





 大数据 / 人工智能 / 区块链 / 数据库 / 热点
大数据 / 人工智能 / 区块链 / 数据库 / 热点
 SQL(Structured Query Language)是当今使用最广泛的数据查询语言,最初被设计仅适用于RDBMS。但随着各种数据管理系统的出现,常常需要在多个数据源中使用相应的SQL方言。本文为您盘点统一SQL研究现状,并选取两种统一SQL方案进行测试与分析。
SQL(Structured Query Language)是当今使用最广泛的数据查询语言,最初被设计仅适用于RDBMS。但随着各种数据管理系统的出现,常常需要在多个数据源中使用相应的SQL方言。本文为您盘点统一SQL研究现状,并选取两种统一SQL方案进行测试与分析。

王涵毅 | 文
© 中兴数据智能(ZTE-DI)出品

研究背景
各式各样的数据管理系统,包括关系型数据库、文档数据库、key-value 数据库、对象存储系统等等,给管理不同数据带来了便利,但同时也带来了异构数据源数据多样化的难题。这些数据管理系统大多支持SQL查询,但是由于ANSI SQL仅提供了一种标准,各个数据管理系统在此基础上逐渐发展成具有自身特点的SQL方言,并且差异愈加明显。数据分析人员需要针对不同的数据管理系统学习使用特定的SQL方言,无疑增加了使用成本。 除了存在SQL方言的问题,多种数据源联合查询也提高了数据分析的门槛。目前广泛使用的解决方案是通过构建数据仓库,将各个孤立的数据源中的数据整合到数据仓库中,即抽取(Extract)、转换(Transform)、加载(Load)。但是随着数据量的不断增长,数据仓库的规模逐渐增大,ETL所需的人力成本、时间成本、软件与硬件成本逐渐上升。并且由于ETL需要花费一定时间,由此造成了T+1的数据分析模式,在强调商业智能(BI)的今天,显然是不够及时的。并且随着业务的不断增长,可能需要联结多个数据仓库的数据进行分析,此时数据仓库在某种意义上已经成为了数据孤岛。
Greenplum数据虚拟化框架PXF
PXF(Greenplum Platform Extension Framework)作为Greenplum数据虚拟化的解决方案。PXF提供了连接器,使你可以访问存储在Greenplum数据库以外的源中的数据。这些连接器将外部数据源映射到Greenplum数据库外部表,提供跨异构数据源的并行、高吞吐量数据访问和联合查询。 GPDB集群包含一个master节点(master node)和多个segment主机(segment host)。GPDB segment主机上的PXF客户端进程为对外部表进行查询的每个segment实例分配工作线程。多个segment主机的PXF代理与外部数据存储并行通信。 HDFS是Apache Hadoop主要使用的分布式存储机制。当用户或应用程序在引用HDFS文件的PXF外部表上执行查询时,Greenplum数据库master节点会将查询分派给所有segment主机。每个segment实例都与在其主机上运行的PXF代理联系。当它收到来自segment实例的请求时,PXF代理将:- 分配一个工作线程以处理来自某个segment的请求。
