






导读
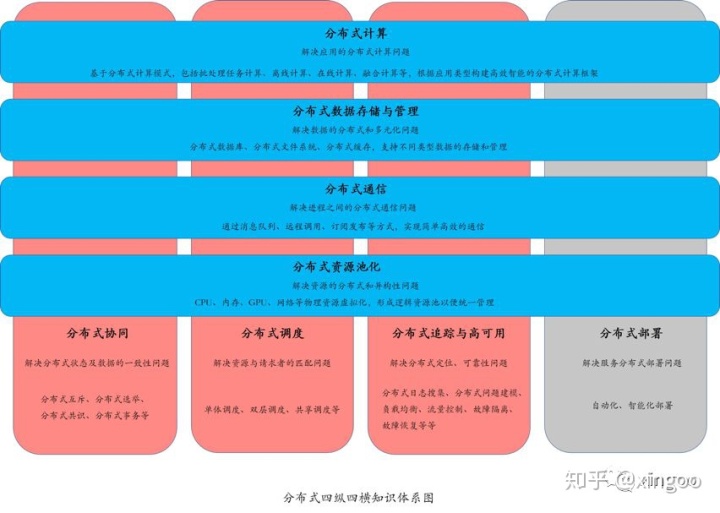
最近刚刚完结《分布式算法原理》的学习,特意总结下时长回顾复习。学习完这门课程的最大收获就是之前混乱的知识体系现在变得更清晰了,作者把整个分布式体系总结成了四横四纵,按照领域的不同可以划分成分布式计算、存储、通信、资源池化,而每一部分又涉及到分布式的协同、调度、追踪高可用、部署。
本篇就挑重点总结下分布式协同相关的内容。
1 分布式互斥
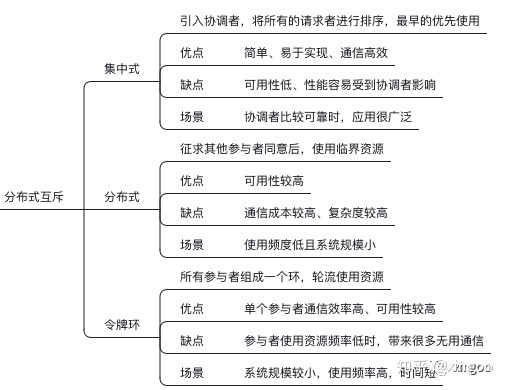
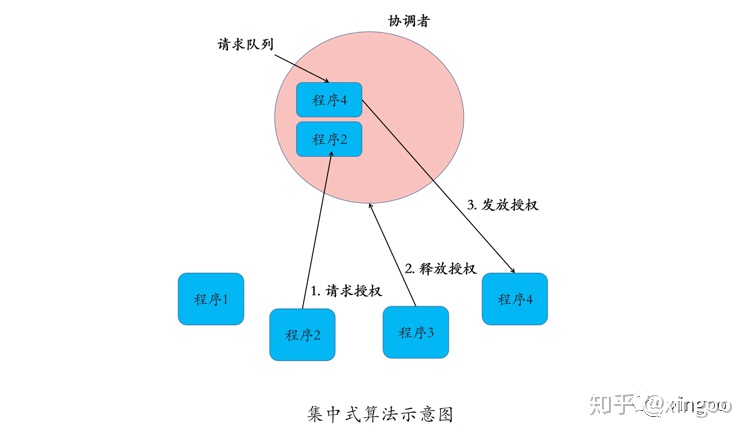
1.1 集中式算法
集中式算法引入中央协调者,参与者向协调者发送执行请求;协调者内部采用队列维护申请列表,内部按照FIFO或者优先级的顺序批准执行。优点:简单高效;缺点:协调者可能会成为瓶颈。一般在使用时,都会搭配一些高可用的措施,避免协调者成为瓶颈。比如使用zookeeper这种高可用的框架实现协调者。
1.2 分布式算法
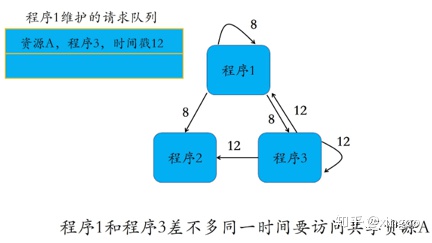
这种算法中,每个节点都是等价的(不存在协调者与参与者的关系)。每个参与者想要申请某个资源都要向其他的所有节点发起请求,当所有节点同意后才能执行。优点:相比集中式不存在单点问题;缺点:通信成本比较高。一般都是在系统规模较小,P2P(对等模式)模式的场景。
