





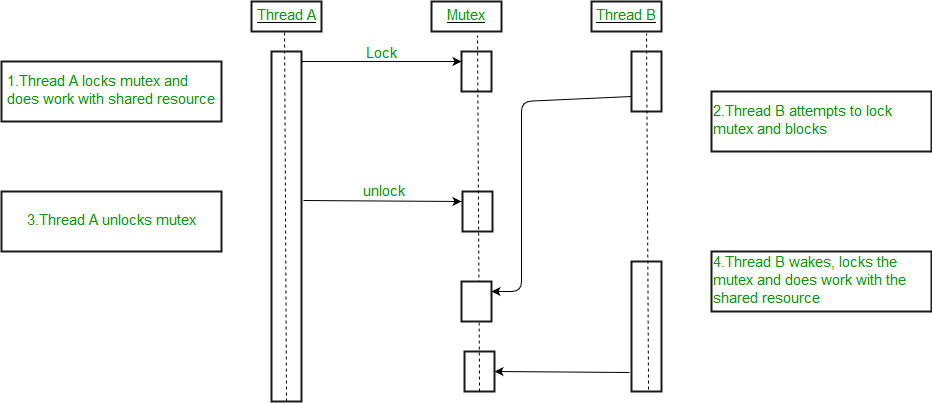
mutex可视作是spinlock的可睡眠版本,同样是线程无法继续向前执行,但spinlock是"spin",导致该CPU上无法发生线程切换,而mutex是"block"(我们通常翻译成「阻塞」),可以发生线程切换,让所在CPU上的其他线程继续执行。阻塞既可以发生在线程试图获取mutex时,也可以发生在线程持有mutex时。
描述mutex的结构体定义如下(不含debug相关部分):
struct 简单地说就是一个spinlock搭配一个代表等待队列的双向链表"wait_list",外加一个记录mutex生命周期的状态变化的"owner"。没有线程持有mutex时,"owner"的值为0,有线程持有时,需将"owner"转换为指向该线程的"task_struct"的指针。由于"task_struct"指针是按"L1_CACHE_BYTES"的字节数对齐,因而其最低的3个bits被用来存储其他信息。
struct 在早期(2016年前)的mutex实现中,使用了一个单独的"count"来记录mutex的持有情况,为1表示空闲,0表示持有,负数表示有其他线程等待。后经Peter Zijlstra的重构,将"count"要表达的意义融入"owner"中,并使用第三位的1个bit(MUTEX_FLAG_WAITERS)来表示有线程等待(参考这篇文章)。
【加锁过程】
一个线程试图获取mutex的函数是mutex_lock_interruptible(),它的前身是mutex_lock(),但由于mutex_lock()不能被信号打断,因而已经基本被废弃不用了。由于mutex可能睡眠,所以不能在中断上下文中使用,也就不存在和ISR共享变量造成死锁的问题,因而也就没有像spinlock那样的防止hardirq/softirq抢占的函数。
int might_sleep()实际上什么也不做,它只是对编程人员的一种提示,表明可能导致睡眠。如果现在没有其他线程持有mutex,那么调用这个函数的线程可立即获得mutex,即"fast path",这个同qspinlock是差不多的。
bool 就是一个简单的原子操作,把"owner"设为自己即可。
如果这个mutex正在被其他线程持有(设为线程A,对应下图CPU 0),按理该线程(设为线程B,对应下图CPU 1)应该进入"wait_list"的等待队列上,即"slow path"。
乐观的等待
但是进入slow path,等mutex可用后再被唤醒,将发生两次上下文切换,开销较大,所以线程B不甘心,它还要做一番挣扎。从乐观的角度想:线程A现在临界区,临界区的代码通常都是比较简短的,如果它不进入睡眠的话,那么大概率可以很快退出临界区,把mutex释放出来。在这段时间里,我就像spinlock一样spin等待,这样的代价肯定比进入slow path小。
这种介于fast path和slow path之间的代码路径被称为"mid path",也叫optimistic spinning(乐观锁),此时线程依然处于"TASK_RUNNING"的状态。以这种方式等待的线程可以叫做"spinner",使用它需要配置内核选项"CONFIG_MUTEX_SPIN_ON_OWNER"。。
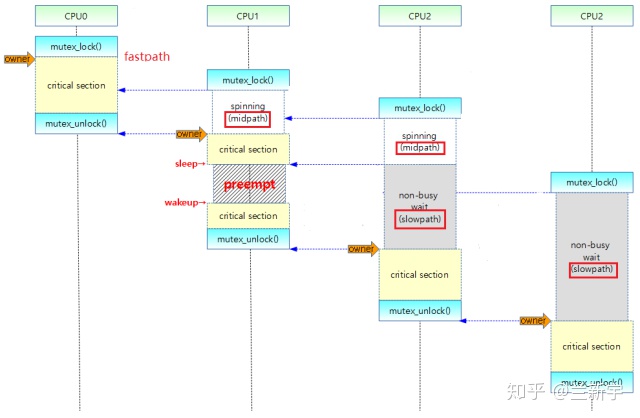