- 调用HDFS Java API,从HDFS NameNode请求有关HDFS文件的元数据信息。
- 将HDFS NameNode返回的元数据信息提供给segment实例。
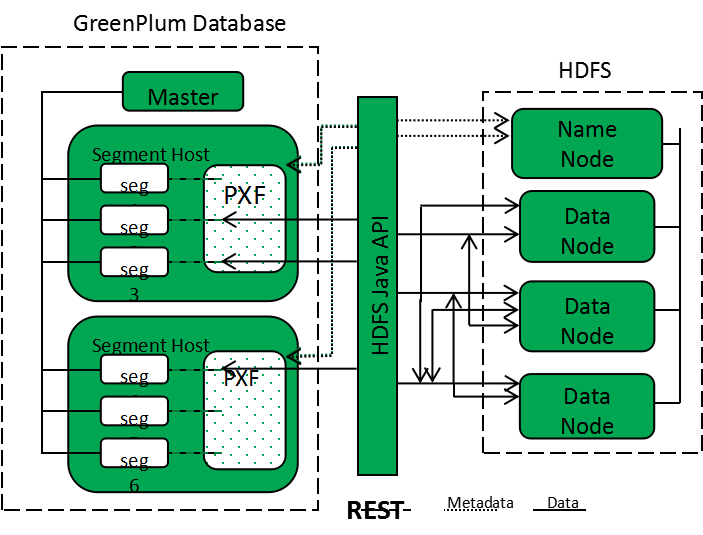 ▲ 深色模式下请点击图片查看
Facebook分布式查询引擎Presto
Presto是Facebook开源的、完全基于内存的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto是运行在多台服务器上的分布式系统。完整安装包括一个coordinator和多个worker。此外还有一项discovery.uri,默认情况下该发现服务是内置在coordinator中的。coordinator和worker都会注册到discovery server。coordinator可以知道worker的数量,以便分配工作,而worker可以识别出coordinator。由客户端提交查询,从Presto命令行CLI提交到coordinator。coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
▲ 深色模式下请点击图片查看
Facebook分布式查询引擎Presto
Presto是Facebook开源的、完全基于内存的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto是运行在多台服务器上的分布式系统。完整安装包括一个coordinator和多个worker。此外还有一项discovery.uri,默认情况下该发现服务是内置在coordinator中的。coordinator和worker都会注册到discovery server。coordinator可以知道worker的数量,以便分配工作,而worker可以识别出coordinator。由客户端提交查询,从Presto命令行CLI提交到coordinator。coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
- coordinator(master)负责meta管理、worker管理、query的解析和调度。
- worker则负责计算和读写。
- discovery server,通常内嵌于coordinator节点中,也可以单独部署,用于节点心跳。
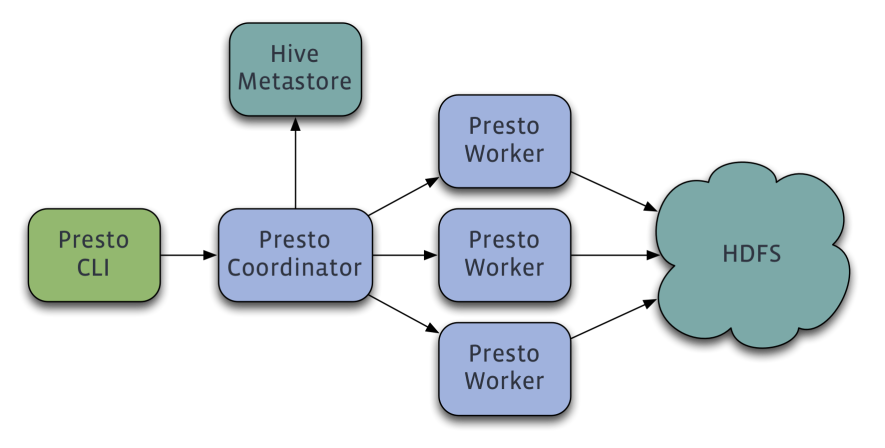
▲ 图片来源:http://prestodb.jd.com/overview.html
▲ 深色模式下请点击图片查看
360跨数据源查询引擎QuickSQL Quicksql是一款跨计算引擎的统一联邦查询中间件,用户可以使用标准SQL语法对各类数据源进行联合分析查询。其目标是构建实时或离线全数据源统一的数据处理范式,屏蔽底层物理存储和计算层,最大化业务处理数据的效率。同时能够提供给开发人员可插拔接口,由开发人员自行对接新数据源。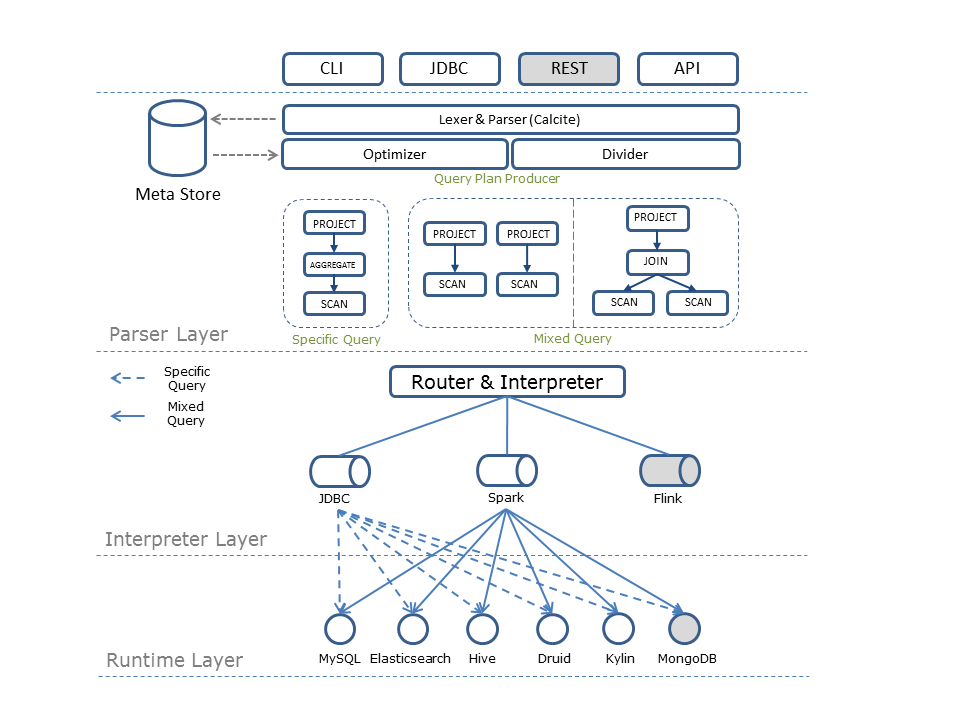 ▲ 图片来源:https://gitee.com/mirrors/Quicksql/blob/master/docs/zh/index.md