比如下面的流程中,程序1在时间戳8时申请资源,程序23都同意;程序3在时间戳12时申请资源,此时程序1正在使用,因此阻塞放入请求队列中,程序3阻塞等待;等程序1执行完成后,再同意程序3的请求,程序3继续执行。
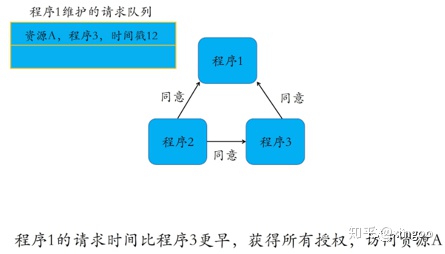
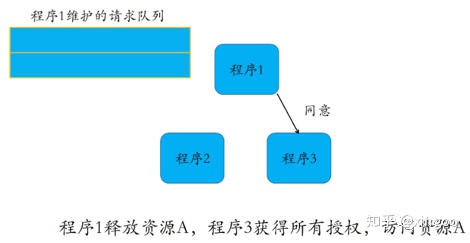
1.3 令牌环算法
这种算法中所有节点组成一个环,轮流使用资源。优点:通信效率较高,每个节点只需要与相邻节点通信;缺点:参与者使用频率低时,效率比较低。这种一般适合规模不大,每个参与者只使用一小段时间的资源的场景。
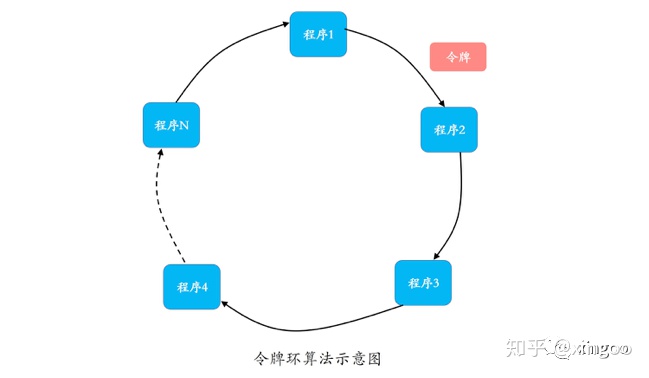
2 分布式选举
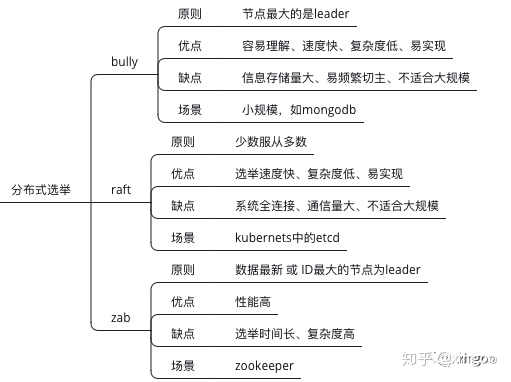
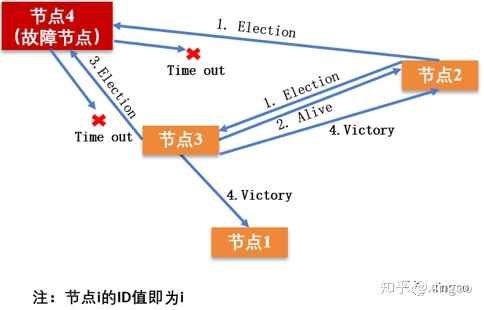
2.1 bully算法
在这种算法中,每个节点都有自己的编号,哪个节点的编号最大,它就是主节点。一般的流程是,每个节点向比自己大的节点发送election消息;如果节点判断自己的id最大,则向其他的节点发送victory消息宣布自己是主节点。这种算法优点是容易理解,速度快;缺点是新加入的节点或者最大ID节点如果频繁启停,都会导致集群频繁更换主节点。
