





曾经有个名人说过:”GTA是个好游戏,你们一定要玩好它“。事实上GTA5除了是一个好游戏,还是一个绝佳的debug the world 的simulator。在上面做无人车驾驶训练早已不是新闻,最近看到一篇CVPR2019 - Learning from Synthetic Data for Crowd Counting in the Wild ,发现GTA5另一个用:合成人群技术样本造假。
真实数人头数据集标注过于麻烦,常见数据集图像并不多,网络训练易陷入过拟合。作者基于Hook v 开发GTA5的一个Mod,模拟各种天气、时间、地点、摄像角度、高度、城市乡村建筑等人群图像,都可以精准标注。但渲染的游戏场景和现实世界的总归属于完全不同domain,作者参考修改了cycleGAN 这种无监督的domain间转换,将GTA风格转换到上海世博会和UCF数据集的风格。

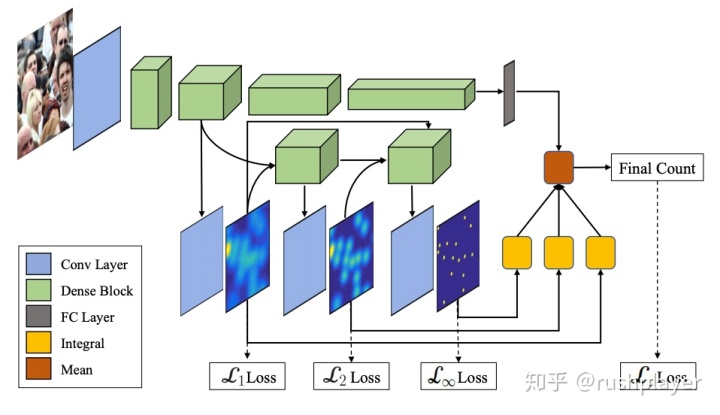
有了更多的素材接下去就是常规的深度学习训练了,架网络设loss设策略。看作者开源的代码,采用pytorch自带的resnet101 前部分作为encoder,然后在1/8分辨率下面一顿处理,包括这种采用1x9 和9x1卷积核的骚操作,最后直接把图放大8倍当做密度图(没有包括deconv和conv 的decoder),所有像素值加一加就是总人数,loss直接用两张密度图的mseloss。感觉UCF QNRF那个官方demo更合理一些,多个loss。
实验
拿作者的pretrained网络,对上周的郭台铭和韩国瑜造势场合数人头。关注台湾选举的小朋友都清楚,每次选举造势的到场人数是最重要的一个指标,现在空拍无人机广泛利用,除了用密度和面积来估计人数,用AI来数人头也算是新鲜。实验结果17398:3870. 果冻稳了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









