






回顾
这一节我们再来讨论一下字符串匹配问题。在前面的章节中我们已经知道了字符串匹配问题就是从一个文本字符串中找到模式串,返回它第一次出现的位置。如果采用暴力求解的方式,我们需要先将原串和模式串对齐,然后从左往右依次比对,如果全部比对成功就返回模式字符串出现的位置;如果失败,模式串就向右移动一个单位,然后再进行比较,如果超出原串的右边界,则匹配失败,返回 -1。这种算法在最坏的情况下的复杂度为
一种猜想
暴力求解虽然能够实现这一过程,但是每次比对失败后模式字符串只向右移动了一个单位,并造成了一些重复的比对。我们可以尝试一下从右往左进行比对,如果比较失败,我们就移动整个模式串的长度。听起来这将会大大缩短比较的次数,可是事实上真是如此吗?我们还是以 DNA 配对来作为我们的例子。
首先,我们需要将 DNA 链和探针的第一个碱基对齐,然后从右往左依次比对,最后发现 A 和 G 不是互补碱基对,所以比对失败。
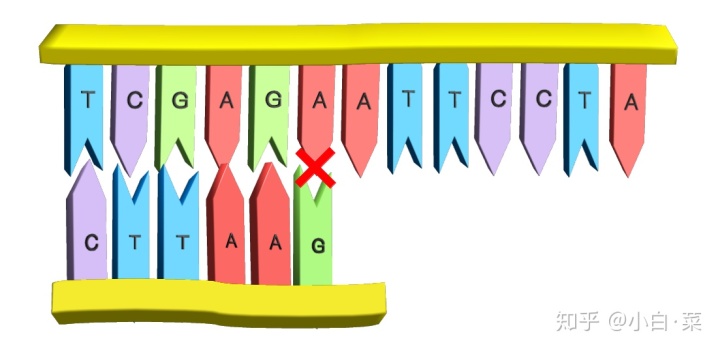
于是我们将探针向右移动跟它长度一样的单位,这里就是向右移动 6 个单位。
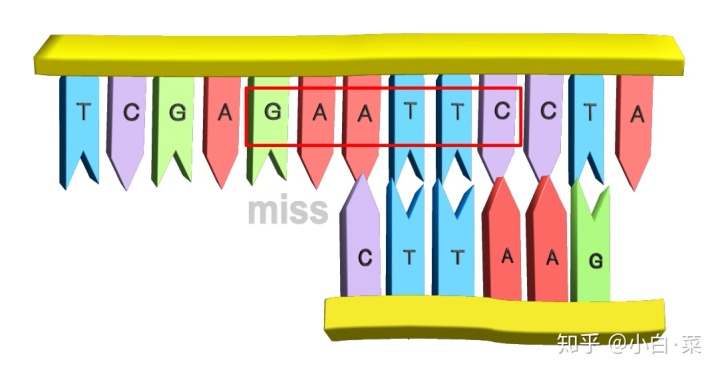
移动后发现,我们已经错过了 DNA 链和探针的匹配的位置(图中的红色长方框)。因此,直接移动一整个探针长度的方法并不可行,因此我们要对上面的猜想做一个更正。
Horspool 算法
既然移动整个探针长度可能会直接错过与 DNA 链的匹配,那么我们可以根据探针的最后一个碱基匹配到的不同碱基,来判断我们的探针到底要往右移动多少个单位。
举个例子,下图中探针的最后一个碱基匹配到的碱基为 C,如果在一次匹配中失败,由于探针除了最后一个碱基能够与 C 配对以外,前面的碱基中没有与 C 配对的碱基,所以我们移动整个探针的长度是安全的,不会造成错过的情况,因此在这种情况下我们的探针需要向右移动 6 个单位。
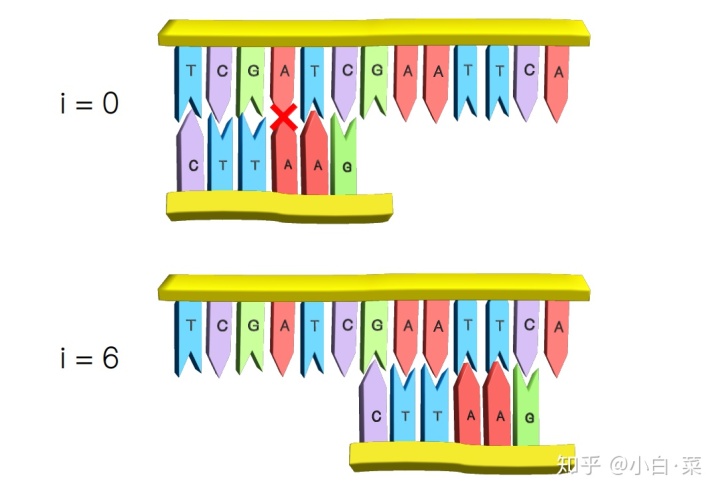
如果探针中存在与之配对的碱基,那么在匹配失败之后,探针最右侧的与之配对的碱基需要跟原碱基对齐。听起来很拗口,让我们来举一个具体的例子,假设探针的最后一个碱基匹配到的是 A,由于探针中存在两个与 A 配对的 T,根据规则,我们需要将最右侧的 T 与 A 对齐,因此探针需要向右移动 3 个单位。

同理,如果匹配到的为 T,由于探针中存在两个 A,所以使其最右者与之对齐,因而这种情况下探针需要向右移动 1 个单位。

如果匹配到的为 G,则需要向右移动 5 个单位。

这样我们就把所有的情况都讨论完了,为了表示方便,我们可以用一个表shift table来表示在不同的匹配情况下探针需要向右移动几个单位。
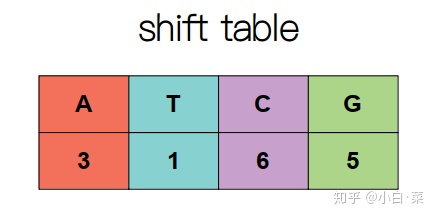
用代码来实现这个过程就是下面这个样子:
def shift_table(p, m):
table = {}
for i in range(m):
table[p[i]] = m
for j in range(m-1):
table[p[j]] = m-1-j
return tableHorspool 算法的核心思想就是构建一张查询表,然后从右往左进行比对,如果比对失败,就根据模式串的最后一个字符所对应的字符,查询shift table,决定需要向右移动的单位长度。移动后再从右往左依次比对,直到全部比对成功,或超出右边界,匹配失败。
def Horspool(text, pattern):
n = len(text); m = len(pattern)
table = shift_table(pattern, m)
i = m - 1
while i < n:
k = 0
while k < m and pattern[m-1-k] == text[i-k]:
k += 1
if k == m:
return i - m + 1
else:
i += table[text[i]] # i 递增表中对应的长度
return -1我们用一张图来完整地表示一下上述过程。

复杂度分析
因为每次比对失败后模式字符串会移动大于等于 1 个单位,所以平均情况下会优于暴力求解算法,达到线性的复杂度
shift table对 0 的情况每次只移动 1 个单位,所以暴力求解只需要比较 9 次,而 Horspool 算法则需要比较 36 次之多,因此最坏情况下 Horspool 算法的时间复杂度也会达到
→ 本节全部代码 ←
← 计数排序 | 算法与复杂度zhuanlan.zhihu.com















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









