





本文共 4524 字,预计阅读时间 19 分钟
* 好久没更新了,正当六一我还在愉快的过节时, 『@余弦』 (https://evilcos.me/) 大佬的团队就开源了他们的BadDNS,一个用Rust写的子域名探测工具。关于工具的设计思路和使用方法,可以直接去看它GitHub上的ReadMe,这里还是老规矩,带大家速读一遍源代码。
本文以工具本身的代码逻辑为主,一些涉及到的Rust语言基础和特性可能会简单带一带(毕竟Rust不像Go目前已经在圈内逐渐流行开了),但不会做过多的展开,感兴趣的小伙伴可以自行研究。 加载资源时间就是金钱,我们跳过打印Logo和命令行参数解析,直接上正餐。项目中最主要的资源就是目标列表、子域名字典和深度字典: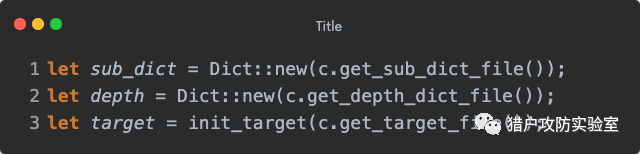 其中需要稍微解释一下的应该就只有深度字典了,它是用来判断某个子域名是否允许多层遍历的,可以简单看成是子域名字典的一个子集。子域名字典和深度字典的加载方式相同,都是读取文件数据放进定义好的结构体
Dict 中,这个结构体只有一个
Vector 类型的字段,大家可以把它理解成一个动态数组:
其中需要稍微解释一下的应该就只有深度字典了,它是用来判断某个子域名是否允许多层遍历的,可以简单看成是子域名字典的一个子集。子域名字典和深度字典的加载方式相同,都是读取文件数据放进定义好的结构体
Dict 中,这个结构体只有一个
Vector 类型的字段,大家可以把它理解成一个动态数组:
 可以看到Rust中有很多C++、Python、Go,甚至JavaScript(毕竟它的爸爸来自Mozilla)的影子,是一门很有意思也很有个性的语言,有一定语言基础的同学上手应该难度不大。
“
可以看到Rust中有很多C++、Python、Go,甚至JavaScript(毕竟它的爸爸来自Mozilla)的影子,是一门很有意思也很有个性的语言,有一定语言基础的同学上手应该难度不大。
“
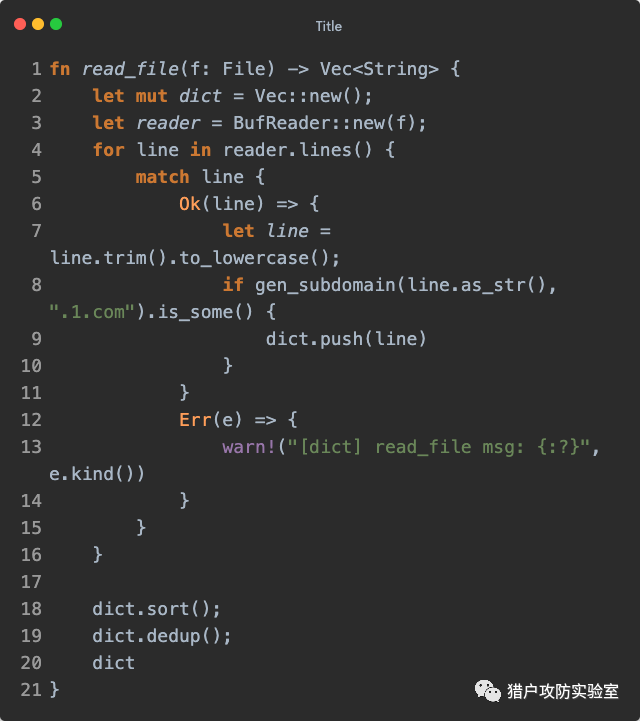
Rust语言小贴士:
1. Rust使用 impl 块来为结构体添加一些方法和函数(结构体方法的第一个参数一定是用于代指结构体实例本身的 self 或它的引用,相当于Java中的 this ,而结构体函数则不需要)
2. unwrap() 是Rust异常处理机制中的一种方式
 “
“
Rust语言小贴士:
1. Rust为了保证高并发安全,变量的值默认是不可变的(但与常量不一样),可以通过 mut 指定为一个『可变变量』
2. match 块是Rust中可恢复异常的处理方式之一,上述代码中的 line 是 Result 类型,可由 match 来匹配结果为 OK 或 Err
