






一个心理学实验编程分为六个步骤:
(1)实验刺激材料生成[S];
(2)刺激矩阵生成[M];
(3)实验框架的流程和单试次的流程的代码实现[F];
(4)实验文件和文件夹分发[D];
(5)实验数据采集[C];
(6)数据分析和可视化[A]。
· 这个教程的目标是帮助大家打卡第2个步骤[M]卡片,刺激矩阵生成。我们会以数学认知领域最经典的数字选择比较任务为例(实验单个试次的流程如下图所示),演示整个刺激矩阵生成过程。
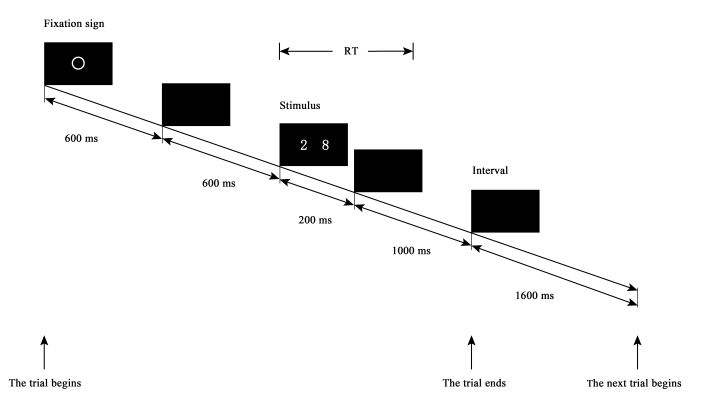
如果把刺激材料比喻成一个个演员和道具,那么,刺激矩阵就是节目单。它决定了刺激材料在什么时候呈现在计算机屏幕上,以及具体呈现多久,以何种方式退场。
刺激矩阵生成的任务,分为了两个子任务:
任务一,要求学生基于已有的数字选择比较任务的数据,获取核心刺激矩阵,保存到一个pairDigits.txt文件中;任务二,要求学生基于这个pairDigits.txt文件中的数字对核心刺激矩阵,建构出完整的伪随机的刺激矩阵。之所以这样布置任务,第一个任务以一种从数据返回到核心刺激矩阵的方式,是希望大家能够对完整的cjMatrix有一个鸟瞰,并对它和核心项目刺激矩阵之间的关系有一个更为直观的认识。
任务一
任务一的起点是行为实验的数据,如下图所示:
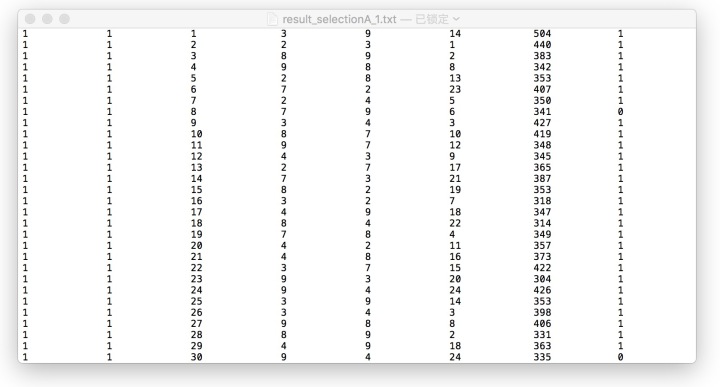
第1列和第2列是没有用的,第3列是trialid,第4列和第5列是左边和右边的数字,第6列是条件type,第7列是反应时,以及最后第8列是正确与否。这个数字大小比较任务,它的自变量是数量语意距离(close vs. far),1-12属于近距离,而13-24属于远距离。
数据所在的百度云盘的位置如下:
链接:https://pan.baidu.com/s/19oRqCxGsFbS1QmMBT_eEdw 密码:d0at
解压缩这个数据文件压缩包之后,如下图所示:
进一步打开文件夹,里边的样子如下:
再进一步打开.txt文件,里边的样子就是一开始的数据矩阵,标记各列的名称如下图所示:
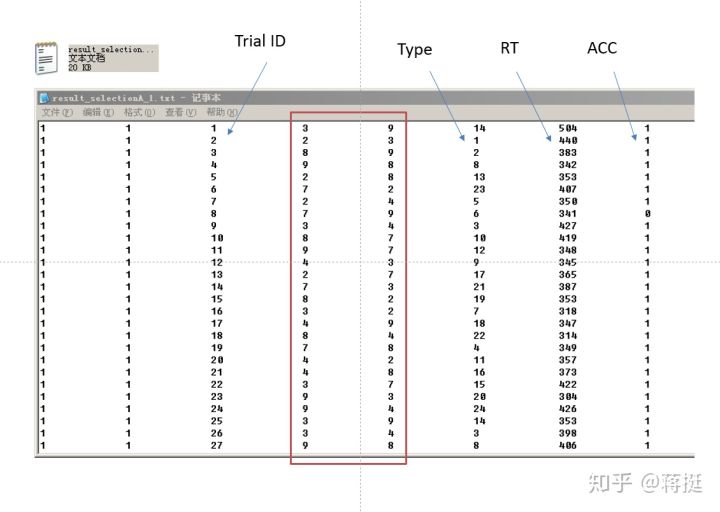
任务一的目标是,想办法把result_selectionA_1.txt文本文件中的24个数字对提取出来,也就是矩阵中的第4列和第5列的内容,按照第6列type的1-24排序,去重后写入到一个pairDigits.txt文件中。具体完成任务一的代码如下:
% filename is:: makePairDigitsFile.m
我给几位本科生做了演示之后,让活泼的DWL同学添加了中文注释,这样做会更有利于大家对代码的理解。这段代码核心的核心步骤是:
(a)利用textread( )这个函数,把result_selectionA_1.txt文件中的数字矩阵都读取出来,输出变量总共有8个,对应着数据文件中的8列,我们只需其中的3列;
(b)保留3列数据,分别是leftDigit + rightDigit + type,然后将它们放入到一个矩阵matrix_col3 里,调用sortrows( )函数根据条件type那一列进行排序;
(c)从1-192行,以8为step增值(因为原来实验,重复次数为8次),读取24个数字对。
(d)在一个循环中,利用fprintf( )函数把24个数字对写入到一个新打开的.txt文件中,一开始要利用fopen打开一个新的.txt文件,然后在循环结束的时候要fclose关闭它。这里的fid是一个变量,相当于一个接口(地址id),所有的内存和硬盘之间的交互都是经由这个接口来完成的。