假设现在又来了一个试图获取这个mutex的线程(设为线程C,对应上图CPU 2),即便前面还有个CPU 1等着,它也会往好的一方面想:等mutex交到CPU 1手里,CPU 1在临界区内不睡眠的话,也会很快执行完啊。这就有点过分乐观了,如果spinner数目比较多的话,那排在后面的spinner会白白消耗不少CPU资源。
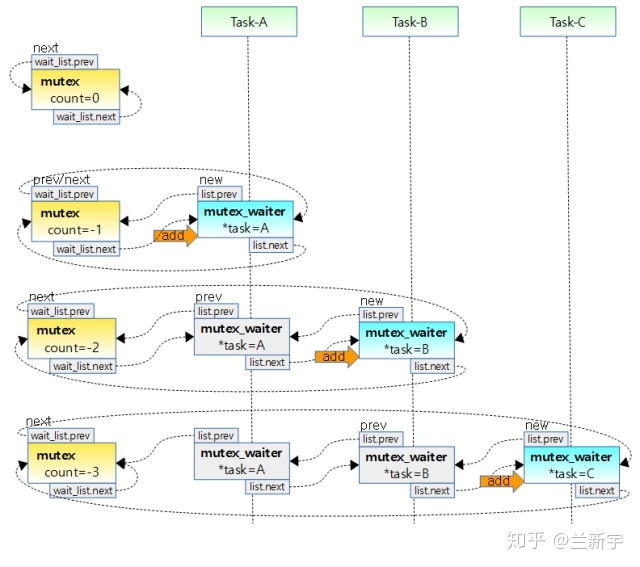
接下来,线程A退出临界区并释放mutex,线程B获取mutex后进入自己的临界区。如果线程B在执行临界区代码时被抢占了,那么线程C就只好自认倒霉,进入slow path,按照先来后到的顺序(FIFO)添加到"wait_list"上排队,并调用schedule()让出CPU,状态变更为"TASK_INTERRUPTIBLE"。使用这种方式等待的线程可以叫做"waiter"。
那spinner是如何知道持有mutex的线程被抢占了呢?它依靠的是这个"owner"线程的"task_struct"中的"on_cpu",如果"on_cpu"为0,说明该线程没有在原来的CPU上执行。
osq lock
处在mid path中的线程,对mutex的获取行为就像获取spinlock一样,此时的mutex具备了spinlock的语义,因而其等待的方式采用了一种结合MCS lock和qspinlock的实现,又根据mutex的语义量身裁剪过的osq lock。
struct mid path不是随便进的,必须满足当前CPU上没有更高优先级的线程要执行的条件(通过need_resched()判断)。
mutex_optimistic_spin否则,就算进了mid path,也会被高优先级的线程抢占(如下图CPU 1所示),这和临界区内不能抢占/调度的spinlock是不同的。
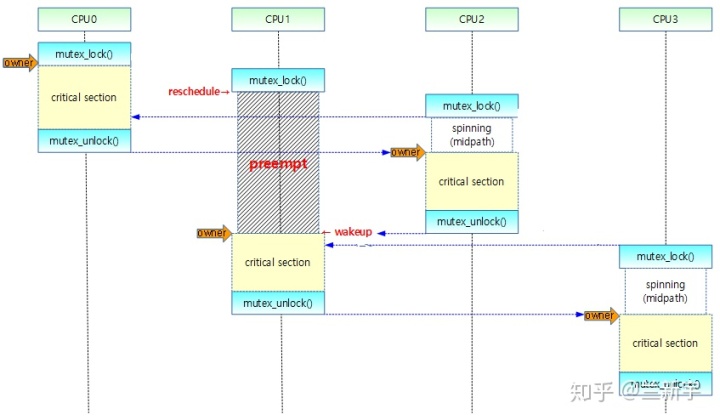
如果线程确实是进了mid path才被抢占的,那么需要从osq lock的等待队列中移除,添加到"wait_list"的slow path等待队列,身份从spinner变成了waiter。还有一种场景也会产生同样的结果,就是前面讲的spinner监测到owner线程进入了睡眠。
公平与效率
optimistic spinning机制虽然有助于提高mutex的使用效率,但同时也增加了相当的复杂性。维护的队列从1个变成了2个,而且它们之间还存在着转换。如果一个线程发现owner进入睡眠,那么只能以waiter的方式等待,之后owner结束睡眠,新来的线程就会以spinner的方式等待。
owner释放mutex后,因为spinner是处在运行态,cache也是“热”的,而waiter处在休眠态,cache大概率是“冷”的。从执行效率的角度讲,应该让spinner优先获取锁,可是这样对更早进入等待的waiter就不公平。
至此,mutex的加锁过程就介绍完了,下文将开始介绍mutex的解锁过程和死锁问题。
参考:
https://www.kernel.org/doc/Documentation/locking/mutex-design.txt
http://jake.dothome.co.kr/mutex/
LWN - Preventing overly-optimistic spinning
LWN - Reimplementing mutexes with a coupled lock
原创文章,转载请注明出处。















 1576
1576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