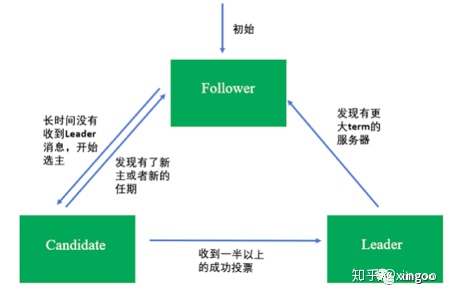
2.2 Raft协议
这个算法核心的思想就是多数派投票,比如5个人中3个人想法一致,就按这个想法来。在算法中包含三种角色:leader(主节点,负责协调服务)、candidate(候选者,在参与选举发起投票时,由follower进化而来),follower(跟随者,负责进行投票)。集群启动的时候,所有人都是follower,每个节点会有一个随机时间,当时间到时,节点变化为candidate,并发起投票。当其他人收到投票,多数的那个升级为leader。然后不断的向其他节点发起心跳,心跳到达时会刷新对应节点的时间。这个算法的优点是速度很快;缺点是通信量比较大。目前采用这个算法有kubernets的etcd以及tidb。
2.3 ZAB协议
ZAB,全称是Zookeeper Atomic Broadcast,zk原子广播协议。它可以理解成是前面id最大算法的进化版,每个节点维护三元组<选举周期、server id、数据id>,按照数据优先>server id的方式进行选举。优点是性能高,缺点是选举的时间比较长,复杂度比价高。
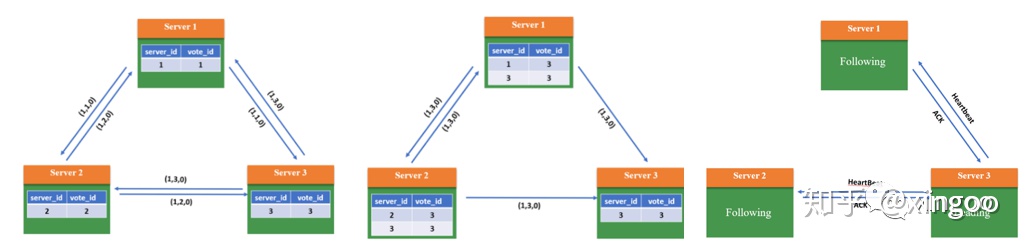