任务二
任务二的起点是pairDigits.txt中的24个数字对,如下图所示:
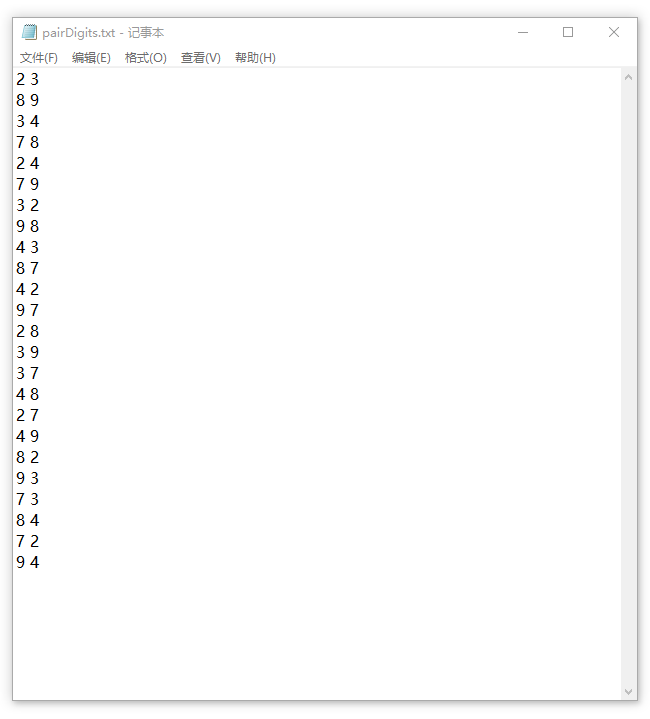
任务二的目标是生成完整的刺激矩阵cjMatrix_Generate()函数,代码分享如下:
function cjMatrix = generate_cjMatrix(repeatNum)
% clear
% clc; clear; close all;脚本文件的遗存,函数里面不能用clear
% prepare 准备预期的最大重复次数和trial总数
upperLimit = 4;
trialNum = 24 * repeatNum;
% prepare准备原始的核心数据
txtFileName = 'pairDigits.txt';
% textread读取核心数据
[leftDigitsArr rightDigitsArr] = textread(txtFileName, '%d %d', 'delimiter',' ');
%把核心数据读取进核心矩阵
coreMatrix = [leftDigitsArr rightDigitsArr];
while 1
% trialid
trialidArray = 1:trialNum;
trialidArray = trialidArray';
% + type 用type给核心数据标序号
typeArr = 1:24; typeArr = typeArr';
coreMatrix_3col = [coreMatrix typeArr];
% + correctResponseArr 标注正确反应的按键
correctResponseArr = [];
for i = 1:length(coreMatrix_3col)
leftDigitValue = coreMatrix_3col(i,1);
rightDigitValue = coreMatrix_3col(i,2);
if leftDigitValue < rightDigitValue
tmpCorrectResponseValue = 2; % 1 == left vs. 2 == right ;1表示按左键,2表示按右键
else
tmpCorrectResponseValue = 1;
end
correctResponseArr = [correctResponseArr; tmpCorrectResponseValue]; % ; == 纵向叠加, 如果是空格,说明是水平叠加,之后要转置
end
coreMatrix_4col = [coreMatrix_3col correctResponseArr];
% 获取8倍的核心矩阵(4列,leftD rightD type correctRes)的内容
tmpMat_4col_x8 = kron(coreMatrix_4col, ones(repeatNum,1));
% rand 把192个trial随机
tmpRandArr = randperm(trialNum)';
tmpMat_addRarr = [tmpMat_4col_x8 tmpRandArr];
tmpMat_rand = sortrows(tmpMat_addRarr, 5); % 第5列是新加的随机向量
% get the matrix withouth rand arr 踢掉随机向量
