






(一)函数重载
1.什么是函数重载
相同作用域下,函数重载即几个功能类似的同名函数,它们具有相同的函数名,但是形参个数,形参类型,形参顺序都可以不相同且必须有一点不相同才能构成重载,而与返回值类型不相关。
2.函数重载的作用
方便使用者少记一些函数名,可以使一个函数具有处理不同数据类型的功能。
3.函数重载是如何实现的
(1)调用原理——编译器在编译期间通过推演传入的数据的类型,来判断调用哪个函数。如果推演的实参类型与形参类型完全一致则直接调用那个函数,如果不一致,则尝试隐式转换,如果无法隐式转换则报错。
(2)底层实现原理——C语言没有函数重载功能,因为C语言的编译器在编译时会把函数名改成“_函数名”,但是C++编译器会对函数名进行修改,例如linux下g++就是把函数名改为“_Z3函数名形参名形参名...”,那么相同的函数名,但是不同的形参,结果就是底层是不同的函数名,因此可以实现函数重载。
(二)引用
1.什么是引用
引用即一个变量的别名,与原变量共用同一块内存空间,引用并不是一个新的变量,编译器不会给引用分配内存空间。
2.引用的特性(与指针的区别)
引用并不是变量,而是一个别名,指针却是一个变量,存储地址。
引用在定义时必须初始化,指针可以不初始化。
引用没有多级一说,指针具有多级指针。
引用在初始化以后就不能再成为其他变量的别名。非const指针可以再指向其他变量。
一个变量可以被多个引用指向。
没有NULL引用,但是有NULL指针。即引用的初始化必须用左值来初始化。
在sizeof中,引用计算的是原数据类型所占空间的大小,而指针计算的永远是指针类型的大小。
引用++即对内存中的值进行++,指针++则是指针的值增加解引用以后类型的大小,即向后偏移一个类型的大小。
引用比指针要安全些。
访问实体时引用直接访问,而指针需要解引用。
3.引用的底层实现。
引用和指针的底层汇编代码是相同的,因此实际上引用底层也被分配了内存空间,实现和指针是类似的,只是在上层,引用被加了很多约束。见如下汇编代码
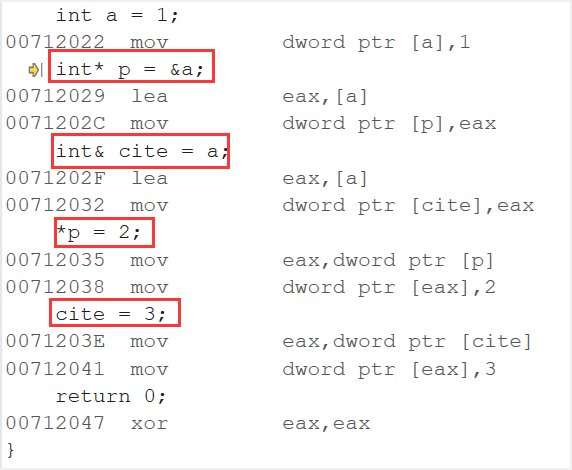
4.引用和其他知识点的联系
(1)三种传参——传值,传地址,传引用。传值与传引用和传地址最大的区别就是,传值需要拷贝原实参中的所有内容,而传引用和传地址则不涉及值拷贝的问题,只需要拷贝地址即可,消耗的空间少。传地址传引用都可以通过形参修改外部的变量内容,但是传值则不能修改外部变量内容,相对安全。如果是不想修改外部值的场景,可以传const类型。传地址和传引用最大的差别就是指针使用较复杂且代码不利于理解,引用的代码阅读更加方便且引用更加安全。
(2)引用与operator++/--的实现——
(三)宏的相关知识点
1.宏的分类及优缺点
(1)宏常量——优点:使需要替换的东西具有了意义,比如创建一个数组,给定的大小可以进行命名。且对于很多地方都要使用的相同的值,最后要修改值的时候直接修改宏就行,而不需要去代码的所有地方修改。缺点:宏常量不会对数据类型进行检查,报错的位置不准确。
(2)宏函数——优点:直接进行宏替换,减少函数调用,增加程序运行效率。缺点:1.定义宏函数时需要注意优先级问题。2.宏函数同样不会对类型进行检测,导致报错位置不准确。3.不能调试,代码膨胀。4.宏函数具有副作用。例如在传入a++时,如果宏函数中具有两个a且原意并不想修改它们,那么就会导致a被加了两次。5.宏无法按值传递。
2.C++如何解决宏的缺陷?
(1)宏常量——使用const常量解决。因为C++中的const与C语言中的const不一样。C++中用const修饰的变量会变为常量,且会在编译时就对常量进行替换。而C语言中const修饰的变量只是值无法被改变,但是依然是变量。如代码,在C语言中,虽然a被const修饰,但是依然可以将a的地址直接赋值给int*型的指针,而不是cosnt int*型,代码将会修改a中的值。但是在C++中,const修饰的a想要赋值给int*型指针,必须对其进行类型强转。C++中的代码会输出1 2,原因在于C++中的const具有宏替换的作用,在编译期间就将a替换成了1,而在运行的时候虽然a中的值被修改成了2,但是输出的a依旧是1。代码如下:
#if 0
const int a = 1;
int* p = &a;
*p = 2;
printf("%d %d", a, *p);
#endif
#if 0
const int a = 1;
int* p = (int *)&a;
*p = 2;
cout << a << ' ' << *p;
#endif
(2)宏函数——使用内联函数来解决宏函数的缺陷。使用inline来修饰函数,从而使其变成内联函数。类中的函数根据情况有时也会被编译器当做内联函数处理。内联函数同样是在调用处原地展开。但是它解决了宏函数的需要注意运算优先级的问题,没有变量类型检测的问题,无法调试的问题,以及可能出现的副作用。唯一的问题就是同样具有代码膨胀的问题。内联函数只是一个建议,如果使用inline修饰的函数中具有过多的循环以及递归则不会原地展开,依旧当做普通函数,原因在于编译完毕的程序就是一串串的机器语言指令,这些机器语言指令会被加载到内存中依次执行,因此每一条机器语言指令都会有自己的地址。在遇到循环或者判断语句时,可能就会跳到别的语句的地址处。在调用普通函数时,会立马把该调用语句的地址保存下来,然后会把函数参数复制到堆栈,跳到标记函数地址起点的内存处,执行完函数后再跳回之前保存的调用函数的指令的地址处(可能还会返回值到寄存器中)。这类似于看书时看到一个注释,于是去看注释,看完注释以后再回到文章中看到注释的地方。来回的跳跃地址意味着调用函数会造成一定的开销。因此使用内联函数可以免除这种开销,但是造成的后果就是会占用更多的内存,因为内联函数被调用的越多,在内存中存放的机器指令也就越多。因此如果内联函数中有循环,则执行函数的时间将比节约的时间多得多,这样是性价比不高的,因为内联函数会占用更多的内存。而内联函数是不允许有递归的,试想如果内联函数中含有递归,则会导致函数的循环,而不是在堆栈中再开辟空间,调用一个新的函数。最后,内联函数的定义和声明必须在同一个文件中,否则会有链接错误。















 3758
3758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