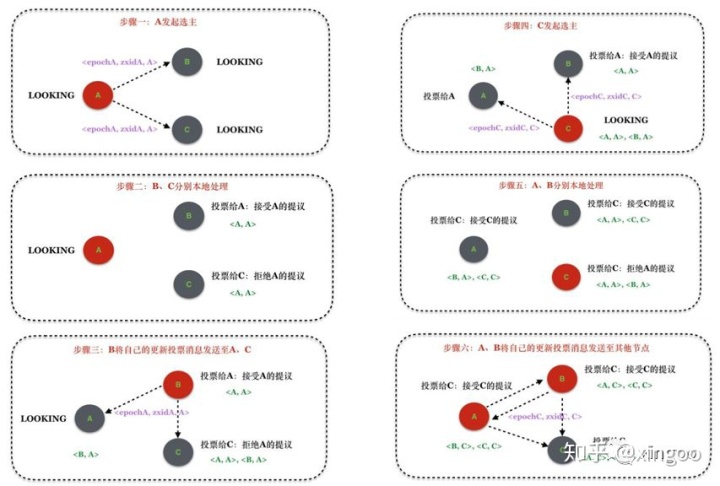
下面是一个三节点的ZAB选举过程:
3 分布式事务
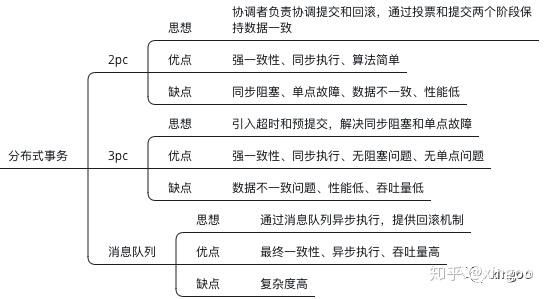
传统的事务定义是ACID, A(atomic,原子性,要么全成功,要么全失败);C(consistency,一致性,前后要保证数据的完整性);I(Isolation,隔离性,多个事务互相不干扰);D(Durability,持久性,一旦事务完成,就会被记录下来)。
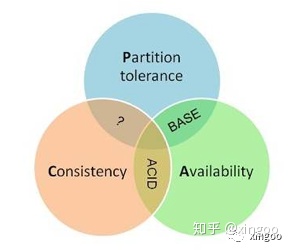
在分布式环境中,维持ACID变得更为复杂,并且提出在数据的一致性以及可用性和分区容错性之间无法同时满足三个。其中CAP分别指一致性(所有副本数据一致)、可用性(在一定时间内返回)、分区容错性(网络发生故障,其他服务正常)。后来在牺牲一致性的前提下,提出了BASE理论:基本可用(功能或者响应时间上的降级)、软状态(数据可以出现短暂的不一致)、最终一致性(在一定时间后,数据会保持一致)。经典的分布式事务算法包括:2PC,3PC,基于消息中间件的事务。
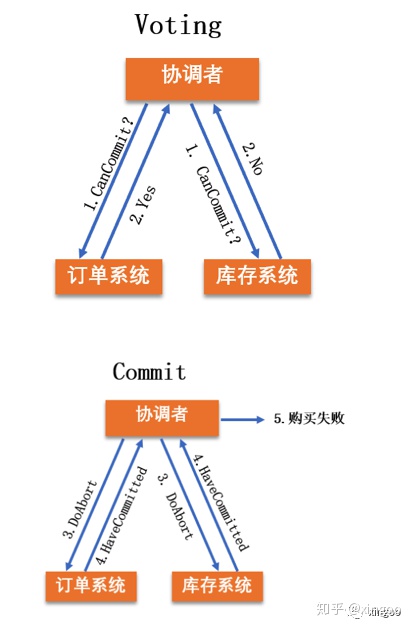
3.1 2PC
