





友情提示,本文略长,建议收藏后慢慢看!
今天是七夕节,祝大家节日快乐!
每到这一天,不少男生就开始犯愁(单身狗除外):该给女朋友送什么礼物呢?
思来想去,我决定送一个口红,一来口红属于化妆品,深受女生欢迎,二来口红在化妆品的领域中,属于物美价廉的一种品类,对于囊中羞涩的我来说,非常合适。
但是网上那么多口红,到底哪一种更适合我送女朋友呢,我决定通过python爬一下京东,进行数据分析。首先爬取各个口红的交易信息,进行筛选;之后选定某种口红之后,爬取其评论信息并进行文本分析。
京东口红商品信息分析
我决定使用selenium这个爬虫神器来抓取京东的商品信息,其基本用法我之前文章提到过:一文搞懂爬虫神器selenium常见操作
限于篇幅,爬虫代码只给出主要部分,感兴趣的朋友可以私信我领取。
为了对口红商品进行分析,我爬取了商品名称、商品价格、商品评价人数、店铺名称、商品的标签(如自营、放心购等标签):
def get_product(): lis = driver.find_elements_by_xpath('//ul[@class="gl-warp clearfix"]/li/div[@class="gl-i-wrap"]') for li in lis: info = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]').text #商品的名称 price = li.find_element_by_xpath('.//div[@class="p-price"]').text + '元' #商品的价格 comments = li.find_element_by_xpath('.//div[@class="p-commit"]').text #商品的评价人数 name = li.find_element_by_xpath('.//div[@class="p-shop"]').text #商品的店铺名称 icons = li.find_element_by_xpath('.//div[@class="p-icons"]').text #商品的标签 print(info,price,comments,name,icons,sep='|') with open ('data.csv',mode='a',newline='') as filecsv: csvwriter = csv.writer(filecsv,delimiter=',') csvwriter.writerow([info,price,comments,name,icons])主函数,爬取100页数据,每页30个,总计3000条商品数据:
def main(): page = 101 page_num = 1 while page_num != page: print('*' * 100) print('正在爬取第{}页的数据'.format(page_num)) print('*' * 100)#网页地址可以自己找规律,keyword后面是商品名称,page后边是页数,第1页是1,第2页是3,第3页是5,以此类推 driver.get('https://search.jd.com/Search?keyword={}&qrst=1&wq=%E5%8F%A3%E7%BA%A2&stock=1&page={}&click=0'.format(keyword,2*page_num-1)) driver.implicitly_wait(10) #隐式等待时间 get_product() page_num += 1 time.sleep(5)开始爬取数据:
花了十几分钟,爬取成功。保存成csv文件,一共3000条数据:
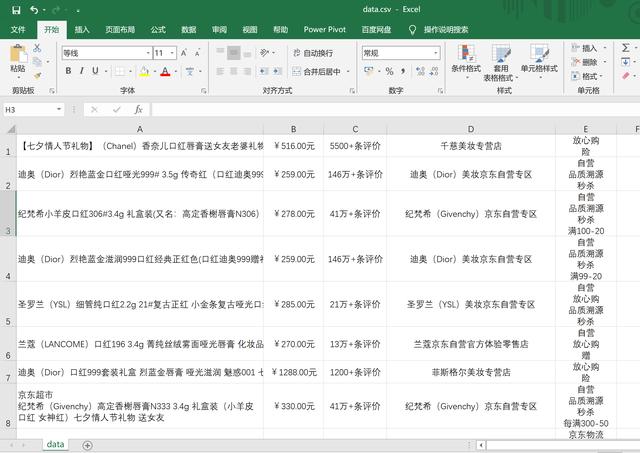
数据爬取完成后,为了方便数据分析,下面开始数据清洗。
我先通过excel来进行简单的清洗,如图所示,红圈里的这些单位比较多余,对后续数据分析会有影响,所以需要去除:
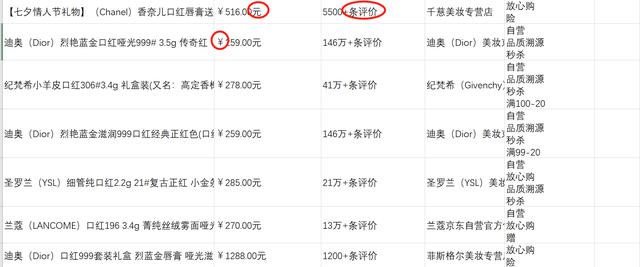
如图所示,点击右上角 查找和选择--替换,就可以将需要处理的文本替换掉:
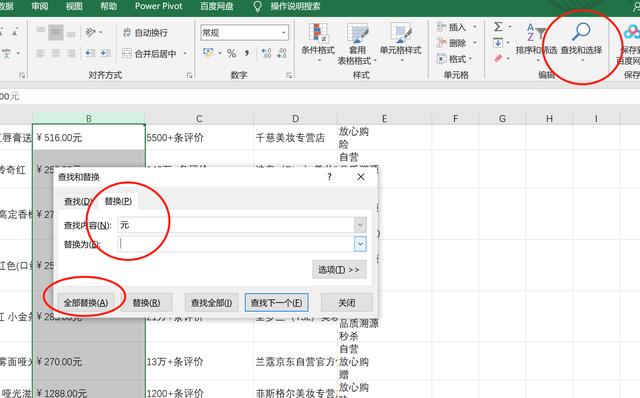
替换之后如下所示:
接下来通过python进行进一步清洗:
1.首先是读取数据
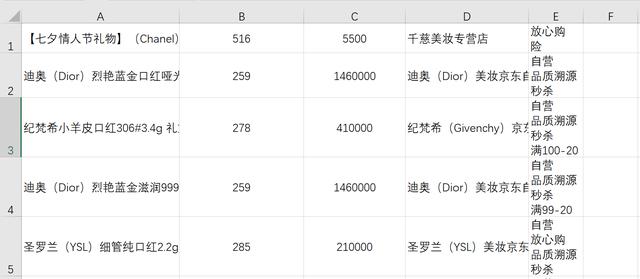
import pandas as pdimport numpy as np# 读取数据df = pd.read_csv('data.csv',header=None,encoding='gbk',names=['商品名称','商品价格','评价人数','店铺名称','商品标签'])2.预览数据

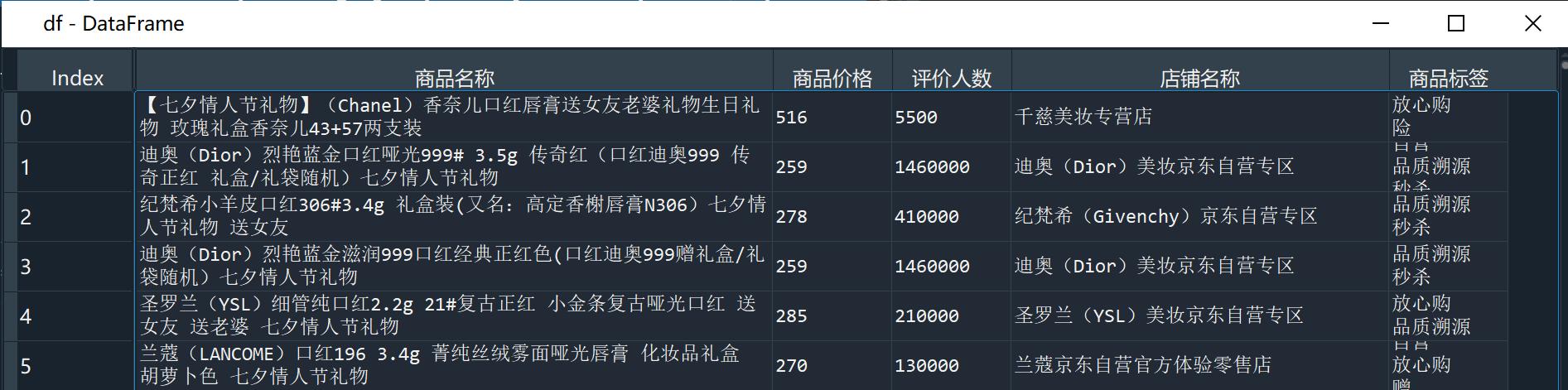
3.去除重复数据
# 去重df = df.drop_duplicates()
去重后还剩2959条数据
打开df,发现部分商品具有多个价格:
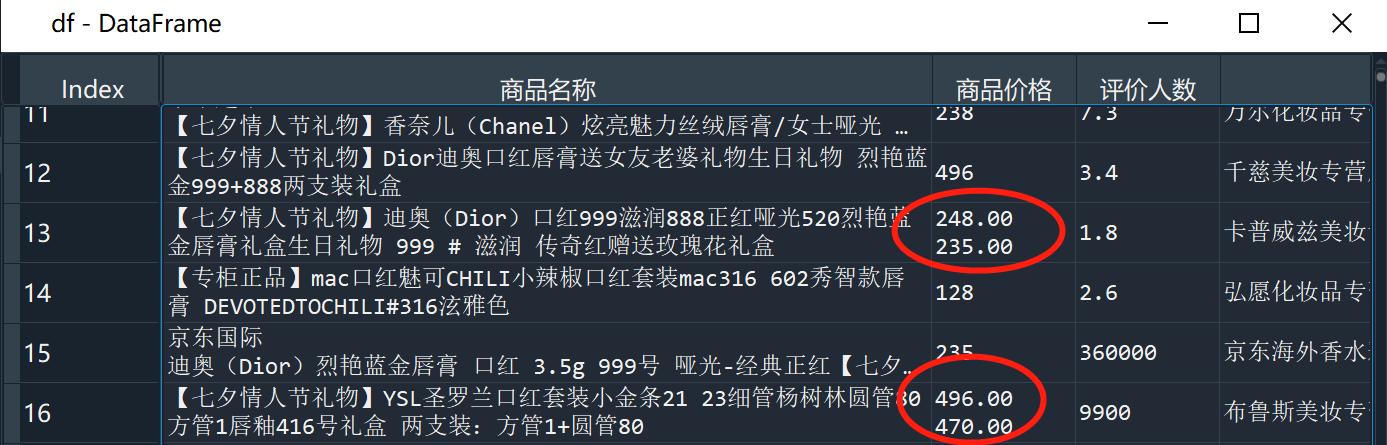
这里可以通过jieba分词,选取第一个价格作为这个商品的价格,之后将价格转化为浮点型,便于后续处理:
import jiebafor i in range(0,3000): try: df['商品价格'][i] = jieba.lcut(df['商品价格'][i])[0] df['商品价格'][i] = float(df['商品价格'][i]) except: pass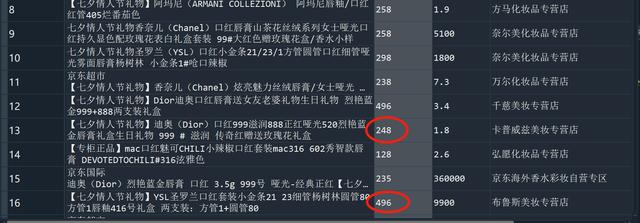
处理之后的数据
将评价人数也转换为浮点型数据:
# 将评价人数转换为浮点型for i in range(0,3000): try: df['评价人数'][i] = float(df['评价人数'][i]) except: pass 4.缺失值处理
# 查看数据信息df.info()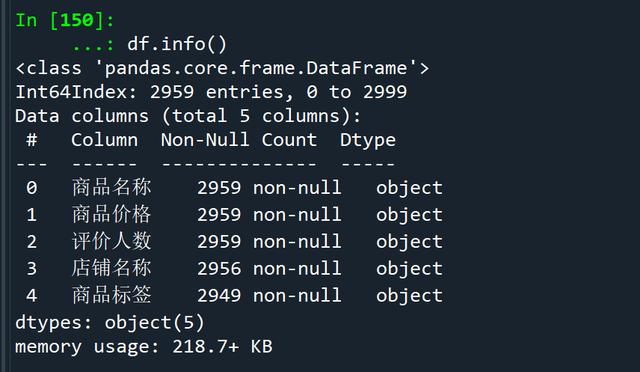
缺失值处理前
# 发现店铺名称有缺失值,删除含有缺失值的行# 其实商品标签也有缺失值,但是对于后面的分析影响不大,所以不用管df.dropna(axis=0,how='any',inplace=True,subset=['店铺名称'])# 查看删除含有缺失值的行后的数据信息df.info()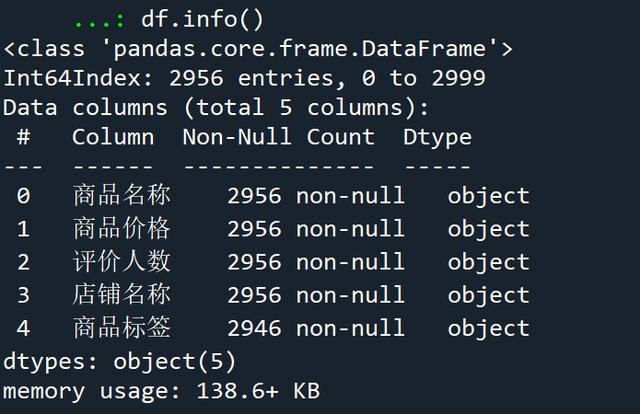
缺失值处理后
5.商品价格字段处理
# 商品价格字段切分listBins = [0,50,100,200,300,400,500,1000,10000]listLabels = ['50及以下','51-100','101-200','201-300','301-400','401-500','501-1000','1000及以上']'''pandas.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False)x:需要切分的数据bins:切分区域right:是否包含右端点,默认True,包含labels:对应标签,用标记来代替返回的bins,若不在该序列中,则返回NaNretbins:是否返回间距binsprecision:精度include_lowest:是否包含左端点,默认False,不包含'''# 利用pd.cut进行数据离散化切分df['价格区间'] = pd.cut(df['商品价格'],bins=listBins,labels=listLabels,include_lowest=True)6.重置索引
# 重置索引df = df.reset_index(drop=True)df.to_csv('京东口红清洗后数据.csv',index=None)数据清洗完毕,接下来进行数据分析。
作为消费者,除了商品质量,价格也是十分重要的参考因素,下面来看一下京东上销售的口红价格分布(注意因为临近七夕,所以不少口红都打折了,所以严谨的说这个分布只适用于七夕等折扣力度比较大的节日):
# 为了方便后续数据处理,我清空了之前的记录,重新读取数据import pandas as pdimport numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # 数据清洗df = pd.read_csv('京东口红清洗后数据.csv')df.drop(['商品价格','评价人数','店铺名称','商品标签'],axis=1, inplace=True)df2 = df.groupby(df['价格区间']).count()df2 = df2.rename(columns={'商品名称':'商品分布'})df2 = df2.sort_values(by=['商品分布'],ascending=False)# 注意这里的pyecharts最好是0.5.11版本,如果没有的话需要删了以前的,重新下载。否则会报错from pyecharts import Pielabels=df2.indexX=df2['商品分布']pie = Pie('京东口红价格分布')pie.add('',labels,X,is_label_show=True,legend_orient="vertical",legend_pos="right")pie.render('京东口红价格分布饼图.html')如图所示,京东的口红,价格位于201-300元的数量最多,其次是101-200元,再次是51-100元。这说明相对于其他的化妆品来说,口红属于比较经济实惠的品类,基本都分布在51-300元(当然这也有七夕打折的因素,以迪奥999为例,平时价格在330,七夕打折是270元),其次说明随着消费升级,高端化妆品还是占据着美妆市场的主流,201-300的价格其实也并不便宜,但是仍然占据着口红商品价格分布的第一位。
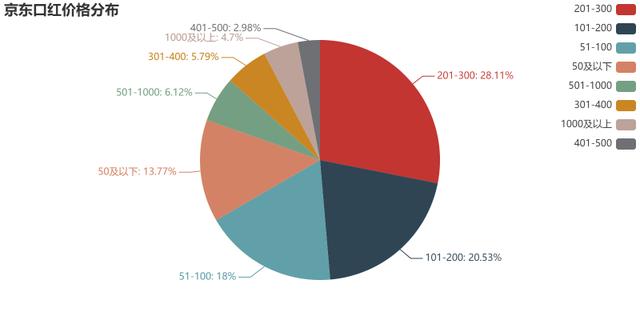
京东口红价格分布饼图
商品的价格分布只能反映商品的供给情况,消费者买不买账可是两码事,比如虽然51-300元的商品数量多,但是买的人少,人们倾向于买50元以下的或者300元以上的口红呢?
