






前言
随着互联网时代的到来,人们更加倾向于互联网购物。某宝又是电商行业的巨头,在某宝平台中有很多商家数据。
今天带大家使用python+selenium工具获取这些公开的
适合人群:
Python零基础、对爬虫数据采集感兴趣的同学!
环境介绍:
python 3.6
pycharm
selenium
time
1、安装selenium模块
pip install selenium
2、请求网页地址
if __name__ == '__main__':
keyword = input('请输入你要查询的商品数据:')
driver = webdriver.Chrome()
driver.get('https://www.taobao.com')
main()
def search_product(key):
"""模拟搜索商品,获取最大页数"""
driver.find_element_by_id('q').send_keys(key) # 根据id值找到搜索框输入关键字
driver.find_element_by_class_name('btn-search').click() # 点击搜索案例
driver.maximize_window() # 最大化窗口
time.sleep(15)
page = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]') # 获取页数的标签
page = page.text # 提取标签的文字
page = re.findall('(\d+)', page)[0]
# print(page)
return int(page)
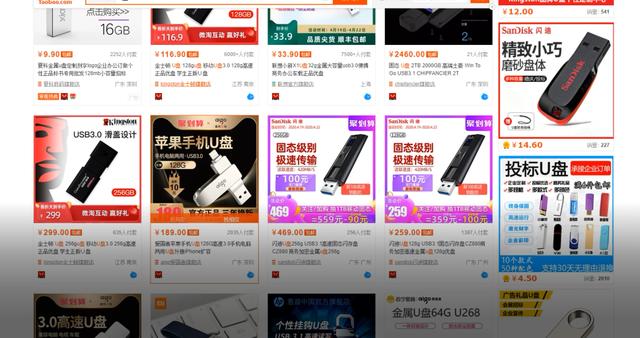
4、获取商品数据
def get_product():
divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for div in divs:
info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text # 商品名称
price = div.find_element_by_xpath('.//strong').text + '元' # 商品价格
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 付款人数
name = div.find_element_by_xpath('.//div[@class="shop"]/a').text # 店铺名称
print(info, price, deal, name, sep='|')
with open('data.csv', 'a', newline='') as csvfile: # newline='' 指定一行一行写入
csvwriter = csv.writer(csvfile, delimiter=',') # delimiter=',' csv数据的分隔符
csvwriter.writerow([info, price, deal, name]) # 序列化数据,写入csv
def main():
search_product(keyword)
page = get_product()

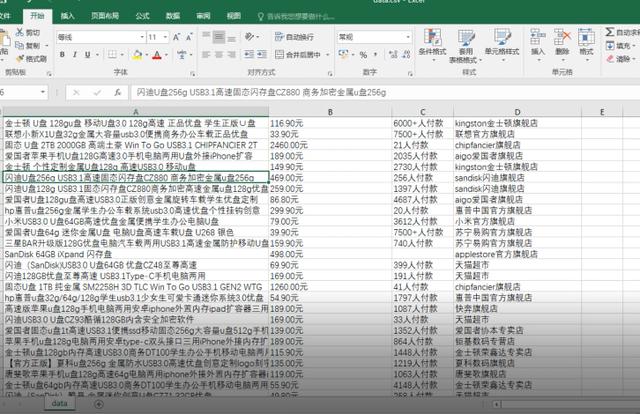
完整代码如下:
from selenium import webdriver
import time
import re
import csv
def search_product(key):
"""模拟搜索商品,获取最大页数"""
driver.find_element_by_id('q').send_keys(key) # 根据id值找到搜索框输入关键字
driver.find_element_by_class_name('btn-search').click() # 点击搜索案例
driver.maximize_window() # 最大化窗口
time.sleep(15)
page = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]') # 获取页数的标签
page = page.text # 提取标签的文字
page = re.findall('(\d+)', page)[0]
# print(page)
return int(page)
def get_product():
divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for div in divs:
info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text # 商品名称
price = div.find_element_by_xpath('.//strong').text + '元' # 商品价格
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 付款人数
name = div.find_element_by_xpath('.//div[@class="shop"]/a').text # 店铺名称
print(info, price, deal, name, sep='|')
with open('data.csv', 'a', newline='') as csvfile: # newline='' 指定一行一行写入
csvwriter = csv.writer(csvfile, delimiter=',') # delimiter=',' csv数据的分隔符
csvwriter.writerow([info, price, deal, name]) # 序列化数据,写入csv
def main():
search_product(keyword)
page = get_product()
if __name__ == '__main__':
keyword = input('请输入你要查询的商品数据:')
driver = webdriver.Chrome()
driver.get('https://www.taobao.com')
main()

喜欢的就请关注加点赞














 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









