蓝色箭头,结合我分别在《为什么MySQL能够支撑千万数据规模的快速查询?》及《InnoDB是顺序查找B-Tree叶子节点的吗?》中讲到的辅助索引的查找和基于槽的叶子节点搜索,我们可以很快定位到满足
age >= 16这个条件的第一条记录,即页5中的<16, 2007-06-06, 6>。 - 同理,见图中红色箭头,我们可以定位到满足
age < 25这个条件的最后一条记录,即页7中的<18, 2005-03-05, 4>。 - 根据以下规则计算
[16,25)这个条件区间的记录个数:
(1) 从条件区间内的第一条记录开始向后遍历记录,采样遍历np个叶子节点后,计算遍历记录的总数nr。这里分两种情况:
a. 如果遍历叶子节点个数小于等于np,则遍历记录总数就是条件区间内的记录数。
b. 如果遍历叶子节点个数大于np,用nr/np得出平均每个叶子节点包含的记录数pr。其中,在MySQL5.7.21中,这个采样遍历叶子节点数为10。
(2) 计算在条件区间内的所有叶子节点数ap,用ap*pr得出所有在条件区间内的记录数。其中,
假设我们把满足条件区间下限的记录所在的叶子节点的父节点叫p1,把满足条件区间上限的记录所在的叶子节点的父节点叫p2,那么,ap分以下两种情况计算得到:
a. 如果p1 == p2,统计途径p1内的记录到途径p2内的记录之间的记录数,该记录数即为ap。
b. 如果p1 <> p2,上推p1的父节点pp1和p2的父节点pp2:
b1. 如果pp1 == pp2,执行步骤a。
b2. 如果pp1 <> pp2,递归执行步骤b,直到pp1 == pp2,执行步骤a,结束。
- 结合上面的规则(1),见图中黄色箭头,优化器从满足
[16,25)区间内的第一条记录开始向右遍历记录,只遍历2个叶子节点,即页5和页6。ps:我这里为了更完整地表现成本分析流程,所以,设定遍历叶子节点数为2。 - 同样,结合上面的规则(1),通过采样遍历叶子节点中的记录,得到遍历的记录数nr,即图中的
2 + 2 = 4,用nr/遍历的叶子节点数,即4/2=2,得出平均每个叶子节点包含的记录数pr为2。 - 由于第1和2步骤定位到的记录分别在两个不同的叶子节点,所以,结合上面的规则b2,上推,分别找到它们所在叶子节点的父节点,即图中的页2和页3。
- 由于页2和页3也是两个不同的节点,结合上面的规则b2,继续上推,找到它们共同的父节点,即图中的页1。结合上面的规则b1,假设我们把页2的父节点叫做p1,页3的父节点叫做p2,然后,看图中蓝色箭头,由于途径p1的记录为页1中的<15, 2008-02-03, 2>,看图中红色箭头,途径p2的的记录为页1中的<17, 2006-03-03, 3>,统计这两条记录之间的记录个数为2,即规则(2)中的
ap。 - 所以,结合上面的规则(2),已知
ap和pr,所以,[16,25)区间内的记录数:2 * 2 = 4。 - 计算成本如下:
CPU成本
由于[16,25)区间内的记录数为4,所以,结合本章《导读》中CPU成本的概念,计算CPU成本如下:
4 * 0.2 + 0.01 + 4 * 0.2 = 1.61
(在辅助索引中搜索满足查询条件的记录的总成本 + 微调参数 + 在聚簇索引中搜索满足查询条件的记录的总成本)
其中,补充说明如下:
- 0.01为MySQL对CPU成本的微调参数。
- 聚簇索引中搜索满足查询条件的记录的总成本:由于在辅助索引中搜索满足查询条件的记录数为4,所以,结合《IN字段查询多少个值最合适?》中讲过的MRR过程,在聚簇索引中满足查询条件的记录数也为4。
I/O成本
1.0 + 4 * 1.0 = 5.0
(范围区间的数量 + 聚簇索引中满足条件的记录的加载成本)
其中,补充说明如下:
- 范围区间的数量:由于MySQL在做索引树扫描分析前,需要读取查询条件到内存中,再做分析,所以,该案例中,在扫描
index_age_birth索引树,需要读取一次条件区间[16,25)的上下限到内存中,这个读取次数就叫做范围区间的数量。
最终,[16,25)的查询总成本为CPU成本 + I/O成本:
`1.61 + 5.0 = 6.61 `基于索引统计的分析
在本章《导读》中,我讲到如果一个字段的查询条件是一个等值查询(比如:in查询,=查询),其等值条件数大于等于eq_range_index_dive_limit,则优化器使用索引统计的方式分析查询成本。
以用户表user为例,我们最常用的可能超过eq_range_index_dive_limit的查询语句如下,其中,id字段值个数超过eq_range_index_dive_limit,为300个:
SELECT * FROM user WHERE id IN (1, 5, 3, ..., 2)那么,我就以这条SQL为例,讲解一下MySQL优化器是如何基于索引统计完成查询分析的?
其实,MySQL维护了一个索引统计表,该表记录了每个索引包含的列的统计数据,我们可以使用如下SQL查看这张统计表:
SHOW INDEX FROM user表如下:

这里面有很多列,我们主要关注Cardinality这一列,它表示索引列中不重复值的数量。
假设我们定义user表的总记录数为total_rows,某一个索引列的Cardinality值为cardinality,那么,我们可以计算出平均一个值在该列重复多少次。即
一个值的重复次数 ≈ total_rows/cardinality
那么,案例中的SQL是主键id查询,一定命中主键索引,即表格中的聚簇索引PRIMARY,结合上面的公式,假设user表中包含记录数为8,我们就可以得出平均一个值在id这一列重复的次数,即
8/8 = 1
案例SQL中的查询条件id值的个数为300,那么,结合本章《导读》中查询成本的概念,这条SQL查询成本估算如下:
I/O成本
300 * 1.0 = 300
CPU成本
300 * 0.2 = 60
总成本
300 + 60 = 360
最后,你可能有个疑问:这些索引统计数据是怎么写到上面这张表中的呢?这个我会在《我们可以让InnoDB统计数据更精准吗?》中详细讲解。
总结
本章主要讲解了两部分内容:
- 查询成本
- 基于索引的查询成本分析

最后,希望喜欢我的文章的小伙伴,复制下方链接:
《看透MySQL》星球
粘贴到微信中打开,即可加入我的星球,获取更多精彩内容~














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