Quicksql包含三层结构:
▲ 图片来源:https://gitee.com/mirrors/Quicksql/blob/master/docs/zh/index.md
Quicksql包含三层结构:
- 语法解析层:负责 SQL 语句的解析、校验、优化、混算 SQL 的切分以及最终生成 Query Plan;
- 计算引擎层:负责Query Plan路由到具体的执行计划中,将Query Plan解释为具体的执行引擎可识别的语言;
- 数据存储层:负责数据的提取、存储;
PXF与Presto对比测试
本文将PXF和Presto进行性能对比测试,测试过程如下:
测试场景从TPCH常用的22个典型场景中随机选取8个场景进行测试,包含了带有分组、排序、聚集等操作并存的查询操作,具体的建表与查询语句可以参考标准TPCH测试工具。OLAP模型,共8个表,总数据量约为1200G,数据以parquet格式存储在HDFS上。
测试结果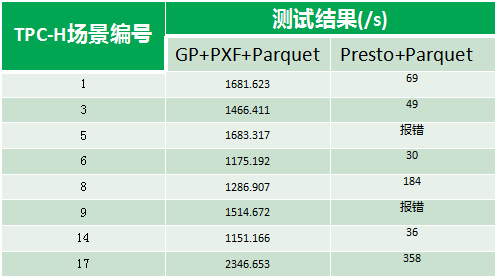 结果分析
从测试结果看,PXF与Presto测试性能差距较大的原因分析如下:
结果分析
从测试结果看,PXF与Presto测试性能差距较大的原因分析如下:
- Presto根据Hive的Metastore读取数据,在读取前对数据进行过滤;而PXF是通过tomcat服务器,从HDFS的接口中获取全量数据,将数据分布到各Segment后才真正开始执行查询。
- PXF支持的谓词下推只针对于分区表中的分区列,在本次查询场景中没有产生数据过滤效果。
- Presto是纯内存操作,获取的所有数据都缓存在内存中,查询执行较快,但是在多表join的场景下可能会由于内存不足导致查询失败而直接报错;使用PXF时,Segment读取到的数据超过配置buffer时会缓存到文件中,存在I/O交换,导致性能下降,但是带来的是每次都能查询成功。
总结
统一SQL引擎无论是在现实应用还是业务需求上都着巨大的研究价值,并且目前业界的数据虚拟引擎都有着快速的发展。我们将继续在统一SQL引擎上的探索与研究,你准备好迎接它的到来了吗?
参考文献:
https://gitee.com/mirrors/Quicksql/blob/master/docs/zh/index.md
http://vlambda.com/wz_5iJf1hzyxRM.html
https://www.oschina.net/p/360-quicksql?hmsr=aladdin1e1
http://prestodb.jd.com/docs/current/index.html
https://www.cnblogs.com/hit-zb/p/10442516.html
* 本文为中兴数据智能原创文章,转载请留言或评论获取授权。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









