






一、OpenCV简单介绍
在实现人脸识别之前,我们先简单了解一下OpenCv的一些基本操作。在此之前,我们需要先安装OpenCv,我们使用pip安装:
pip install opencv-python另外我们还需要另外一个模块:
pip install opencv-contrib-python接下来我们就可以学习OpenCv了。
1.1、OpenCv操作图像
我们来简单读取一个图像,并将该图像显示:
# 导入模块
import cv2
# 读取图片
im = cv2.imread('1.jpg')
# 显示图片,该方法只会显示一瞬间。(第一个参数为窗口名称,第二个参数为ndarray对象)
cv2.imshow('im', im)
# 等待键盘输入,传入毫秒值,当传入0时表示无限等待。(imshow配合该方法可以让界面一直显示)
cv2.waitKey(0)
# 因为OpenCv是用C/C++写的,所以需要释放内存
cv2.destroyAllWindows()上述代码就实现了最简单的读取并显示图像的操作了。
1.2、灰度转换
灰度就是使用黑色调表示物体,即用黑色为基准色,不同的饱和度的黑色来显示图像。 灰度转换就是将图片转换成黑白图像。因为我们在人脸识别时,灰度图像便于识别,所以我们先来了解一下。用OpenCv实现灰度转换很简单:
import cv2
# 读取图像
im = cv2.imread('1.jpg')
# 灰度转换(第一个参数为ndarray对象,第二个参数为cv2中的常量),返回一个ndarray对象
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 将grey保存
cv2.imwrite('grey.jpg', grey)
# 显示灰度转换后的图像
cv2.imshow('grey', grey)
# 等待键盘输入
cv2.waitKey(0)
# 销毁窗口
cv2.destroyAllWindows()效果如下:

1.3、绘制图形
我们后续在检测人脸的时候,我们会绘制图形,将人脸框起来。图形的绘制也非常简单,我们看如下代码:
import cv2
# 读取图像
im = cv2.imread('1.jpg')
# 在图像im上绘制矩形
"""
第一个参数为ndarray对象
第二个参数为左上角的坐标(x1, y1)
第三个参数为右下角的坐标(x2, y2)
第四个参数为颜色值,其顺序不同于我们之前的,使用的是BGR
第五个参数为线条宽度
"""
cv2.rectangle(im, (0, 0), (200, 200), (255, 255, 0), 2)
# 显示图像
cv2.imshow('im', im)
# 等待输入
cv2.waitKey(0)
# 销毁窗口
cv2.destroyAllWindows()对比图如下:

了解上面知识后,我们就可以进入下一步的学习了。
二、人脸检测
2.1、获取特征数据
开始人类检测之前,我们要先获取一个特征数据。我们先去官网,看到如下界面:
点击相应的下载后,双击安装就可以了。我们进入D:CodeFieldOpenCvopencvsourcesdatahaarcascades,前面为你opencv的安装目录。进入该文件夹后,里面全是特征文件,我们一般选用haarcascade_frontalface_default.xml。
2.1、检测人脸
我们可以把特征文件复制到我们项目下,也可以直接用绝对路径引用。我们检测人脸需要一个cv2.CascadeClassifier对象,该对象可以用来检测人脸。代码如下:
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')其中,传入参数为特征文件的路径。我们可以选择相对路径,也可以选择绝对路径。完整人类检测代码如下:
import cv2
# 加载特征数据
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 读取图片
im = cv2.imread('1.jpg')
# 检测人脸,返回人脸的位置信息
faces = face_detector.detectMultiScale(im)
# 遍历人脸
for x, y, w, h in faces:
# 在人脸区域绘制矩形
cv2.rectangle(im, (x, y), (x+w, y+h), (255, 255, 0), 2)
# 显示图像
cv2.imshow('im', im)
cv2.waitKey(0)
cv2.destroyAllWindows()其中detectMultiScale方法返回一个ndarray对象,这个对象保存了n张人脸的左上角坐标、脸的宽、脸的高。检测效果如下:

不过有时会有一些误差,大多数清晰人脸可以正常检测到。
三、人脸识别
上面的内容我们已经说了人脸检测的实现,那人脸识别和人脸检测有什么区别呢?它们的区别在于,人脸检测是要确定一张图像里面有没有人脸,而人脸识别则是要确定图像中的人脸是谁。不过要确定是谁之前,我们需要先见过人脸的主人,这就需要我们训练数据了。
3.1、训练数据
训练数据主要有两个部分,人脸信息和标签,其中标签为int列表。我在目录gtx中准备了50来张钢铁侠图片,为了方便获取标签,我们先编写如下代码:
import os
path = "./gtx/"
# 获取文件列表
paths = os.listdir(path)
i = 0 # 循环变量
for file in paths:
i += 1
# 将文件重命名
os.rename(path+file, path + str(i) + str(1) + ".jpg")这段代码就是遍历当前目录下gtx文件夹下的图片,将图片名称改为数字+1+.jpg格式。
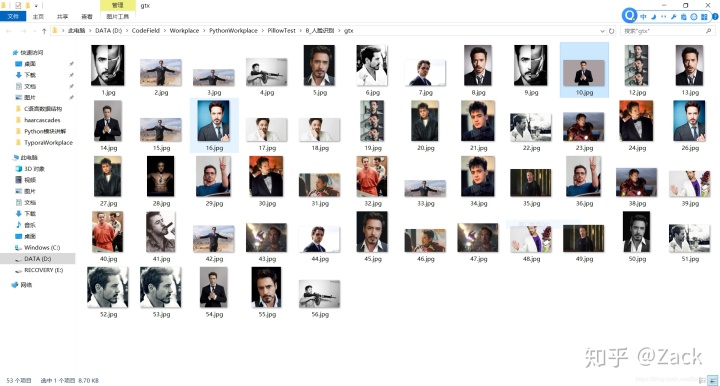
上面是我用爬虫爬取的一些图片,我们将这些使用上述代码转换成数字+1+.jpg格式,我们把1做为小罗伯特唐尼的标签,我们可以继续多把其他人的人脸改为数字+2+.jpg格式,这样就可以做到区分。不过上述代码有一个问题,即当我们遍历到第四个图片时,名称需要改为41.jpg,而在我的文件夹中已经存在41.jpg,所以会产生错误。我们将代码改为如下:
import os
path = "./gtx/"
paths = os.listdir(path)
i = 0
for file in paths:
i += 1
try:
os.rename(path + file, path + str(i) + str(1) + ".jpg")
except Exception as e:
print(e)
# 当发生异常时,直接跳过
continue准备好图像后,我们就可以开始训练数据了,训练数据代码如下:
import cv2
import os
import numpy
root_path = "./gtx/"
def getFacesAndLabels():
"""读取图片特征和标签"""
global root_path
faces = []
lables = []
# 获取人脸检测器
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 获取图片路径
files = os.listdir(root_path)
for file in files:
path = root_path + file
# 读取图片
im = cv2.imread(path)
# 转换灰度
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 读取人脸数据
face = face_detector.detectMultiScale(grey)
for x, y, w, h in face:
# 设置标签,分离文件名称
lables.append(int(file.split('.')[0]))
# 设置人脸数据
faces.append(grey[y:y+h, x:x+w])
return faces, lables
# 调用方法获取人脸信息及标签
faces, labels = getFacesAndLabels()
# 获取训练对象
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 训练数据
recognizer.train(faces, numpy.array(labels))
# 保存训练数据
recognizer.write('./trainer/trainer.yml')在上面代码中,我们上面的并没有对文件名称中的最后一个数字1进行区分,后续会使用到。关于训练数据,大家可以多准备一些人物和图片。
3.2、人脸识别
我们训练完数据后,就可以进行人脸识别了。在识别之前我们先加载训练数据,然后就是基本的人类检测步骤。最后我们调用predict方法进行人脸识别,在训练数据中匹配人物。
import cv2
# 加载训练数据集
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('./trainer/trainer.yml')
# 准备识别的图片
im = cv2.imread('1.jpg')
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 检测人脸
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
face = face_detector.detectMultiScale(grey)
for x, y, w, h in face:
# 返回人脸标签和可信度,可信度数值越低,可信度越高(用词不当,不要在意)
label, confidence = recognizer.predict(grey[y:y+h, x:x+w])
# 这里将60作为界限,当检测检测值为60时,我们就确定人物
if confidence <= 60:
if label % 10 == 1:
print('小罗伯特唐尼')
elif lable % 10 == 2:
pass
else:
print("未匹配到数据")
cv2.imshow('im', im)
cv2.waitKey(0)
# 销毁窗口
cv2.destroyAllWindows()上述代码中,我们用标签label%10,可以获得文件最后一个数字,这样就可以达到区分人物的作用,我们用如下图片进行测试。

输出结果如下:
小罗伯特唐尼
1算是成功了,多次测试后,发现准备率方面比较中规中矩。大家可以尝试多准备写图片用来训练,从而提高准确率。代码已上传GitHub:IronSpiderMan/GtxFaceDetector














 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