3. .is_some() 是用来判断是否不为空值的,Rust不支持 null ,标准库中有个 Option 枚举类型用于表示有值( Some )或空值( None )*
4. warn!() 存在一个感叹号,在Rust中代表它是一个『宏』而不是函数,常见的宏还有 println!() 等,也可以自己定义
5. 细心的同学应该会注意到,上述代码中的语句都是由 ; 结尾的,而最末尾作为返回值的语句后面却没有 ; ,同时也没有 return 关键字,这在Rust中叫做『表达式』,本身就可以直接作为返回值,当然,使用普通的 return sth; 也是可以的
 生成泛解析白名单泛解析白名单同样也是一个数组,由
wildcards_event() 函数处理:
生成泛解析白名单泛解析白名单同样也是一个数组,由
wildcards_event() 函数处理:
 “
“
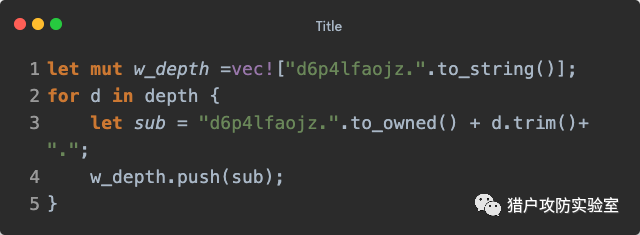
Rust语言小贴士:
1. Rust在内存管理中设计了一个比较有意思的机制,叫『所有权』,为了避免 target 和 depth 变量在作为参数传递后所有权发生转移导致提前被释放,因此可以通过 clone() 复制一份来使用
 创建一个Channel,并用第三方线程池库
pool-rs 创建一个指定大小(由
-w 参数决定,默认为
500 )的线程池:
创建一个Channel,并用第三方线程池库
pool-rs 创建一个指定大小(由
-w 参数决定,默认为
500 )的线程池:
 最后用
thread::spawn() 单独开启一个子线程,在其中遍历目标列表,对每个目标都用泛解析子域名集合构造理论上不存在的域名,交给线程池调用
query_wildcards() 查询,查询结果发送给Channel,在主线程中进行接收,放进最终的结果集里:
最后用
thread::spawn() 单独开启一个子线程,在其中遍历目标列表,对每个目标都用泛解析子域名集合构造理论上不存在的域名,交给线程池调用
query_wildcards() 查询,查询结果发送给Channel,在主线程中进行接收,放进最终的结果集里:
 “
“
Rust语言小贴士:
1. move 关键字可以在Rust中使用闭包时,强制闭包函数获得所有权,避免错误的使用变量等资源
2. Rust的Channel默认是多发单收的,从它的库名 mpsc (Multi Producer Single Consumer)也能看出来,在迭代接收时,当所有发送者被释放,迭代也会自动结束,而不需要像Go中那样显示的进行 close()
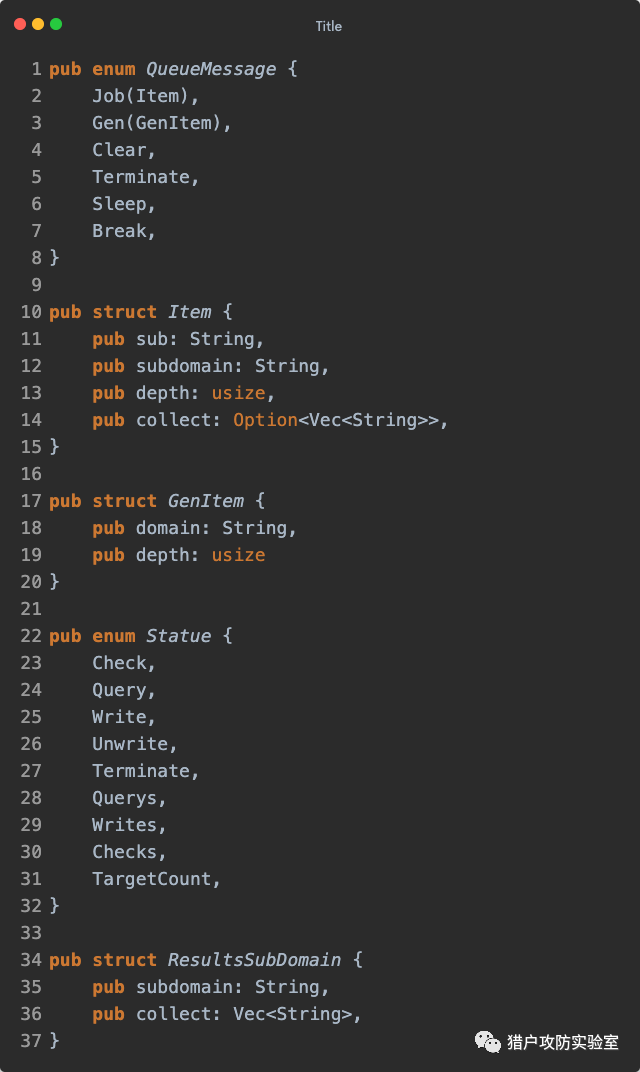