所以还要结合商品的销售情况去分析,因为京东的网页不显示购买人数,只显示评价人数,而爬虫是“可见即可爬”,不可见当然爬不了。不过评价人数也和购买人数有一定的联系,毕竟只有购买了商品才能进行评价,同理评价人数多的商品一定是热门的。所以下一步我将分析口红的评价人数与价格分布的关系,看看消费者更喜欢哪个价格区间的口红。
# 为了方便后续数据处理,我清空了之前的记录,重新读取数据import pandas as pdimport numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # 数据清洗df = pd.read_csv('京东口红清洗后数据.csv')# 对于某些京东卖家,许多不同的口红其实评价人数是被归到一起的,比如迪奥的不同口红,评价人数都显示146万,所以需要去重df.drop_duplicates(subset=['评价人数'], keep='first', inplace=True)# 评价人数这一列,部分数据不是纯数字,需要清洗for i in range(0,3000): try: df['评价人数'][i] = df['评价人数'][i].replace('条评价','') except: pass# 将评价人数转换为浮点型for i in range(0,3000): try: df['评价人数'][i] = float(df['评价人数'][i]) except: passdf.drop(['商品名称','商品价格','店铺名称','商品标签'],axis=1, inplace=True)# 利用groupby累加合并DataFrame数据中的重复行df = df.groupby(df['价格区间']).sum()df = df.sort_values(by=['评价人数'],ascending=False)from pyecharts import Pielabels=df.indexX=df['评价人数']pie = Pie('京东不同价格区间的口红评价人数占比')pie.add('',labels,X,is_label_show=True,legend_orient="vertical",legend_pos="right")pie.render('京东不同价格区间的口红评价人数占比.html')如图所示,消费者还是最青睐于201-300元的口红,毕竟对于大部分大牌口红,基本都是这个价格区间,比如迪奥,兰蔻,圣罗兰,雅诗兰黛,香奈儿等等(七夕节打折,平时要300多),其次0-50以下占据着第二名的份额,原因是这个价位大部分商品都是润唇膏,本身就比较便宜好卖,这里不太属于口红的范畴。再次就是101-200的价位也有不少消费者青睐。最后51-100的区间也有着13.19%的份额,完美日记的许多口红就在这个范围内,可能许多厂家看不上的市场,就成了完美日记弯道超车的机会。
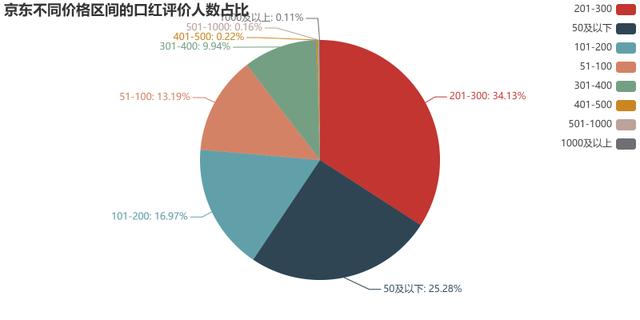
京东不同价格区间的口红评价人数占比饼图
下面看一看哪个店铺评价人数最多呢,可以用python来完成,代码和前面差不多。我这里使用Tableau来可视化,更方便:
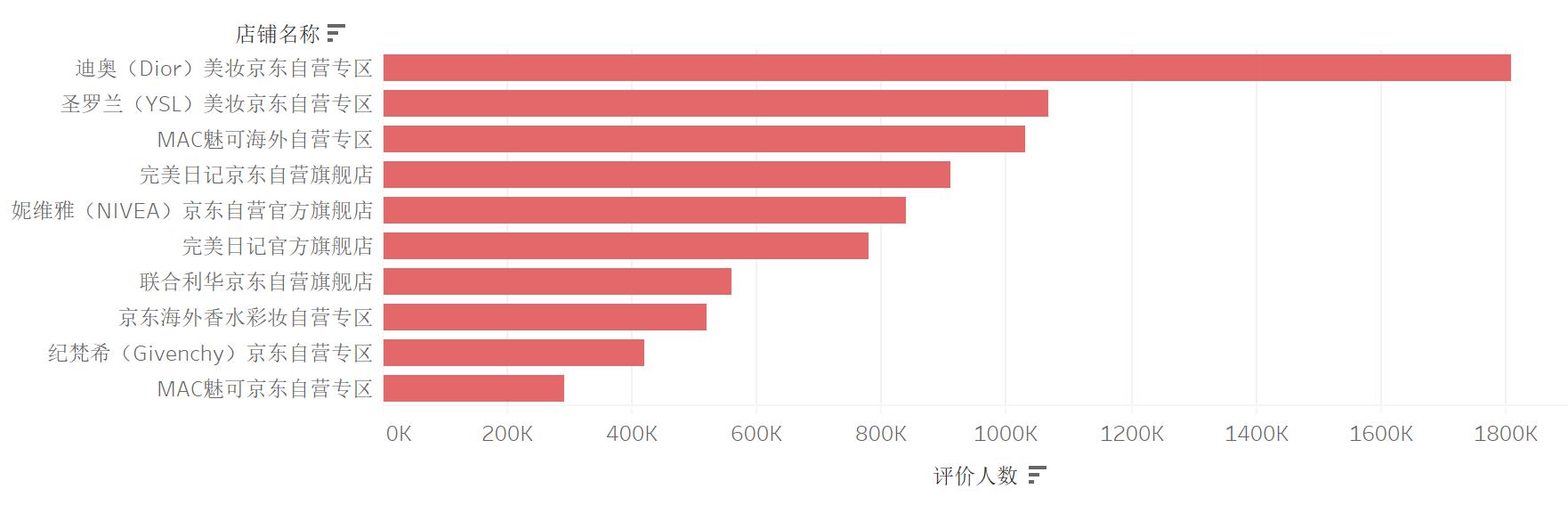
京东商城口红评价人数TOP10店铺
迪奥、圣罗兰、MAC这几家大品牌占据着前三的位置,而完美日记依靠着价格优势占据着2个位置,这说明在消费者心中,大品牌的口红是最为青睐的,毕竟相对于其它品类,比如动辄几千的包包,口红算是性价比高的了。其次就是有价格优势的国产口红,最近几年口红出现了不少“国货之光”,除了物美价廉以外,出发于小众市场的创新或许会令人眼前一亮,比如结合文创的故宫口红,专注国风的花西子口红。
因为商品名称里面经常会出现商品的特点,所以接下来对商品名称进行文本分析,先对字段进行切分,然后绘制词云图,关于词云图之前写过相关的教程,感兴趣的可以看看,限于篇幅这里我就不写代码了:「收藏向」Wordcloud词云图教程,从入门到精通
我将词云图写了个通用代码,基本上将数据和素材放在指定文件夹里就能一键生成想要的词云图,感兴趣可以私信我领取。
如图所示,可以看到口红基本都是当礼物送,词云中“礼物”、“情人节”、“七夕”、“生日”、“套装”、“礼盒”等词汇出现的频率较高,看来我选择口红作为七夕礼物还是很明智的呀,女孩子就喜欢这个。其次就是“保湿”、“滋润”出现的频率比较高,看来涂口红除了美感,消费者也在追求一种健康的生活方式,毕竟当天气干燥时,嘴唇干裂的感觉是比较难受的。词云右上角“女友”、“女士”等词汇也说明了口红还是女性用的比较多,所以李家琦作为男性推广口红反而会令人眼前一亮,最终凭借专业的职业素养成为口红一哥,不得不说李家琦涂口红还是很好看的,不知道未来会不会有更多的男性使用口红呢,感觉男性口红这个市场也是很有潜力。

京东口红商品名称词云图
京东迪奥口红商品评论:文本分析、情感分析、LDA主题分析
