





PySpark环境搭建需要以下的安装包或者工具:
Anaconda
JDK1.8
hadoop2.6
hadooponwindows-master
spark2.0
py4j
pyspark扩展包
1、hadoop
这里不详细说明Anaconda、JDK的安装与配置过程,主要说明与spark相关内容,提供的安装包:
链接:https://pan.baidu.com/s/15NBgNWCGxIQ3tA_vLLMOww
提取码:sx81
下载后:

将其进行解压,注意的是hadoop与spark这样的包无法在windows上进行运行,所以引入hadooponwindows-master包,首先我们需要对解压后的hadoop文件夹中的biN目录进行覆盖,使用hadooponwindows-master中的bin目录进行覆盖。
(1)拷贝
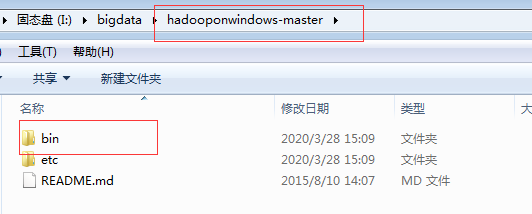
将hadooponwindows-master中的bin目录进行拷贝。
(2)覆盖
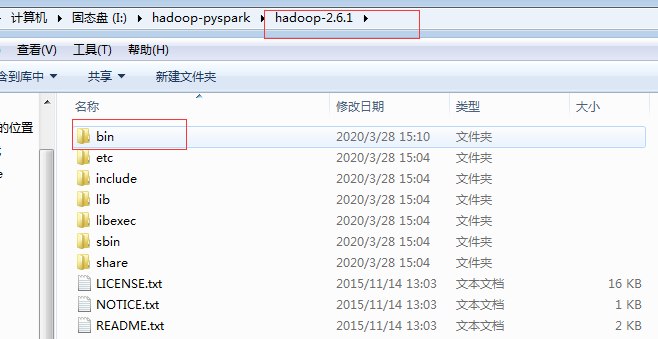
将hadoop中的bin目录进行替换
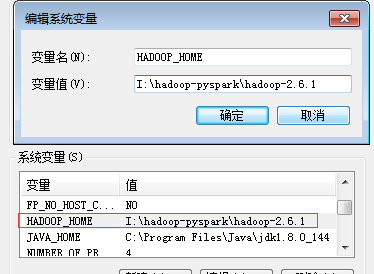
(3)系统环境变量
这里不要忘记系统环境变量的配置
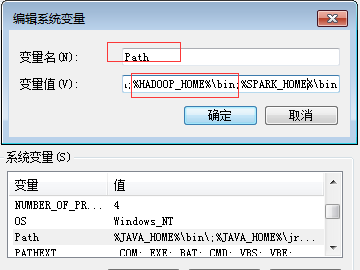
加入到path中:
2、spark
spark需要配置一下系统环境变量,与上面基本一样:
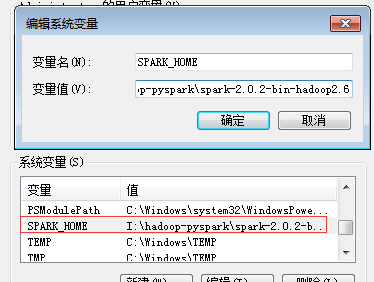
加入到path中:
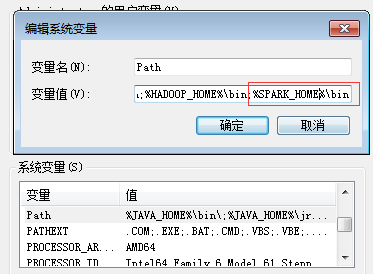
3、py4j
利用anaconda新建一个虚拟环境:
conda create -n pyspark_study python=3.5.2
进入虚拟环境安装py4j包,它是用于Java与Python进行交互使用的包:
(pyspark_study) C:\Users\Administrator>conda install py4j
4、pyspark扩展包
在上述虚拟环境的sitepackage下新建pyspark.pth文件,里面写入spark中python的路径:
(1)查看spark路径
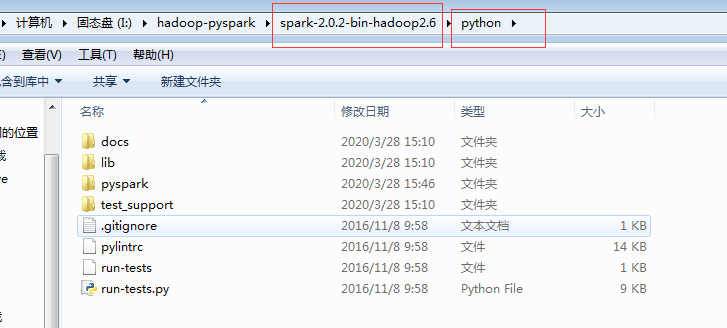
(2)安装pyspark扩展包
进入虚拟环境的sitepackage下新建pyspark.pth,并写入上述路径:
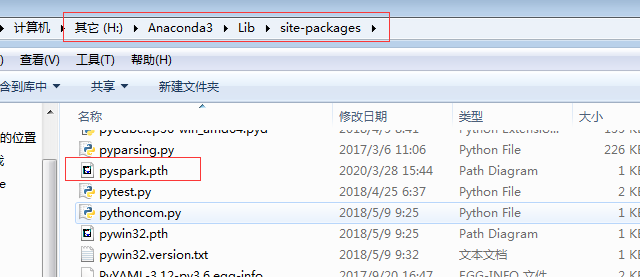
写入路径:
I:\hadoop-pyspark\spark-2.0.2-bin-hadoop2.6\python
这样环境就配置好了,此时可以在cmd命令行窗口进行启动pyspark了。
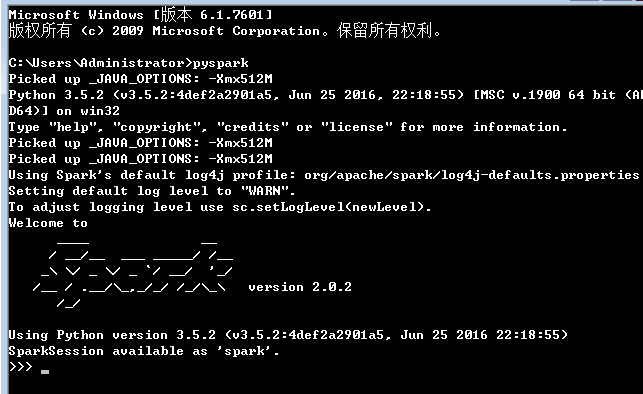
4、启动pyspark
启动命令:
C:\Users\Administrator>pyspark















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