 头疼的小伙伴别着急,跟着我一起来捋一捋。先过一遍几个定义的枚举和结构体,大家心里留个印象。
QueueMessage 是『域名生成』、『查询』和『检查』用到的类型,
Statue 是『统计』用到的类型,
ResultsSubDomain 是『结果处理』用到的类型:
头疼的小伙伴别着急,跟着我一起来捋一捋。先过一遍几个定义的枚举和结构体,大家心里留个印象。
QueueMessage 是『域名生成』、『查询』和『检查』用到的类型,
Statue 是『统计』用到的类型,
ResultsSubDomain 是『结果处理』用到的类型:
 “
“
Rust语言小贴士:
1. Rust的枚举相对其他主流语言来说特性更丰富一些,它可以为每个枚举成员添加灵活多变的属性描述(如 Job 和 Gen )*
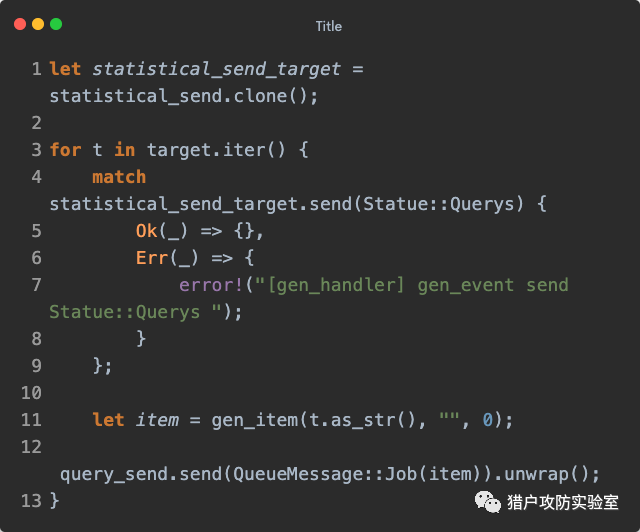 gen_item() 函数有域名、子域名和深度三个参数,会将域名和子域名进行拼接(注意
subdomain 是
sub.domain ,而非
sub ),封装成一个
Item 实例:
gen_item() 函数有域名、子域名和深度三个参数,会将域名和子域名进行拼接(注意
subdomain 是
sub.domain ,而非
sub ),封装成一个
Item 实例:
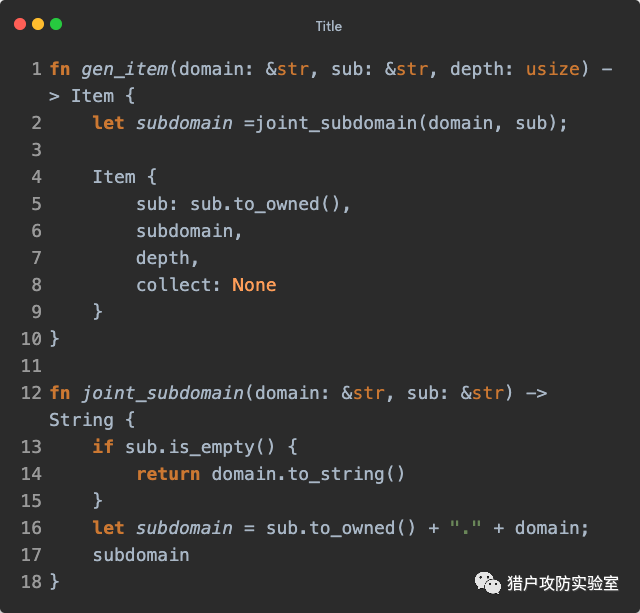 第二部分就开始迭代
gen_recv 接收消息,当收到消息类型为
QueueMessage::Gen 时,遍历子域名字典,先通过
supper() (它的逻辑与当前流程关联性不大,放后面再讲)判断当前内存占用量是否超过指定比例(由
-m 参数决定,默认为
50% ),是则休眠两秒,否则与上面一样依次给『统计』和『查询』发送消息:
第二部分就开始迭代
gen_recv 接收消息,当收到消息类型为
QueueMessage::Gen 时,遍历子域名字典,先通过
supper() (它的逻辑与当前流程关联性不大,放后面再讲)判断当前内存占用量是否超过指定比例(由
-m 参数决定,默认为
50% ),是则休眠两秒,否则与上面一样依次给『统计』和『查询』发送消息:
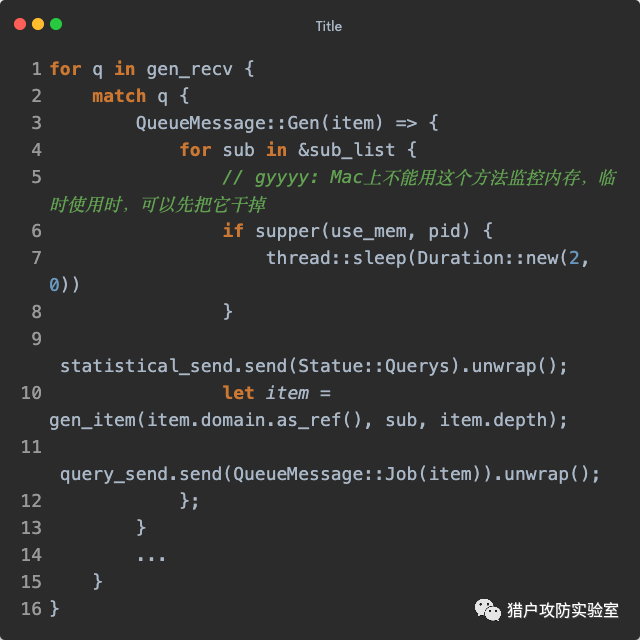 需要注意的是,上面的
gen_item() 传参中,域名和深度都来自于接收到的
GenItem ,可以想象,应该是有一股神秘力量给『域名生成』发送了一个
GenItem ,让它继续对其中的域名进行子域名探测。但是为了保证流程的逻辑性,我们还是继续看『查询』的接收方
subdomain_query_event() ,不出意外,它的代码逻辑同样也在一个单独的子线程中。由于『查询』工作量最大,考虑到性能问题,首先当然是创建一个线程池,然后开始迭代
