





网络爬虫是一种按照一定规则,自动抓取万维网数据的脚本。按照一定规则,指的是爬虫程序需要解析网页的dom结构,针对dom结构爬取自己感兴趣的数据。

(图1)
这就是一个网页源码的dom结构,我们需要一级一级指定抓取的标签,如下图:
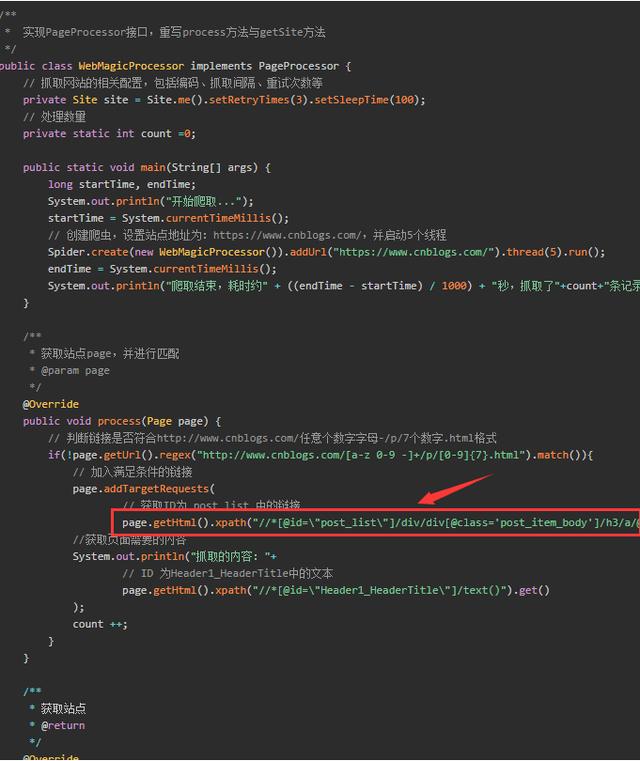
(图2)
图2是java程序使用webmagic框架开发的爬虫程序,这段代码就是抓取对应的标签,和图1是相对应的,运行后得到结果如下:

当然,以上是专业程序员干的事情,但是有助于我们理解爬虫工具工作的原理。非专业人员可以通过爬虫工具来自己爬取数据。
1.首先输入你要爬取的网站的网址,点击“开始采集”。

2.工具自动识别到当前页面是多页数据,会默认翻页采集,我们只要点击“生成采集设置”即可。
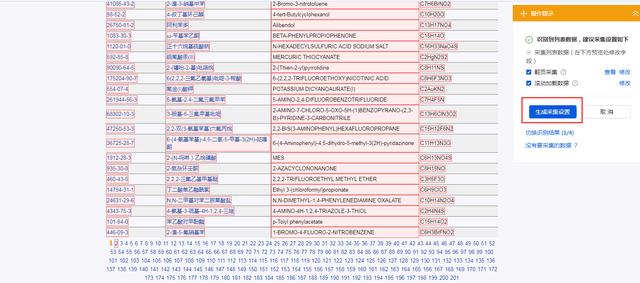
3.点击要采集的详细链接,这里我们要采集这个网站上所有的化工产品的信息,所以点击中文名称这一列某个链接,再点击右侧“点击该链接”,如下图

4.爬虫工具进入到详细链接的页面,这个页面的数据也就是我们要爬取的,点击“生成采集设置”,会生成爬虫工具最后的爬取流程,如下图所示,爬虫工具就会按照这个流程给我们采集数据,直到数据采集完成。
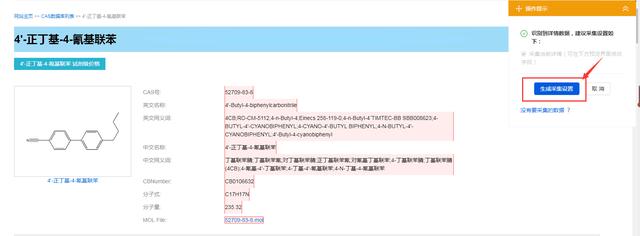

5.点击“采集”按钮,爬虫工具正式开始运行,爬虫工具工作时如下:

列表的这些数据都是爬虫采集到的,我们还可以对这些采集的数据做处理,可以选择导成Excel文档,或者直接导入数据库,这些是后续分析数据,对数据做进一步处理的必要条件。有了这些基础数据,可以对数据做分析,得出一些商业依据,可以作为商业决策时的支撑。比如以前沃尔玛就通过他们的大数据,发现买尿不湿的奶爸喜欢一起买啤酒,于是就把尿不湿和啤酒摆在一起,啤酒的销量大增,这个就是大数据的价值。
这次讲的爬虫工具使用,只是比较基础的应用,希望对大家有帮助。科技漫步者带你漫步科技,后续会不断更新相关知识,欢迎关注。















 2510
2510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