思来想去,我比较钟意迪奥的某款口红,因为迪奥是评价人数最多的店铺,同时也是国际知名品牌,再加上七夕节打折力度非常大,所以我把它列为首选。但是为了更好的了解它的质量怎么样,我决定对迪奥口红的商品评论进行文本分析,情感分析,并使用LDA主题模型进行主题分析。
首先需要爬取数据,限于篇幅,爬虫代码只给出主要部分,感兴趣的朋友可以私信我领取。
# 通过for循环获取更多页的评论texts=[]for n in range(0,100): url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006262957&score=1&sortType=5&page='+str(n)+'&pageSize=10&isShadowSku=0&fold=1' time.sleep(5) try: data = requests.get(url, headers=headers).text # 正则表达式解析内容 pat = re.compile('"content":"(.*?)","creationTime"') texts.extend(pat.findall(data)) print('已爬取第'+str(n+1)+'页') except: continue也可以参考我之前写的文章,原理是一样的:用Python爬取淘宝商品评论,看看辣条到底有多好吃
正在爬取中...
因为要进行情感分析和主题分析,所以评论最好是兼顾好评与差评,所以我爬取了100页好评与100页差评的数据,如图所示:

京东口红好评评论,共1000条
值得注意的是,对于差评,商家会在顾客评论下边回复,所以同样是一个页面,好评会有10个文本信息,但是差评会有20个文本信息(差评+商家回复),所以我爬了100页,差评却有接近2000条文本,所以需要把商家的回复清洗掉,通过观察可以发现,商家的回复基本上均包含“您好”、“亲爱的”、“您”这种表示尊敬的词语(而顾客的差评里基本没有这个词,毕竟打差评了心情肯定不会好),所以通过Excel的Ctrl+Shift+L可以将商家的回复筛选出来,删除即可。

京东口红差评评论,共1960条
将商家的回复删除后,正好剩下了1000条评论,说明基本清洗完毕。
之后人工打上情感标签,新建一列,命名为content_type,对于好评评论,标记为pos;对于差评评论,标记为neg(忽略实际给好评,但是评论是负向情感;忽略实际给差评,但是评论是正向情感的情况。因为很少见。)
将差评评论数据与好评评论数据合并在一起,形成最终的数据集,命名为“京东口红评论数据.xlsx”
接下来进行文本分析,首先导入各种第三方库:
import osimport pandas as pdimport reimport jieba.posseg as psgimport numpy as npimport matplotlib.pyplot as pltfrom wordcloud import WordCloudfrom collections import Counterfrom gensim import corpora,modelsimport itertoolsfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn import treefrom sklearn.metrics import classification_reportimport graphvizfrom sklearn.metrics import confusion_matrix读取文件:
raw_data = pd.read_excel('京东口红评论数据.xlsx')对评论进行去重:
reviews = raw_data.copy()print('去重之前:',reviews.shape[0])reviews = reviews.drop_duplicates()print('去重之后:',reviews.shape[0])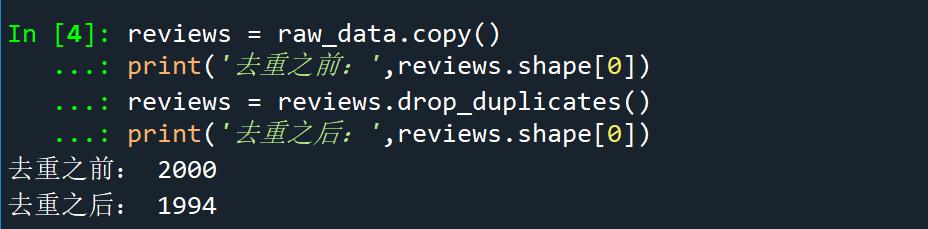
去重前与去重后的对比
进行数据清洗,通过正则表达式去除评论里的字母、数字、表情以及对文本分析无用的词汇:
# 清洗之前content = reviews['content']# 数据清洗info = re.compile('[^ -]|[0-9a-zA-Z]|口红|京东|迪奥')content = content.apply(lambda x:info.sub('',x))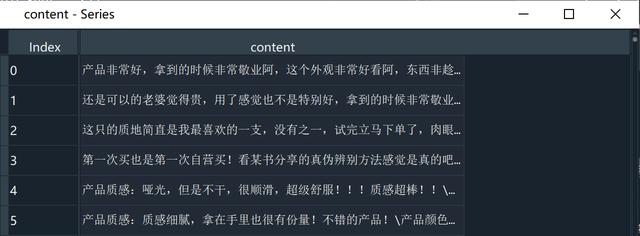
清洗后的评论
之后对评论进行分词,并通过jieba里的posseg模块标注词性:
# 分词并标注词性worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数seg_content = content.apply(worker)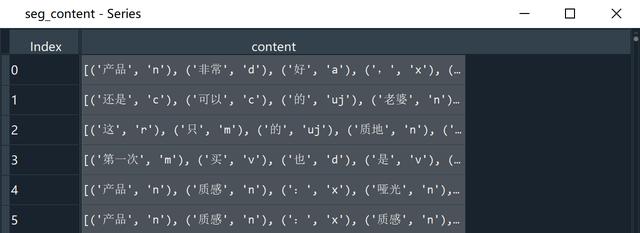
分词后的评论seg_content
统计一下评论词的个数:
# 统计评论词数n_word = seg_content.apply(lambda s:len(s))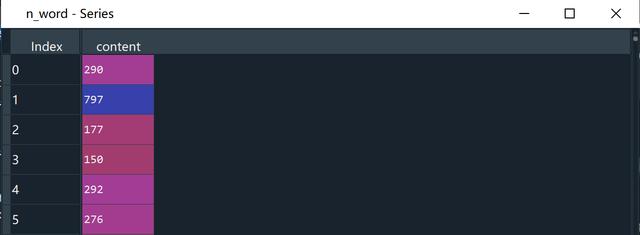
前六个句子的评论词数量
得到各分词在第几条评论:
# 得到各分词在第几条评论n_content = [ [x+1]*y for x,y in zip(list(seg_content.index),list(n_word))]index_content_long = sum(n_content,[])
n_content是一个列表,里面是1994个小列表

index_content_long是一个列表,包含144117条元素
index_content_long内部结构
对之前的seg_content去掉[],拉平:
# 分词及词性,去掉[],拉平seg_content_long = sum(seg_content,[])
将seg_content拉平后
# 得到加长版的分词,词性word_long = [x[0] for x in seg_content_long]nature_long = [x[1] for x in seg_content_long]将content_type拉长:
# content_type拉长n_content_type = [[x]*y for x,y in zip(list(reviews['content_type']),list(n_word))]content_type_long = sum(n_content_type,[])
n_content_type
content_type_long
新建一个dataframe,将"index_content","word","nature","content_type"作为列索引:
reviews_long = pd.DataFrame({'index_content':index_content_long, 'word':word_long, 'nature':nature_long, 'content_type':content_type_long})
reviews_long
值得注意的是,content_type为neg的词语的个数只有18070个,而词语一共有144117个,也就是说content_type为pos的词语有126047个,为什么同样1000条好评与1000条差评,正向情感的词汇数量会远远多于负向情感呢,其实看一下评论就知道了,大多数的好评字数都很多,动辄几百字,而差评基本都是几十个字,也可能是消费者没有耐心多写字去打差评,往往几句话抱怨一下,而好评则是精心编写,难道是写好评会有奖励?:
len(reviews_long[reviews_long['content_type'] == 'neg'])
情感标签为neg的词语的个数
好评基本上几百字,这是要写作文吗...
差评基本上都是几十个字
接下来进一步对reviews_long进行数据清洗,包括去除标点符号,去除停用词(比如“了”,“啊”,“吧”这种对于文本分析无用的词语),最终得到更干净的reviews_long_clean:
# 去除标点符号reviews_long_clean = reviews_long[reviews_long['nature']!='x']# 导入停用词 stop_path = open('stoplist.txt','r',encoding='utf-8')stop_words = stop_path.readlines()stop_words[0:5]# 停用词,预处理,去掉stop_words = [word.strip('') for word in stop_words]stop_words[0:5]# 得到不含停用词的分词表word_long_clean = list(set(word_long)-set(stop_words))reviews_long_clean = reviews_long_clean[reviews_long_clean['word'].isin(word_long_clean)]最后reviews_long_clean只剩下49388个词汇:

在reviews_long_clean中,再增加一列,表示该分词在本条评论的位置:
# 再次统计每条评论的分词数量n_word = reviews_long_clean.groupby('index_content').count()['word']index_word = [list(np.arange(1,x+1)) for x in list(n_word)]index_word_long = sum(index_word,[])len(index_word_long)reviews_long_clean['index_word'] = index_word_long将reviews_long_clean保存成csv文件:
reviews_long_clean.to_csv('1_review_long_clean.csv')经历了繁琐的数据处理过程,终于可以进入正题了,可想而知数据预处理在数据分析中是多么重要!