query_recv 接收消息。当消息类型为
QueueMessage::Job 时,调用线程池异步执行一个匿名函数。先给『统计』发送一个
Statue::Query ,然后调用
query_event() 得到结果集,将其放入一个
Item 包装成
QueueMessage::Job 发送给『检查』,最后再给『统计』发送一个
Statue::Checks 给代表查询成功:
需要注意的是,上面的
gen_item() 传参中,域名和深度都来自于接收到的
GenItem ,可以想象,应该是有一股神秘力量给『域名生成』发送了一个
GenItem ,让它继续对其中的域名进行子域名探测。但是为了保证流程的逻辑性,我们还是继续看『查询』的接收方
subdomain_query_event() ,不出意外,它的代码逻辑同样也在一个单独的子线程中。由于『查询』工作量最大,考虑到性能问题,首先当然是创建一个线程池,然后开始迭代
query_recv 接收消息。当消息类型为
QueueMessage::Job 时,调用线程池异步执行一个匿名函数。先给『统计』发送一个
Statue::Query ,然后调用
query_event() 得到结果集,将其放入一个
Item 包装成
QueueMessage::Job 发送给『检查』,最后再给『统计』发送一个
Statue::Checks 给代表查询成功:
 “
“
Rust语言小贴士:
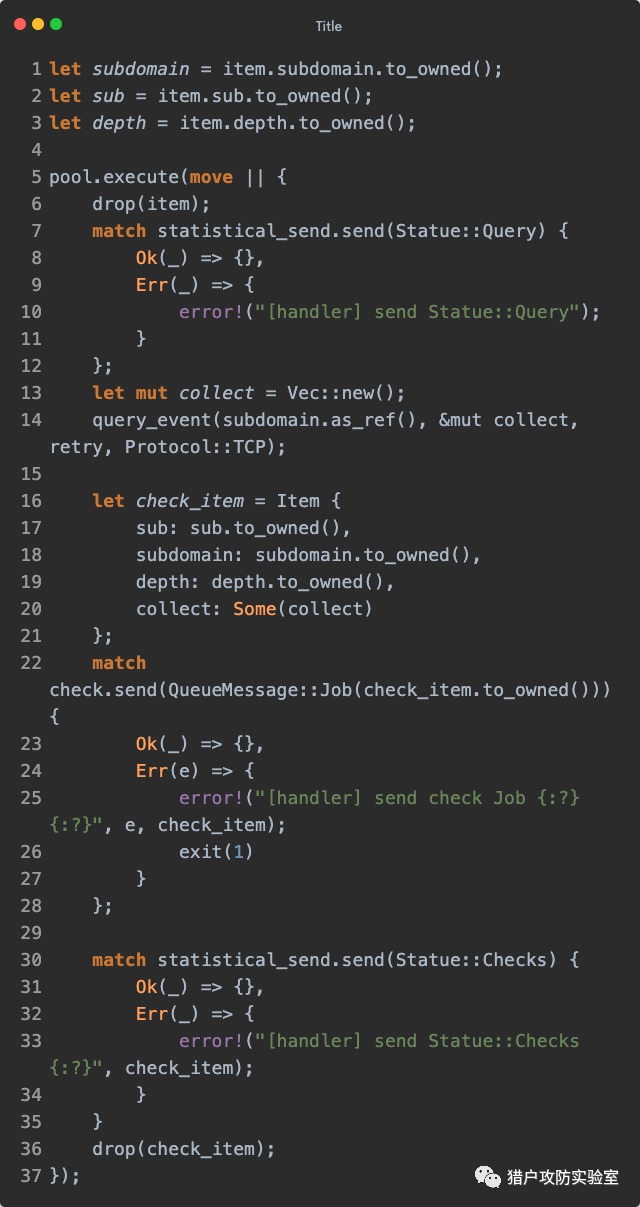
1. drop() 是Rust的 Drop 特性中的唯一方法,从字面意思来看就知道,是手动销毁当前变量,上述代码中可能是考虑到查询量会比较大,所以尽可能提前释放掉使用完的资源避免占用过多内存
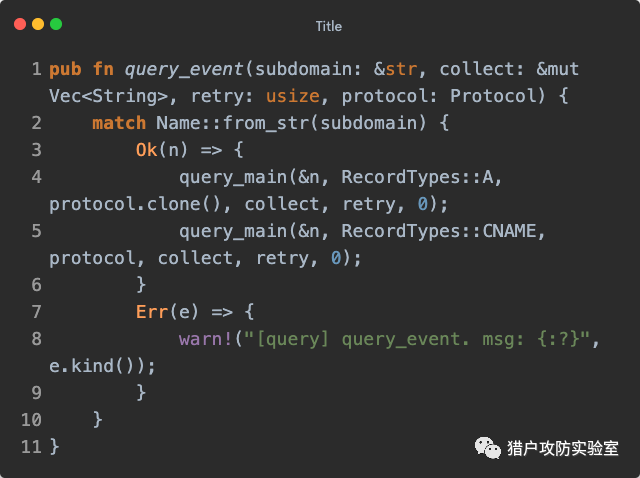 query_main() 实现了TCP和UDP两种协议的查询方式,但是项目中暂时没用到UDP,所以我们只看TCP的实现。非常直观的就是获取一个TCP连接,然后进行查询,将查询结果交给
query_response_handler() 解析成IP或域名放进结果集,如果查询失败,就休眠一小会再递归进行重试:
query_main() 实现了TCP和UDP两种协议的查询方式,但是项目中暂时没用到UDP,所以我们只看TCP的实现。非常直观的就是获取一个TCP连接,然后进行查询,将查询结果交给
query_response_handler() 解析成IP或域名放进结果集,如果查询失败,就休眠一小会再递归进行重试:
 跳到
tcp_connection() 发现它是通过
