






 该博客通过分析泰坦尼克号数据集,预测乘客的生存率。首先,对数据进行采集、导入和基本信息查看,发现数据中存在缺失值。接着,对数值型和字符串型缺失值分别进行处理,采用平均值填充数值型,用最常见值填充分类数据。然后,对分类数据进行编码,并提取关键特征,如性别、登船港口、客舱等级和乘客头衔。通过相关系数法选择特征,并利用逻辑回归建立模型。最后,将模型应用于测试数据集,生成预测结果,用于提交到Kaggle平台。
该博客通过分析泰坦尼克号数据集,预测乘客的生存率。首先,对数据进行采集、导入和基本信息查看,发现数据中存在缺失值。接着,对数值型和字符串型缺失值分别进行处理,采用平均值填充数值型,用最常见值填充分类数据。然后,对分类数据进行编码,并提取关键特征,如性别、登船港口、客舱等级和乘客头衔。通过相关系数法选择特征,并利用逻辑回归建立模型。最后,将模型应用于测试数据集,生成预测结果,用于提交到Kaggle平台。

此次进行分析的数据集来自Kaggle,链接如下
数据集下载链接www.kaggle.com1.提出问题
什么样的人在泰坦尼克号中更容易存活?
2.理解数据
2.1采集数据
从上面给出的链接里面将泰坦尼克号项目相关的数据集下载下来,包括gender_submission,test和train三个数据集,并在网站上对数据集内包含的信息有一个初步的认识。

2.2导入数据
# 忽略警告提示
import warnings
warnings.filterwarnings('ignore')
#导入处理数据包
import numpy as np
import pandas as pd
#导入训练数据集
train=pd.read_csv('/Users/huang/Python/3.泰坦尼克号/train.csv')
#导入测试数据集
test=pd.read_csv('/Users/huang/Python/3.泰坦尼克号/test.csv')
#查看数据集的概况
print('训练数据集:',train.shape,'测试数据集:',test.shape)输出结果:
训练数据集: (891, 12) 测试数据集: (418, 11)从结果可以看到,测试数据集中少的一个变量,这个变量就是生存率预测。因为我们的目的是生成模型来预测生存率,因此测试数据集没有这个变量。
#为了方便同时对训练数据和测试数据进行清洗,需要将两个数据集合并
full=train.append(test,ignore_index=True)
print('合并后的数据集:',full.shape)输出结果:
合并后的数据集: (1309, 12)2.3查看数据集信息
#查看合并后的数据集信息
full.head()输出结果:

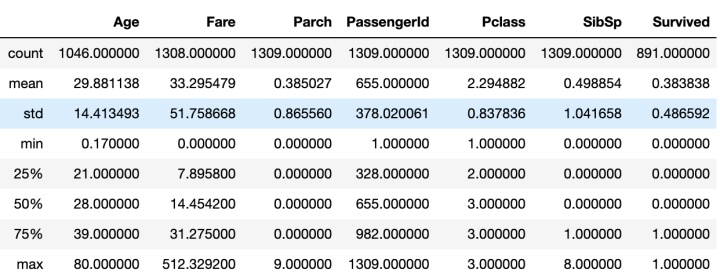
'''使用discribe获取数据类型列的描述统计信息;需要注意discribe只能显示出数据类型的列信息,对于其他类型的数据不显示,比如字符串类型姓名(name),客舱号(Cabin)
这很好理解,因为描述统计指标是计算数值,所以需要该列的数据类型是数据'''
full.describe()输出结果:
#查看缺失数据
#使用info方法,查看每列的数据总数和数据类型
full.info()输出结果:

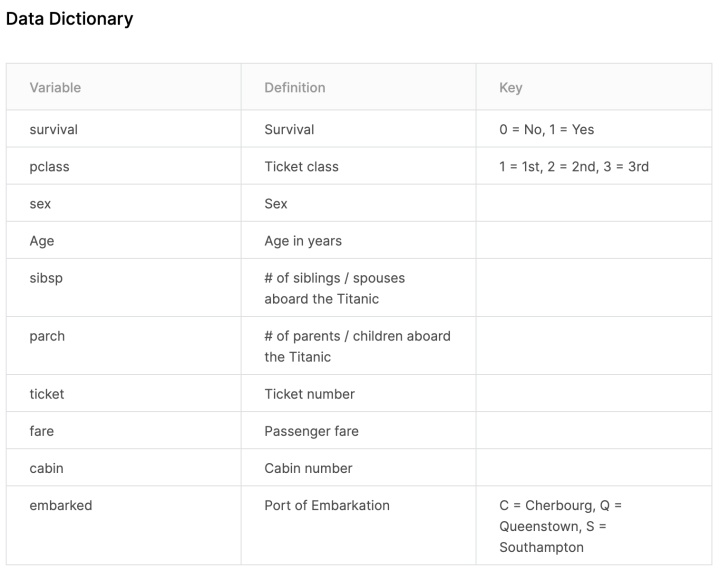
可以看到总共有1309行数据,其中有缺失数据的列包括年龄(Age)、船舱号(Cabin)、登船港口(Embarked)、船票价格(Fare),属于数据类型的是年龄和船票价格,属于字符串类型的是船舱号、登船港口。
其中:
年龄项总数据为1046,缺失了263项,缺失率约为20%;
船票价格总数据为1308,缺失了1项;
登船港口总数据为1307,缺失了2项;
船舱号总数据为295,缺失了1014项,缺失率约为77.5%,缺失较多。
此处先将数据缺失的情况列明,方便后续进行针对性处理。
3.数据清洗
3.1数据预处理
缺失值处理
很多机器学习算法为了训练模型,要求所传入的特征中不能有空值,因此需要事先对缺失值进行处理。常见处理的方法包括:
- 数值类型,可用平均值填充
- 分类数据,可用最常见的类别填充
- 使用模型预测缺失值
3.1.1数据类型缺失值的处理
从前面我们可以得到年龄和船票价格的缺失值是数据类型,因此这里需要对数据类型的缺失值进行处理。
#使用平均值对年龄和船票价格列缺失值进行填充
#年龄(Age)
full['Age']=full['Age'].fillna( full['Age'].mean() )
#船票价格(Fare)
full['Fare'] = full['Fare'].fillna( full['Fare'].mean() )
print('处理后:')
full.info()输出处理后的结果:

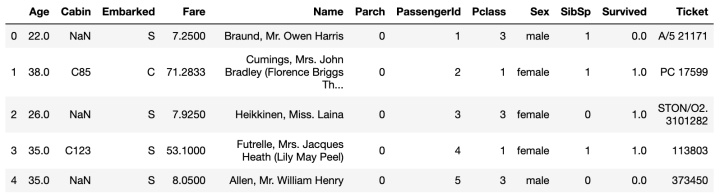
#检查数据处理是否正常
full.head()输出结果:
3.1.2字符串类型缺失值的处理
字符串类型缺失列分别为登船港口(Embarked)和船舱号(Cabin),下面先来处理登船港口列。
- 登船港口(Embarked)
#查看登船港口列里面数据样貌
full['Embarked'].head()输出结果为:

由数据下载页面给出的信息,我们可以知道S=英国南安普顿Southampton;C=法国 瑟堡
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