先来个开胃小菜,提取形容词,做一个词云图:
'''提取形容词'''a_reviews_long_clean = reviews_long_clean[['a' in nat for nat in reviews_long_clean.nature]]a_reviews_long_clean.nature.value_counts()a_reviews_long_clean.to_csv('1_a_reviews_long_clean.csv')'''词云图'''font = '微软雅黑 Light.ttc'background_image = plt.imread('pl.jpg')wordcloud = WordCloud(font_path=font,max_words=100,background_color='white',mask=background_image,colormap='Reds')wordcloud.generate_from_frequencies(Counter(a_reviews_long_clean.word.values))wordcloud.to_file('1_形容词_分词后的词云图.png')可以看出,迪奥的口红评论中,“持久”出现的频率比较高,这说明不容易掉色(作为直男可不可以这么理解...),其次就是“漂亮”、“精致”、“细腻”这些评价,感觉还是不错的。当然也有一些负面词汇,比如“假”、“真伪”,难道是质疑在京东上买到假货?接下来还需要进一步分析。

京东口红评论词云图_形容词
接下来通过机器学习构建一个决策树模型,通过有监督学习,来进行情感分类,预测某条评论属于好评(pos)还是差评(neg)。
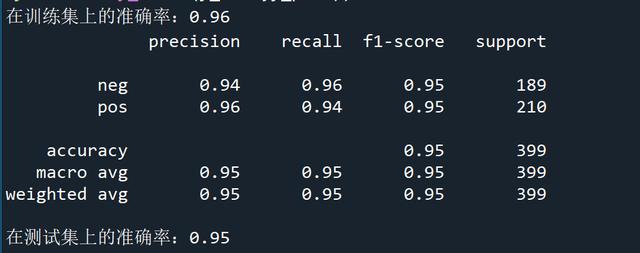
'''决策树'''# 第一步:构造特征工程和标签Y = []for ind in reviews_long_clean.index_content.unique(): y = [word for word in reviews_long_clean.content_type[reviews_long_clean.index_content==ind].unique()] Y.append(y)len(Y)X = []for ind in reviews_long_clean.index_content.unique(): term = [word for word in reviews_long_clean.word[reviews_long_clean.index_content==ind].values] X.append(' '.join(term))len(X)XY #第二步:训练集、测试集划分x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=7)#第三步:词转向量,01矩阵count_vec = CountVectorizer(binary=True)x_train = count_vec.fit_transform(x_train)x_test = count_vec.transform(x_test)#第四步:构建决策树dtc = tree.DecisionTreeClassifier(max_depth=5)dtc.fit(x_train,y_train)print('在训练集上的准确率:%.2f'%accuracy_score(y_train,dtc.predict(x_train)))y_true = y_testy_pred = dtc.predict(x_test)print(classification_report(y_true,y_pred))print('在测试集上的准确率:%.2f'%accuracy_score(y_true,y_pred))在训练集上的准确率为0.96,在测试集上的准确率为0.95,感觉还是可以的。
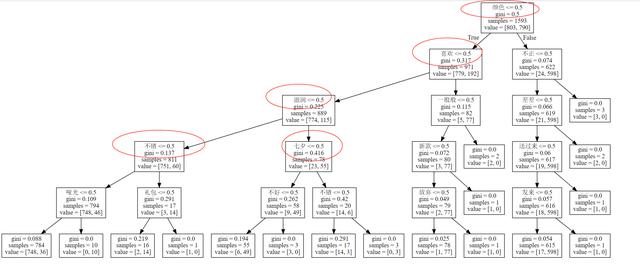
画决策树:
# 第五步:画决策树cwd = os.getcwd()dot_data = tree.export_graphviz(dtc, out_file=None, feature_names = count_vec.get_feature_names())graph = graphviz.Source(dot_data)graph.format='svg'graph.render(cwd+'/tree',view=True)graph可以看到“颜色”、“喜欢”、“滋润”、“七夕”、“不错”都是比较重要的词:
接下来进行情感分析,刚才的决策树是有监督的机器学习,我用的人工打的标签;而情感分析则是没有人工打的标签,属于无监督学习。那么如何通过无监督的手段得到情感标签呢?
首先导入评价情感词,它是知网发布的情感分析用词语集:
# 导入评价情感词# 读入正面、负面情感评价词pos_comment = pd.read_csv("正面评价词语(中文).txt", header=None,sep="", encoding = 'utf-8')neg_comment = pd.read_csv("负面评价词语(中文).txt", header=None,sep="", encoding = 'utf-8')pos_emotion = pd.read_csv("正面情感词语(中文).txt", header=None,sep="", encoding = 'utf-8')neg_emotion = pd.read_csv("负面情感词语(中文).txt", header=None,sep="", encoding = 'utf-8') # 合并情感词与评价词positive = pd.concat([pos_comment,pos_emotion],axis=0)negative = pd.concat([neg_comment,neg_emotion],axis=0)新建一列"weight",positive里的全部为1;negative里的全部为-1:
positive.columns = ['review']positive['weight'] = pd.Series([1]*len(positive))negative.columns = ['review']negative['weight'] = pd.Series([-1]*len(negative))将positive和negative合并:
pos_neg = pd.concat([positive,negative],axis=0)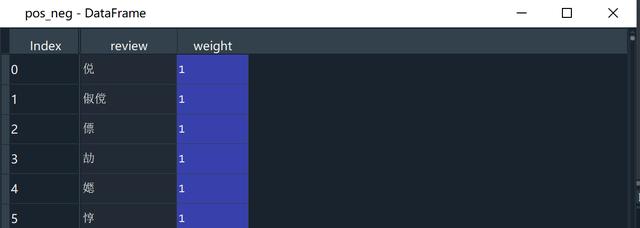
pos_neg中正向情感词权重为1,负向情感词权重为-1
# 合并到reviews_long_clean中data = reviews_long_clean.copy()reviews_mltype = pd.merge(data,pos_neg,how='left',left_on='word',right_on='review')reviews_mltype中review和weight这两列的空值用0填充,表示中性情感:
reviews_mltype = reviews_mltype.drop(['review'],axis=1)reviews_mltype = reviews_mltype.replace(np.nan,0)接下来修正情感倾向,因为否定词的存在,导致否定词所在的句子意思可能大不一样,比如:
“我喜欢吃榴莲”,前面如果有个“不”字,意思就截然相反:“我不喜欢吃榴莲”。
再加个否定词,“我不是不喜欢吃榴莲”,就负负得正了。