rand_tcp_dns_server() 随机选择一个公共DNS服务器地址(支持TCP的子集,共8个)进行连接的,如果连接失败就重新选择直到成功连上为止:
跳到
tcp_connection() 发现它是通过
rand_tcp_dns_server() 随机选择一个公共DNS服务器地址(支持TCP的子集,共8个)进行连接的,如果连接失败就重新选择直到成功连上为止:
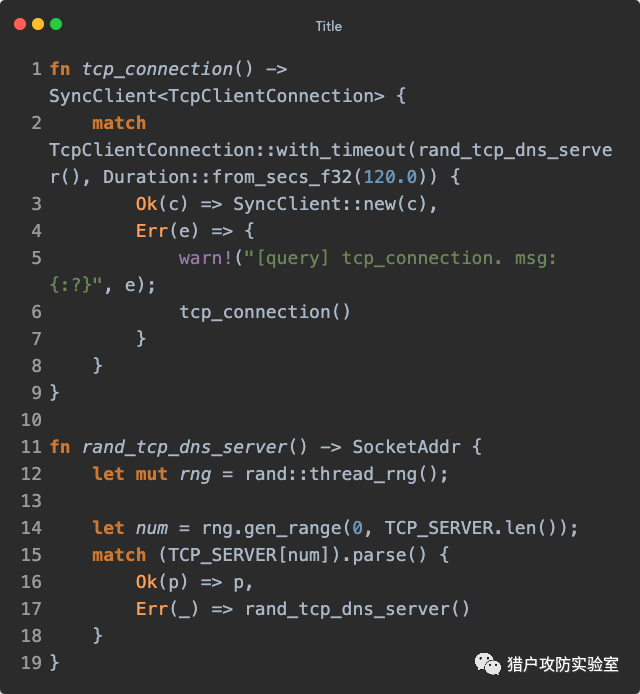 接着就是『检查』的接收方
check_event() 了,仍然是个子线程,它的篇幅有点长,我们拆开来说。先是给『统计』发个
Statue::Check ,然后判断如果当前深度为
0 ,即为主域名时,直接不需要任何理由的生成一个深度+1的
GenItem 包装成
QueueMessage::Gen 发给『域名生成』,让它继续产生子域名(看来『检查』就是之前的神秘力量,被我们找到了):
接着就是『检查』的接收方
check_event() 了,仍然是个子线程,它的篇幅有点长,我们拆开来说。先是给『统计』发个
Statue::Check ,然后判断如果当前深度为
0 ,即为主域名时,直接不需要任何理由的生成一个深度+1的
GenItem 包装成
QueueMessage::Gen 发给『域名生成』,让它继续产生子域名(看来『检查』就是之前的神秘力量,被我们找到了):
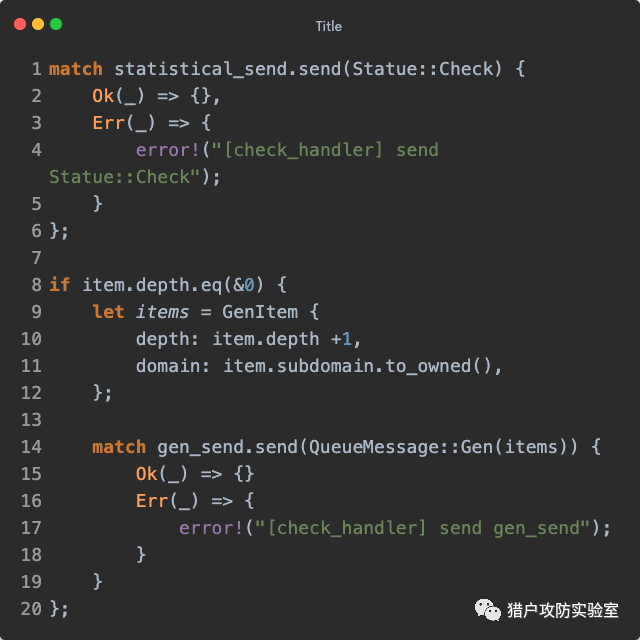 然后调用
check_collect() 检查结果集是否不为空,为空则给『统计』发送
Statue::Unwrite 。接着判断当前深度,为
0 时将域名和结果集封装成
ResultsSubDomain 发送给『结果处理』,并给『统计』发送一个
Statue::Writes ,否则调用
check_wildcards() 检查结果是否不在泛解析白名单中,存在就给『统计』发送
Statue::Unwrite 。与上面一样依次给『结果处理』和『统计』发送消息后,再继续判断当前是否已经是最大深度(由
-l 参数决定,默认为
1 ),以及当前子域名是否在子域名字典中,即是否支持继续下一层的探测,全部条件都通过时,就扔给『域名生成』一个深度+1的
GenItem ,同时发送
Statue::TargetCount 给『统计』:
然后调用
check_collect() 检查结果集是否不为空,为空则给『统计』发送
Statue::Unwrite 。接着判断当前深度,为
0 时将域名和结果集封装成
ResultsSubDomain 发送给『结果处理』,并给『统计』发送一个
Statue::Writes ,否则调用
check_wildcards() 检查结果是否不在泛解析白名单中,存在就给『统计』发送
