





写在最前
Python在数据分析领域有三个必须需要熟悉的库,分别是pandas,numpy和matplotlib,如果排个优先级的话,我推荐先学pandas。
numpy主要用于数组和矩阵的运算,一般在算法领域会应用比较多。matplotlib用于作图的话其实可替代的库会比较多,譬如有封装的更高级的seaborn,调用起来会更方便,也有交互性更强的pyecharts,风格会更讨喜。
但对于pandas,似乎完全绕不开,当然这三个库都是非常优秀的库,如果你已经入坑数据分析,建议全学?。
基本用法
读取数据
SQL
sql读取数据其实没啥可说的,一句简单的select * from table_name就OK了。
Pandas
pandas支持的数据源很多,包括csv,excel,以及读取数据库,当然读取数据库的话需要配合其他库,包括oracle,mysql,vertica,presto等等都是支持的。
常见的如下:
pandas.read_csv():用于读取csv文件;pandas.read_excel():用于读取Excel文件;pandas.read_json():用于读取json文件;pandas.read_sql():用于读取数据库,传入sql语句,需要配合其他库连接数据库。
由于我本地没有数据库资源,我这边就以csv文件为例:
import pandas as pd
data = pd.read_csv('directory.csv', encoding='utf-8')
# data.head()默认显示前5条记录,类似还有data.tail()
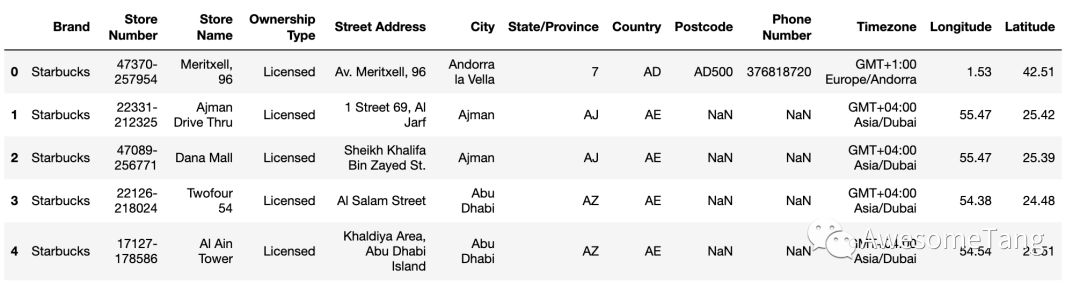
data.head()
筛选列
SQL
select city, country
from table_name
Pandas
# 筛选一列
# 这样返回的是series
data['City'].head()
# 这样返回的是dataframe,注意差别
data[['City']].head()
# 筛选多列
data[['City','Country']].head()
筛选行
SQL
sql本身并不支持筛选特定行,不过可以通过函数排序生成虚拟列来筛选。
-- 筛选前100行
select *
from table_name
limit 100
Pandas
pandas支持的方式就比较多了,如果你了解python的切片操作,以下应该会比较好理解。
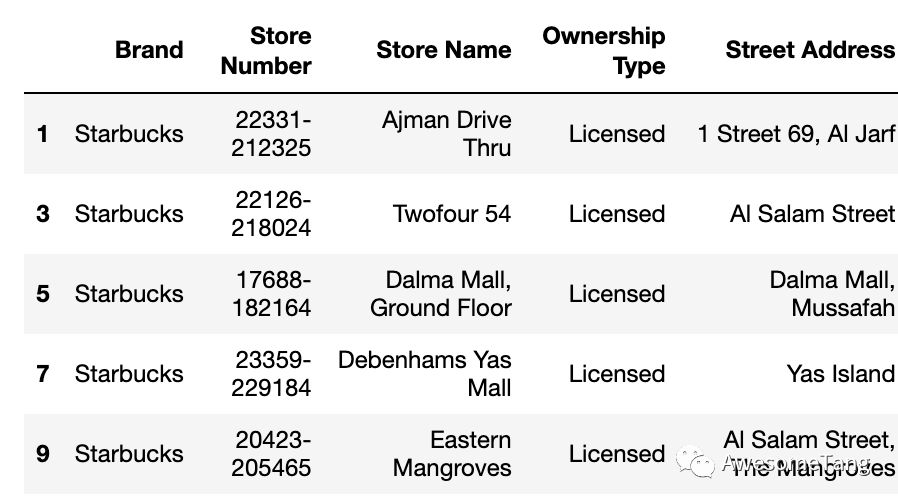
data[:3]:筛选前3行;

data[1:10:2]:筛选1到10行中的奇数行,最后一个数字2表示每隔2行取数;
行列同时筛选
pandas主要有data.iloc和data.loc来支持行列筛选,虽然还有data.ix,但在目前最新的pandas已经将其弃用了。
其实我一开始对这两个方法很容易混淆,其实后面发现很好区分,如果需要用列名来筛选,请用loc,如果使用列索引,请用iloc。
# 根据列名,请用loc
# 筛选1到10行的奇数行,City和Country列
data.loc[1:10:2,['City','Country']]
# 筛选第2和第4行,City和Country列
data.loc[[2,4],['City','Country']]
# 根据列索引,请用iloc
# 筛选1到10行的奇数行,2到5列
data.iloc[1:10:2,2:5]
# 筛选1到10行的奇数行,2到10列中每隔3列取一列
data.iloc[1:10:2,2:10:3]
# 筛选第2和第4行,第3和第5列
data.iloc[[2,4],[3,5]]
根据条件筛选
SQL
select city, country
from table_name
where city = 'shanghai'
Pandas
在看示例之前需要提醒下,在Pandas中并不支持and 和or,相应的是&和|,而且由于&和|在运算优先级是优于== ,>等运算符等,因此在多条件筛选需要加上括号,类似(a == 1) & (b > 2)。
# 筛选Brand为Starbucks
data.loc[data['Brand'] == 'Starbucks']
# 筛选City为shanghai或者为beijing
data.loc[(data['City'] == 'shanghai') | (data['City'] == 'beijing')]
# 筛选Brand为Starbucks而且City为shanghai
data.loc[(data['Brand'] == 'Starbucks') & (data['City'] == 'shanghai')]
# 使用.isin
data.loc[data['City'].isin(['shanghai', 'Ajman', 'wuhan'])]
# 筛选Timezone列中包含Asia
data.loc[data['Timezone'].str.contains('Asia')]
分组聚合
SQL
select column_A, sum(column_B)
from table_name
group by column_A
Pandas
基本用法:
对DataFrame进行goupby运算后,返回的是一个groupby对象,我们可以通过.reset_index()将其转为DataFrame。
