






我们用 requests 库 + 正则表达式构建一个简陋的爬虫,虽然这个爬虫很简陋,但是通过这个例子我们可以对爬虫有一个很好的了解。
这次目的是爬取猫眼电影 TOP 100,要想爬取这些信息,我们首先要到猫眼电影 TOP 100 的页面上观察一下(也可以说踩点)。网址为:https://maoyan.com/board/4

这就是我们要爬取的页面,现在我们来写一段代码自动访问这个页面。
def get_one_pages(url) -> 'HTML':headers = { # 构建表头,模仿正常浏览器,防止被屏蔽'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常return response.textreturnNone
我们构造了 get_one_pages(url) 函数,在构造这个函数时要注意一定要加上表头,表头的作用是让爬虫伪装成一个正常的浏览器请求。如果不加表头的话,会被服务器拒绝访问(不信你就试一下)。之后当你调用这个函数并往里面传入 URL 也就是https://maoyan.com/board/4 时,该函数会把这个网页的 HTML 返回下来。HTML 算是网页的源代码,在 Chrome 浏览器中按下 F12 键就能看到源代码,发现返回的 HTML 与网页中的 HTML 一样,那么证明我们这个网页算是访问成功了。
下一步我们要解析这个网页,获取我们想要的内容。观察返回的 HTML 会发现,每一个电影的相关信息被一个 <dd> </dd> 标签包围。
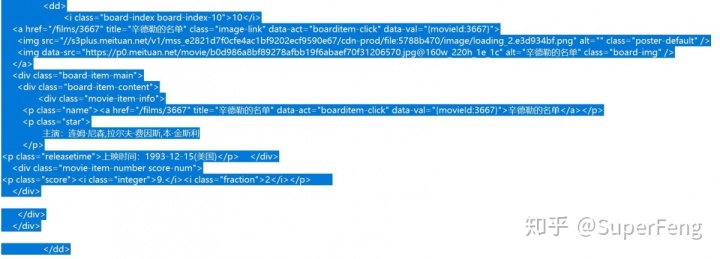
以这段标签为例,我们需要获取的内容有排名、电影海报、电影名称、演员和上映时间。这时该轮到正则表达式出场了。我们用正则表达式去匹配这段文本,来获取想要的信息,如果你现在还不知道什么是正则表达式,可以 Google 一下,正则表达式的内容很复杂,但这里我们用到的很简单,一搜就会。
下面是解析网页的代码:
def parse_one_page(html) -> list:pattern = re.compile('<dd>.*?>(.*?)</i>.*?<img src="(.*?)".*?title="(.*?)".*?<p class="star">(.*?)</p>.*?>(.*?)</p> ',re.S)res = re.findall(pattern, html)for i in res:yield { # 这里使用了生成器构造一个字典'index': i[0],'image': i[1],'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}
我们用 <dd>.*?>(.*?)</i>.*?<img src="(.*?)".*?title="(.*?)".*?<p class="star">(.*?)</p>.*?>(.*?)</p> 这段正则表达式来匹配想要的内容,然后将匹配的结果存入一个字典中,为了以后方便读取和保存。
下一步我们把爬到的内容保存下来,否则一旦关闭程序,所有爬取的内容就会消失,白忙一顿岂不是很难受。
def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + 'n')
我们用上下文管理器打开一个 txt 文件,将爬下来的内容写入这个文件中。
我们的目标是爬取猫眼电影 TOP 100,可是现在才爬到 TOP 10,那后面的怎么办呢?再来观察网页,我们看到,第11-20的URL为:https://maoyan.com/board/4?offset=10
第21-30的URL为:https://maoyan.com/board/4?offset=20 ,以此类推。。。
那么我们可以推断出来网页的变化只跟 offset= 后面数字有关,这样可以继续写代码了。
def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_pages(url)content = parse_one_page(html)for i in content:print(i)write_to_file(i)
这里写了一个 main(offset) 函数,传入相应的数字,会对相应的网页进行我们之前的操作。
最后一步,传入数字即可。总结一下最终的代码:
import requestsimport reimport jsondef get_one_pages(url) -> 'HTML':headers = { # 构建表头,模仿正常浏览器,防止被屏蔽'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'}response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常return response.textreturnNonedef parse_one_page(html) -> list:pattern = re.compile('<dd>.*?>(.*?)</i>.*?<img src="(.*?)".*?title="(.*?)".*?<p class="star">(.*?)</p>.*?>(.*?)</p> ',re.S)res = re.findall(pattern, html)for i in res:yield { # 这里使用了生成器构造一个字典'index': i[0],'image': i[1],'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + 'n')def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_pages(url)content = parse_one_page(html)for i in content:print(i)write_to_file(i)for i in range(10):main(i*10)
这样就可以将猫眼电影 TOP 100 爬取下来,并作为一个 txt 文件保存,我们来看看结果:

很不错,就是我们期待的结果。
通过这么一个简陋的爬虫程序,我们对爬虫已经有了一个大致的了解,如果想要爬取到更多有用的内容,仅仅这样还是远远不够的,希望你能在爬虫路上越爬越远。
以上内容素材来源于 崔庆才《Python 3网络爬虫开发实战》。
ps.如果想要打开新世界的大门,可以扫描下方的二维码,关注微信公众号「SuperFeng」。
















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