Statue::Unwrite 。与上面一样依次给『结果处理』和『统计』发送消息后,再继续判断当前是否已经是最大深度(由
-l 参数决定,默认为
1 ),以及当前子域名是否在子域名字典中,即是否支持继续下一层的探测,全部条件都通过时,就扔给『域名生成』一个深度+1的
GenItem ,同时发送
Statue::TargetCount 给『统计』:
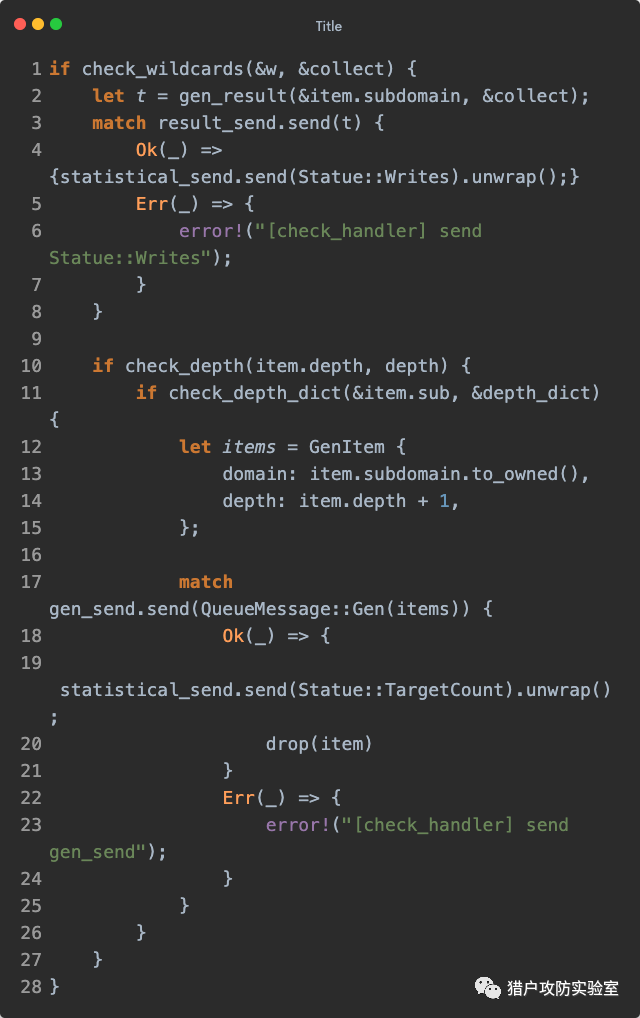 再来是『结果处理』的
write_event() ,这个不需要说太多了,就是子线程中打开结果输出文件(由
-o 参数决定,默认为
baddns-output.json )不停的接收结果转换成JSON对象写进文件中(用的是第三方库
serde_json )。不过比较有意思的是,它为了最终能够满足一个JSON数组的格式标准,会在文件开头和结尾手动拼接一个
[ 和
{}] :
再来是『结果处理』的
write_event() ,这个不需要说太多了,就是子线程中打开结果输出文件(由
-o 参数决定,默认为
baddns-output.json )不停的接收结果转换成JSON对象写进文件中(用的是第三方库
serde_json )。不过比较有意思的是,它为了最终能够满足一个JSON数组的格式标准,会在文件开头和结尾手动拼接一个
[ 和
{}] :
 到这里,单个域名探测的流程就结束了。简单的说,就是『域名生成』产生一个域名,发送给『查询』获得A和CNAME记录,将结果交给『检查』判断是否符合预期条件,是则通过『结果处理』写入文件并通知『域名生成』继续产生下一层子域名。那么问题来了,要探测到什么时候结束呢?
探测结束我们来看看最后剩下的『统计』的
state_management() ,它在子线程中每接收到一个
Statue ,就递增对应变量的值(
Statue::Terminate 除外),比较特殊的是
Statue::TargetCount ,除了递增还会重新计算域名探测总量。这里先简单解释下这个
Statue::TargetCount 计数器的意义,它其实是用来统计『下一层深度探测次数』的。其实我们可以理解为,每进行一次下一层深度探测,相当于在原目标列表的基础上多增加了一个目标。如初始目标域名为
a.com ,探测到第一层子域名
b.a.com 时被判断为可以继续下一层深度探测,『域名生成』就会对
b.a.com 再次遍历子域名字典,也就相当于是增加了一个新的目标域名。由此可知,域名探测总量计算公式如下:
到这里,单个域名探测的流程就结束了。简单的说,就是『域名生成』产生一个域名,发送给『查询』获得A和CNAME记录,将结果交给『检查』判断是否符合预期条件,是则通过『结果处理』写入文件并通知『域名生成』继续产生下一层子域名。那么问题来了,要探测到什么时候结束呢?