# 以Ownership Type列分组,对Brand列进行计数
# .reset_index()将groupby对象转成dataframe
data.groupby(['Ownership Type'])['Brand','Country'].count().reset_index()
# 以Country和City列进行分组,对Longitude进行求平均
data.groupby(['Country', 'City'])['Longitude'].mean().reset_index()
高阶用法:
我们可以同时对于不同列采取不同的聚合运算,譬如对A列使用sum(),对B列使用mean(),在SQL中其实很好实现的功能,在Pandas我们需要借助.agg()来实现 。
# 对不同列进行不同对运算
# 对Longitude进行MAX操作,对City列进行Count
data.groupby(['Ownership Type']).agg({'Longitude':'max', 'City':'count'}).reset_index()
# 对统一列进行不同对操作
data.groupby(['Ownership Type'])['Longitude'].agg(['max', 'count']).reset_index()
连接
SQL
select *
from table_A a
left join table_B b
on a.id = b.id
Pandas
在Pandas中我们可以使用pandas.merge()来完成连接对操作。
pandas.merge(left, right, how='inner', on=None, left_on=None,
right_on=None, left_index=False, right_index=False, sort=True)
各参数解释如下:
left:一个DataFrame对象;
right:另一个DataFrame对象;
how:连接方式,默认为inner(内连接);
on:连接键,必须在left和right两个DataFrame中存在,否则使用left_on和right_on;
left_on:left中的连接键;
right_on:right中的连接键;
left_index/right_index:默认为False,如果为True则使用索引作为连接的键。
# 生成两个DataFrame
left = pd.DataFrame({
'id':[1,2,3,4,5],
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame(
{'id':[1,2,3,4,5],
'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5']})
df = pd.merge(left=left, right=right, on='subject_id', how='left')
print(df)
'''
id_x Name_x subject_id id_y Name_y
0 1 Alex sub1 NaN NaN
1 2 Amy sub2 1.0 Billy
2 3 Allen sub4 2.0 Brian
3 4 Alice sub6 4.0 Bryce
4 5 Ayoung sub5 5.0 Betty
'''
高阶用法
正则表达式
SQL
Oracle目前是支持正则表达式的,其他的数据库暂时不大了解,如果想了解用法的可以参考这篇教程,这边就不举例了。
Pandas
# 生成一个DataFrame
df = pd.DataFrame({
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'Location':['湖北省武汉市','广东省深圳市','广东省广州市','湖南省长沙市','湖北省鄂州市']})
# 返回一列的时候expand为True返回的是Dataframe
print(df['Location'].str.extract('(.*?)省', expand=True))
'''
0
0 湖北
1 广东
2 广东
3 湖南
4 湖北
'''
# 返回一列的时候expand为True返回的是Dataframe
print(df['Location'].str.extract('(.*?)省(.*?)市', expand=True
).rename(columns = {0: 'Province', 1: 'City'}))
'''
Province City
0 湖北 武汉
1 广东 深圳
2 广东 广州
3 湖南 长沙
4 湖北 鄂州
'''
# 与原DataFrame拼接,axis=1表示为横向拼接
print(pd.concat([df, df['Location'].str.extract('(.*?)省(.*?)市', expand=True
).rename(columns = {0: 'Province', 1: 'City'})], axis=1))
'''
Name Location Province City
0 Alex 湖北省武汉市 湖北 武汉
1 Amy 广东省深圳市 广东 深圳
2 Allen 广东省广州市 广东 广州
3 Alice 湖南省长沙市 湖南 长沙