# 修正情感倾向# 如果有多重否定,那么奇数否定是否定,偶数否定是肯定notdict = pd.read_csv('not.csv')notdict['freq'] = [1]*len(notdict)# 准备一reviews_mltype['amend_weight'] = reviews_mltype['weight']reviews_mltype['id'] = np.arange(0,reviews_mltype.shape[0])# 准备二,只保留有情感词的行only_reviews_mltype = reviews_mltype[reviews_mltype['weight']!=0]only_reviews_mltype.index = np.arange(0,only_reviews_mltype.shape[0])# 看该情感词的前两个词,来判断否定的语气,如果在句首,则没有否词,如果在句子的第二个词,则看前一个词,来判断否定的语气index = only_reviews_mltype['id']for i in range(0,only_reviews_mltype.shape[0]): reviews_i = reviews_mltype[reviews_mltype['index_content']==only_reviews_mltype['index_content'][i]] #第i个情感词的评论 reviews_i.index = np.arange(0,reviews_i.shape[0]) # 重置索引后,索引值等价于index_word word_ind = only_reviews_mltype['index_word'][i] # 第i个情感值在该条评论的位置 # 第一种,在句首,则不用判断 # 第二种,在评论的第2个位置 if word_ind == 2: ne=sum([reviews_i['word'][word_ind-1] in notdict['term']]) if ne==1: reviews_mltype['amend_weight'][index[i]] = -(reviews_mltype['weight'][index[i]]) # 第三种,在评论的第2个位置以后 elif word_ind >2: ne = sum([word in notdict['term'] for word in reviews_i['word'][[word_ind-1,word_ind-2]] ]) if ne==1: reviews_mltype['amend_weight'][index[i]] = -(reviews_mltype['weight'][index[i]])reviews_mltype.shapereviews_mltype[(reviews_mltype['weight']-reviews_mltype['amend_weight'])!=0] # 说明两列值一样通过groupby得到每个句子的情感值,并保存成csv文件:
emotion_value = reviews_mltype.groupby('index_content',as_index=False)['amend_weight'].sum()emotion_value.to_csv('1_emotion.to_csv',index=True,header=True)筛选出具备情感倾向的句子:
# 每条评论的amend_weight总和不等于零content_emotion_value = emotion_value.copy()content_emotion_value.shapecontent_emotion_value = content_emotion_value[content_emotion_value['amend_weight']!=0]新增一列,句子的amend_weight大于0时标记为pos ; 句子的amend_weight小于0时标记为neg:
content_emotion_value['ml_type']=''content_emotion_value['ml_type'][content_emotion_value['amend_weight']>0]='pos'content_emotion_value['ml_type'][content_emotion_value['amend_weight']<0]='neg'将content_emotion_value与reviews_mltype合并,按照index_content链接,意味着如果某个句子是pos,则该句子的所有词语都打上pos标签,反之亦然(neg):
# 合并到大表当中content_emotion_value = content_emotion_value.drop(['amend_weight'],axis=1)reviews_mltype.shapereviews_mltype = pd.merge(reviews_mltype,content_emotion_value,how='left',left_on='index_content',right_on='index_content')reviews_mltype = reviews_mltype.drop(['id'],axis=1)reviews_mltype.to_csv('1_reviews_mltype.csv')之后通过混淆矩阵,检测情感分析的效果,看看机器标注的(ml_type)和人工标注的(content_type)有什么差异。关于混淆矩阵,可以看看我之前写的文章:“混淆矩阵”是什么?一个小例子告诉你答案
# 混淆矩阵cate = ['index_content','content_type','ml_type']data_type = reviews_mltype[cate].drop_duplicates()confusion_matrix = pd.crosstab(data_type['content_type'],data_type['ml_type'],margins=True)confusion_matrix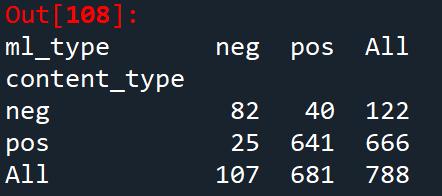
混淆矩阵
通过classification_report可以查看相比人工标注,机器标注的精确度:
data = data_type[['content_type','ml_type']]data = data.dropna(axis=0)print(classification_report(data['content_type'],data['ml_type']))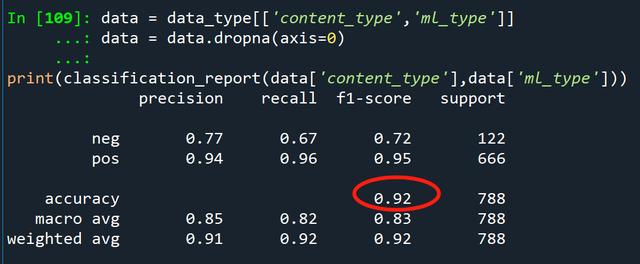
精确度0.92
接下来将正面情感词与负面情感词从评论中提取出来,分别绘制词云图:
'''词云图'''data = reviews_mltype.copy()data = data[data['amend_weight']!=0]word_data_pos = data[data['ml_type']=='pos']word_data_neg = data[data['ml_type']=='neg']import imageiofont = '微软雅黑 Light.ttc'picture = imageio.imread('kh4.png')w = WordCloud(font_path=font,max_words=100,background_color='white',mask=picture,colormap='Reds')w.generate_from_frequencies(Counter(word_data_pos.word.values))w.to_file('1_正面情感词词云图.png')正面情感出现最多的词是“喜欢”、“满意”、“信赖”说明在消费者心中对迪奥口红的品牌是非常认可的,收到迪奥口红作为礼物是比较满意的,最起码不容易踩雷。

京东迪奥口红评论正面情感词云图
看一下负面情感,可以发现“贵”的频率出现比较多,“高”也可以理解为价格“高”,说明在消费者心中迪奥的口红价格还是偏贵,“慢”可能体现了物流速度慢或者发货慢,“欺骗”可能是消费者遇到了质量问题,这些都是需要改进的地方。

京东迪奥口红评论负面情感词云图
最后进行LDA主题分析,之前也写过相关文章:LDA主题模型,希拉里邮件门文本分析
只不过那个例子是英文的,现在用中文的文本来实践一下。
首先需要建立词典和语料库:
# 基于LDA模型的主题分析# 优点:不需要人工调试,用相对少的迭代找到最优的主题结构'''建立词典、语料库'''data = reviews_mltype.copy()word_data_pos = data[data['ml_type']=='pos']word_data_neg = data[data['ml_type']=='neg']# 建立词典,去重pos_dict = corpora.Dictionary([[i] for i in word_data_pos.word]) # shape=(n,1)neg_dict = corpora.Dictionary([[i] for i in word_data_neg.word])print(pos_dict)# 建立语料库pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in word_data_pos.word]] #shape=(n,(2,1))neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in word_data_neg.word]]len(word_data_pos.word)len(pos_dict)len(pos_corpus)pos_corpus #元素是元组,元组(x,y),x是在词典中的位置,y是1表示存在构造主题数寻优函数,看看选多少主题比较合适:
'''主题数寻优'''# 构造主题数寻优函数def cos(vector1, vector2): dot_product = 0.0; normA = 0.0; normB = 0.0; for a,b in zip(vector1, vector2): dot_product += a*b normA += a**2 normB += b**2 if normA == 0.0 or normB==0.0: return(None) else: return(dot_product / ((normA*normB)**0.5)) # 主题数寻优# 这个函数可以重复调用,解决其他项目的问题def lda_k(x_corpus, x_dict): ''' 函数功能: ''' # 初始化平均余弦相似度 mean_similarity = [] mean_similarity.append(1) # 循环生成主题并计算主题间相似度 for i in np.arange(2,11): # LDA模型训练 lda = models.LdaModel(x_corpus, num_topics = i, id2word = x_dict) for j in np.arange(i): term = lda.show_topics(num_words = 50) # 提取各主题词 top_word = [] #shape=(i,50) for k in np.arange(i): top_word.append([''.join(re.findall('"(.*)"',i)) for i in term[k][1].split('+')]) # 列出所有词 # 构造词频向量 word = sum(top_word,[]) # 列出所有的词 unique_word = set(word) # 去除重复的词 # 构造主题词列表,行表示主题号,列表示各主题词 mat = [] #shape=(i,len(unique_word)) for j in np.arange(i): top_w = top_word[j] mat.append(tuple([top_w.count(k) for k in unique_word])) #统计list中元素的频次,返回元组 #两两组合,方法一 p = list(itertools.permutations(list(np.arange(i)),2)) #返回可迭代对象的所有数学全排列方式 l = len(p) #l=i*(i-1) top_similarity = [0] for w in np.arange(l): vector1 = mat[p[w][0]] vector2 = mat[p[w][1]] top_similarity.append(cos(vector1, vector2)) # 计算平均余弦相似度 mean_similarity.append(sum(top_similarity)/l) return(mean_similarity)计算主题平均余玄相似度:
#计算主题平均余玄相似度pos_k=lda_k(pos_corpus,pos_dict)neg_k=lda_k(neg_corpus,neg_dict)pos_kneg_k可视化余玄相似度:
# 不同主题下的余玄相似度pd.Series(pos_k,index=range(1,11)).plot()plt.title('正面评论LDA主题数寻优')plt.show()pd.Series(neg_k,index=range(1,11)).plot()plt.title('负面评论LDA主题数寻优')plt.show()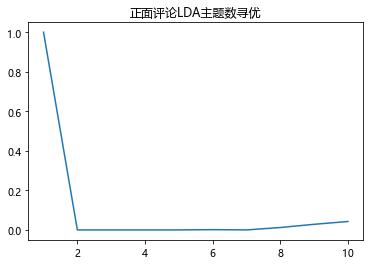
主题数为2时,余玄相似度最低,lda效果最好
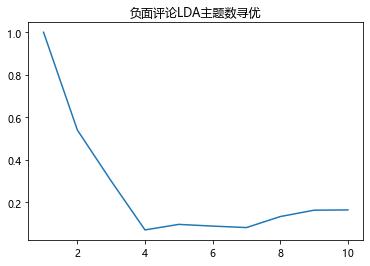
主题数为4时,余玄相似度最低,lda效果最好
训练模型:
pos_lda = models.LdaModel(pos_corpus,num_topics=2,id2word=pos_dict)neg_lda = models.LdaModel(neg_corpus,num_topics=4,id2word=neg_dict)输出结果:
pos_lda.print_topics(num_topics=10)neg_lda.print_topics(num_topics=10)看一下正面评论的lda主题模型输出结果,第一个主题的关键词有“喜欢”、“适合”、“包装”、“女朋友”等,可以看出,这个主题围绕着送礼物,比如“包装”可能比较精美,礼盒外观“好看”,可以看出迪奥口红用来送给女朋友作为礼物是比较合适的。第二个主题的关键词有“颜色”、“滋润”、“质感”、“持久”、“物流”等,可以看出,这个主题围绕着商品本身,比如“颜色”好看,使用口红会使嘴唇更加“滋润”,涂完之后比较“持久”,还有“物流”的效率比较高。

正面评论lda主题词
接下来看一下负面评论的lda主题模型输出结果,主题数比较多就不一一解释了,可以看出以下几个关键词反映了消费者的不满:
“贵”、“价格”可能反映出部分消费者仍觉得价格偏高,收到口红之后有一定的心理落差(比如发现效果和其它口红差不多的话,或者在购买之后商品降价了,我大体看了下最近几天的差评,确实不少消费者反映在购买没几天后,因为七夕活动导致商品大幅降价)
“差”、“辣鸡”、“划痕”、“质量”、“粘”、“不正”可能反映了商品质量出现了问题,比如出现了划痕,因为天气热所以口红有点融化,颜色不正等现象。
“包装”、“礼袋”可能是部分消费者不满意口红的包装。“客服”可能是消费者对于客服的服务不太满意,可能是服务态度不好或者是没有解决自己的问题。
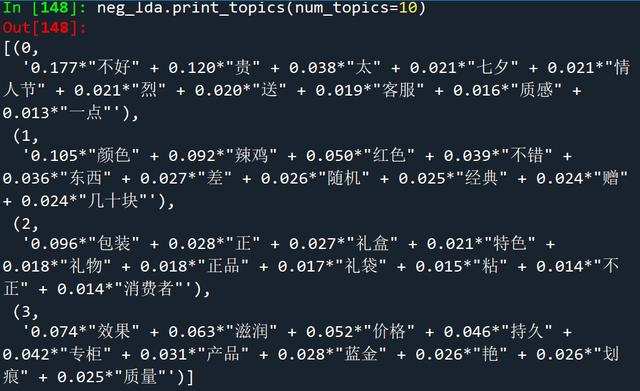
负面评论lda主题词
接下来可以将LDA模型的训练结果可视化,更方便我们去分析:
# 可视化模型训练结果import pyLDAvisimport gensimimport pyLDAvis.gensimvis = pyLDAvis.gensim.prepare(pos_lda,pos_corpus,pos_dict)#vis = pyLDAvis.gensim.prepare(neg_lda,neg_corpus,neg_dict)# 需要的三个参数都可以从硬盘读取的,前面已经存储下来了# 在浏览器中心打开一个界面pyLDAvis.show(vis)# 在notebook的output cell中显示#pyLDAvis.display(vis)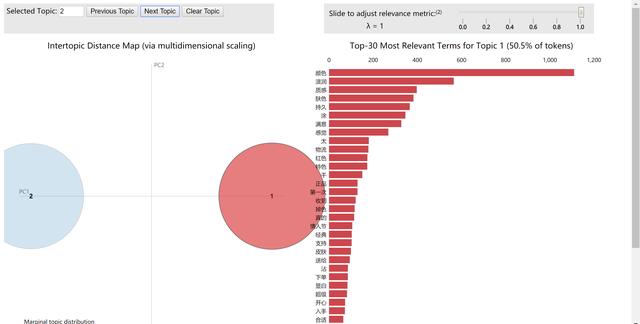
正面评论lda模型输出的某主题
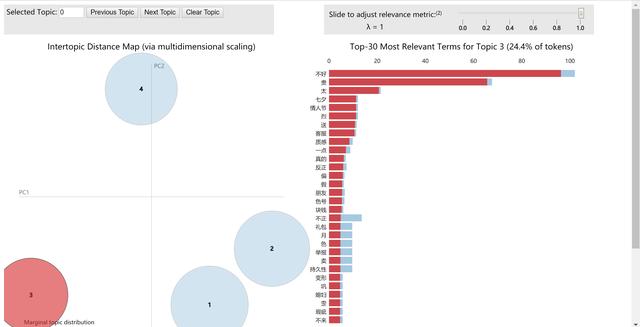
负面评论lda模型输出的某主题
经过几天不眠不休的努力,熬秃了头发,综合了各种因素,我终于下定决心买了支迪奥某色号的口红送给女朋友,她收到礼物果然十分开心。看来数据分析真的很重要啊!
后续我会继续更新数据分析相关的文章,欢迎关注。本文出现的数据集和素材都可以私信我领取,有什么问题也可以私信问我,大家一起在数据分析的道路上成长。
七夕节到了,祝愿大家节日快乐!祝有情人终成眷属!祝单身的朋友们早日找到自己的幸福!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