探测结束我们来看看最后剩下的『统计』的
state_management() ,它在子线程中每接收到一个
Statue ,就递增对应变量的值(
Statue::Terminate 除外),比较特殊的是
Statue::TargetCount ,除了递增还会重新计算域名探测总量。这里先简单解释下这个
Statue::TargetCount 计数器的意义,它其实是用来统计『下一层深度探测次数』的。其实我们可以理解为,每进行一次下一层深度探测,相当于在原目标列表的基础上多增加了一个目标。如初始目标域名为
a.com ,探测到第一层子域名
b.a.com 时被判断为可以继续下一层深度探测,『域名生成』就会对
b.a.com 再次遍历子域名字典,也就相当于是增加了一个新的目标域名。由此可知,域名探测总量计算公式如下:
 当『待查询总量』分别与『域名探测总量』、『已查询总量』、『待检查总量』和『已检查总量』都相等时,代表探测工作已经全部结束,则向『域名生成』发送
QueueMessage::Terminate 终止消息,『域名生成』接收后通知『查询』终止,后者再通知『检查』终止,『检查』最后再转回来通知『统计』终止,并且在『检查』的子线程结束之前,会主动销毁『结果处理』的发送者
result_send ,导致『结果处理』的迭代接收结束函数返回。因此,主线程最后也是先对
mem_statue 进行了
join() ,这样可以确保除『结果处理』外其他的子线程全部都进入终止阶段,不会出现死锁。而
write_handler 优先于
check_handler 则是为了避免『结果处理』出现接收不完全的情况:
当『待查询总量』分别与『域名探测总量』、『已查询总量』、『待检查总量』和『已检查总量』都相等时,代表探测工作已经全部结束,则向『域名生成』发送
QueueMessage::Terminate 终止消息,『域名生成』接收后通知『查询』终止,后者再通知『检查』终止,『检查』最后再转回来通知『统计』终止,并且在『检查』的子线程结束之前,会主动销毁『结果处理』的发送者
result_send ,导致『结果处理』的迭代接收结束函数返回。因此,主线程最后也是先对
mem_statue 进行了
join() ,这样可以确保除『结果处理』外其他的子线程全部都进入终止阶段,不会出现死锁。而
write_handler 优先于
check_handler 则是为了避免『结果处理』出现接收不完全的情况:
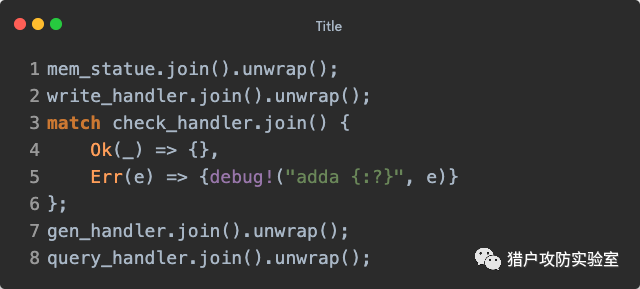 内存控制最后,我们在回过头来简单看看之前提到过的检查内存使用情况的函数