4 Ayoung 湖北省鄂州市 湖北 鄂州
'''
当然对于pandas除了正则之外,其实在.str中还内置了很多字符串的方法,如切割(split),替换(replace)等等。
自定义函数
Pandas中内置很多常用的方法,譬如求和,最大值等等,但很多时候还是满足不了需求,我们需要去调用自己的方法,Pandas中可以使用map()和apply()来调用自定义的方法,需要注意下map()和apply()的区别:
map():是pandas.Series()的内置方法,也就是说只能用于单一列,返回的是数据是Series()格式的;apply():可以用于单列或者多列,是对整个DataFrame的元素进行运算,返回一个DataFrame。
import numpy as np
# 随机生成一个DataFrame
df = pd.DataFrame(np.random.randn(4, 3), columns=['A', 'B', 'C'])
print(df)
'''
A B C
0 -0.487982 0.898259 0.120316
1 -3.411103 0.139425 -1.969046
2 1.192626 -1.053607 0.596296
3 -0.981491 0.281875 -0.910885
'''
# map()是针对pandas.Series()的内置方法
# apply()可以用于DataFrame和Series
# 取绝对值,返回的是Series
print(df['A'].map(lambda x: abs(x)))
'''
0 0.487982
1 3.411103
2 1.192626
3 0.981491
Name: A, dtype: float64
'''
# 对整个DataFrame进行取绝对值
print(df[['A']].apply(lambda x: abs(x)))
'''
A
0 0.487982
1 3.411103
2 1.192626
3 0.981491
'''
# 自定义函数
def _abs(x):
return abs(x)
print(df.apply(_abs))
'''
A B C
0 0.487982 0.898259 0.120316
1 3.411103 0.139425 1.969046
2 1.192626 1.053607 0.596296
3 0.981491 0.281875 0.910885
'''
DataFrame拼接
前文提到了merge() ,其实也算作拼接的一种,如果将merge()类比为join操作,接下来讲的拼接将类似于SQL中的union all操作。
df1 = pd.DataFrame(np.random.randn(2, 3), columns=['A', 'B', 'C'])
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['B', 'C', 'D'])
print(df1)
'''
A B C
0 1.371182 -0.201213 0.078707
1 2.607673 0.480420 -0.736990
'''
print(df2)
'''
B C D
0 0.472007 0.932799 -1.236443
1 2.207940 0.696062 0.237979
'''
# 默认纵向连接,即union操作
# ignore_index为True为重新生成索引
print(pd.concat([df1, df2], axis=0, ignore_index=True, sort=False))
'''
A B C D
0 1.371182 -0.201213 0.078707 NaN
1 2.607673 0.480420 -0.736990 NaN
2 NaN 0.472007 0.932799 -1.236443
3 NaN 2.207940 0.696062 0.237979
'''
# axis=1为横向连接
print(pd.concat([df1, df2], axis=1))
'''
A B C B C D
0 1.371182 -0.201213 0.078707 0.472007 0.932799 -1.236443
1 2.607673 0.480420 -0.736990 2.207940 0.696062 0.237979
'''
# append不会重新生成DataFrame,在原DF上添加
print(df1.append(df2,sort=False))
'''
A B C D
0 1.371182 -0.201213 0.078707 NaN
1 2.607673 0.480420 -0.736990 NaN
0 NaN 0.472007 0.932799 -1.236443
1 NaN 2.207940 0.696062 0.237979
'''
写在最后
本来想着Pandas用了这么久了,写个教程应该不麻烦,结果耗费了两个下午也才写了点皮毛。其实如果要写的详细点,每个点都能写篇文章,篇幅有限,只能点到即止,后面如果想到再做补充吧。
Talk is cheap, show me the code.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