cjMatrix_r_192x4 = tmpMat_rand(:,1:4); % 5, gone with the wind
% add trialidArray
cjMatrix_r_192x5 = [trialidArray cjMatrix_r_192x4];
% check the condition, specially for the correctResponse 检查是否超过最大重复次数
count_repeat = 1;%重复次数
count_Max = 1;%重复最大值
%比较j和j-1行的按键是否一致
for j = 2:length(cjMatrix_r_192x5)
if cjMatrix_r_192x5(j, 5) == cjMatrix_r_192x5(j-1, 5)
count_repeat = count_repeat + 1;
if count_repeat > count_Max %如果重复次数超过最大值,就赋值给最大值
count_Max = count_repeat;
end
else
count_repeat = 1;
end
end
%如果重复最大值大于预期的最大重复次数就重来
if count_Max > upperLimit
continue;
else
break;
end
end % for while 1, Line 18
cjMatrix = cjMatrix_r_192x5;
end第1段代码:
% clear
% clc; clear; close all;脚本文件的遗存,函数里面不能用clear
·这段代码是注释的,说明一开始我就是用脚本的方式在写代码,最后才把格式转成函数的。为什么?因为,只有这样才能在Matlab的工作空间看到变量的情况,如果用函数来运行,我们什么都看不见。
第2段代码:
% prepare 准备预期的最大重复次数和trial总数
upperLimit = 4;
trialNum = 24 * repeatNum;
% prepare准备原始的核心数据
txtFileName = 'pairDigits.txt';
·设置一个上限,它的目的是为伪随机准备的,对应的是正确反应的重复次数,一般设置为4,3太刻意来,5又太大了。
·然后,我们准备了一个文本文件的文件名'pairDigits.txt'
第3段代码:
% textread读取核心数据
[leftDigitsArr rightDigitsArr] = textread(txtFileName, '%d %d', 'delimiter',' ');
%把核心数据读取进核心矩阵
coreMatrix = [leftDigitsArr rightDigitsArr];
·这段的目的是从文本文件中读取核心项目刺激矩阵,然后赋值给coreMatrix这个变量。
接下来就进入一个while 循环,这个循环一开始是1,或者true,也就是典型的根本停不下来的那种循环,除非在程序中遇到break这个命令。它本质上有点类似C语言中do ... while 这样的循环结构,先运行再判断,但是,Matlab没有提供这样的循环结构,所以才改成现在这样。它和标准的while条件语句的循环结构不一样的是,生成完整的伪随机的cjMatrix的过程语句要在while之前写一次,条件不符合的话,重复再写一次。显然,while 1 ... break ... end 这样的循环结构会使得整个代码看起来更简洁,可读性更强。
while语句中分为三个模块:
模块一,扩充模块:核心项目的刺激矩阵(不包括trialid)的扩充,一般是利用kron克隆这个函数复制repeatNum个,最后形成一个192行x4列的完整刺激矩阵。它的问题是,没随机❌
模块二,随机模块:生成一列随机数向量,放置在扩充好的刺激矩阵的右侧,然后借助sortrows函数根据第5列进行排序,tmpMat_rand = sortrows(tmpMat_addRarr, 5),再将第5列舍弃,就可以获取一个随机刺激矩阵。这个时候再把一开始准备好的trialidArray这个向量拼接在整个刺激矩阵的左侧,就可以得到完整的随机的刺激矩阵。然后,它的问题是,没有伪随机❌
模块三,确认模块:初始化两个变量,count_repeat = 1和count_Max = 1。我们会利用循环,从第2个项目开始,依次完成第N行与第N-1行之间的比对。如果相同,count_repeat 这个变量就+1;如果不同,count_repeat 就重新设定为1。在count_repeat+1的时候,我们还会拿它与count_Max进行比较,要是count_repeat超过count_Max了,就更新count_Max = count_repeat。循环结束之后,我们只需要拿count_Max反应重复的最大值和一开始设定的反应重复次数的上限upperLimit进行比较,就可以决定,是跳出循环break,还是再来一次循环continue。
补充讲解第4段代码:
第4段代码:
% + correctResponseArr 标注正确反应的按键
correctResponseArr = [];
for i = 1:length(coreMatrix_3col)
leftDigitValue = coreMatrix_3col(i,1);
rightDigitValue = coreMatrix_3col(i,2);
if leftDigitValue < rightDigitValue
tmpCorrectResponseValue = 2; % 1 == left vs. 2 == right ;
else
tmpCorrectResponseValue = 1;
end
correctResponseArr = [correctResponseArr; tmpCorrectResponseValue];
% ; == 纵向叠加, 如果是空格,说明是水平叠加,之后要转置 end这段提供了一个空矩阵correctResponseArr,然后依据leftDigit和rightDigit的大小关系来决定correctResponse的值是多少,然后不断地纵向(注意矩阵中;号的使用)叠加到correctResponseArr这个向量中。
最后要记得,要把生成的伪随机过的完整的刺激矩阵cjMatrix_r_192x5赋值给输出变量cjMatrix。
这个函数第一个版本完成时,我们为了让整个函数的普适性增加,把repeatNum作为函数的输入参数。这样的好处是,重复次数的多少就可以在调用函数时来决定。如果选择这样操作,就要在整个函数的代码中找到与repeatNum有关的参数,比如总的trialNum,设置为trialNum = 24 * repeatNum;再比如,对核心项目对应的刺激矩阵进行克隆的时候,也要用到repeatNum,tmpMat_4col_x8 = kron(coreMatrix_4col, ones(repeatNum,1))。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