supper() 。它根据
pid 得到当前程序进程内存占用量(
/proc/[pid]/status ),与内存总量(
/proc/meminfo )进行计算后,判断占用比例是否超过指定值:
内存控制最后,我们在回过头来简单看看之前提到过的检查内存使用情况的函数
supper() 。它根据
pid 得到当前程序进程内存占用量(
/proc/[pid]/status ),与内存总量(
/proc/meminfo )进行计算后,判断占用比例是否超过指定值:
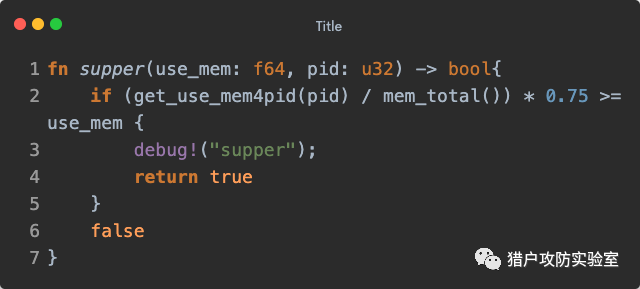 至于为什么要乘以
0.75 就不太清楚了,有可能是作者进行测试以后给出的一个校正值,如果有知道原因的小伙伴请在评论处告知,谢谢。
说在最后的话整体来说,这个项目的逻辑还是非常简单清晰的。只是随机选择公共DNS服务器进行查询那一块,由于我本地环境的原因,有一部分服务器无法正常连接,会有概率多次命中这几个服务器而导致效率上受到影响。可以考虑在生成泛解析白名单阶段,顺便对公共DNS服务器集合进行一次筛选,提前剔除那些无法连接或质量较差的服务器。现在的开源工具太多了,我平时工具用的比较少,不太清楚大家的喜好,如果有觉得好用好玩的开源项目,欢迎在我们公众号留言,有我微信的小伙伴也可以私聊推荐给我,类型不限,语言不限。当然,其他偏代码向的如漏洞分析、代码审计也行,主要照顾一些读写代码相对比较吃力的小伙伴,随缘。
参考1. https://github.com/joinsec/BadDNS/
至于为什么要乘以
0.75 就不太清楚了,有可能是作者进行测试以后给出的一个校正值,如果有知道原因的小伙伴请在评论处告知,谢谢。
说在最后的话整体来说,这个项目的逻辑还是非常简单清晰的。只是随机选择公共DNS服务器进行查询那一块,由于我本地环境的原因,有一部分服务器无法正常连接,会有概率多次命中这几个服务器而导致效率上受到影响。可以考虑在生成泛解析白名单阶段,顺便对公共DNS服务器集合进行一次筛选,提前剔除那些无法连接或质量较差的服务器。现在的开源工具太多了,我平时工具用的比较少,不太清楚大家的喜好,如果有觉得好用好玩的开源项目,欢迎在我们公众号留言,有我微信的小伙伴也可以私聊推荐给我,类型不限,语言不限。当然,其他偏代码向的如漏洞分析、代码审计也行,主要照顾一些读写代码相对比较吃力的小伙伴,随缘。
参考1. https://github.com/joinsec/BadDNS/

喜欢您来,喜欢您再来















 2660
2660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