2PC也叫做two phase commit,主要包含两个阶段:发起阶段(协调者向各个节点发起请求,全部通过才执行);执行阶段(根据反馈决定是否执行还是放弃)。这个算法的优点是简单、强一致性、同步执行;缺点是同步阻塞问题、协调者容易出现单点故障、数据容易出现不一致、性能低。
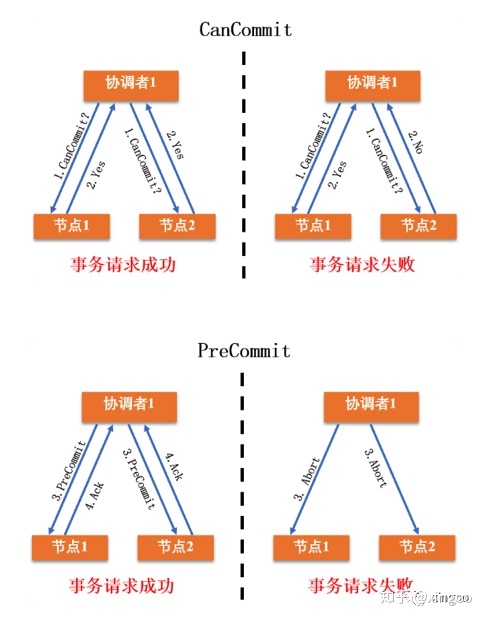
3.2 3PC
为了解决2PC中的超时和不一致问题,在3PC中引入两个优化:超时和提前预提交阶段。在第1阶段与2PC差不多;在第2阶段,进行预提交;在第3阶段进行真正的提交。引入预提交后,如果协调者超时下线,此时参与者就能直接提交事务了。
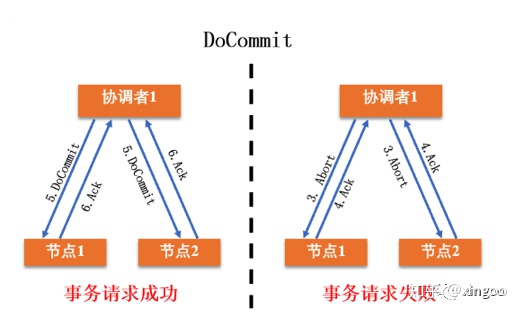
3.3 基于消息队列的事务
在业务系统中这种分布式事务的做法比较常见,比如几个模块系统需要互相依赖,就可以通过消息队列进行解耦。
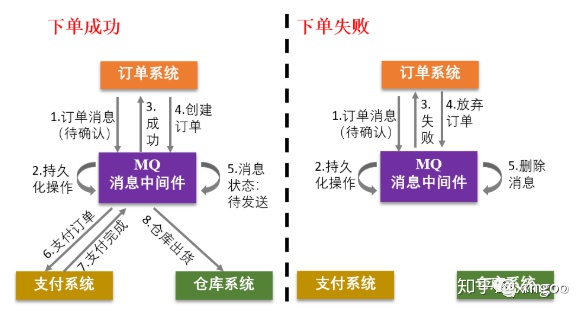
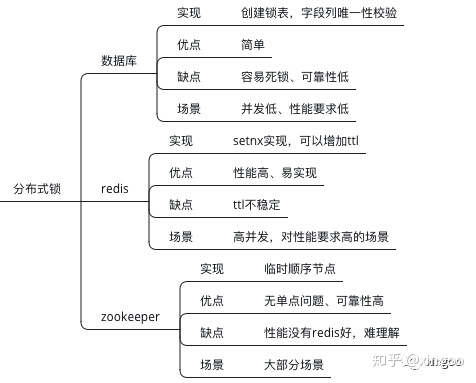
4 分布式锁
4.1 基于数据库的分布式锁
通过创建一个锁表,锁表中包含一个唯一性校验的id列,每次申请锁时都在表中创建一条记录。优点是简单;缺点是容易出现单点故障,如果删除不及时容易出现死锁问题。
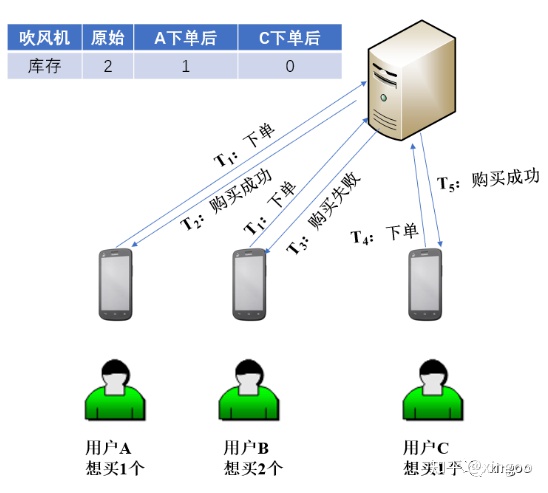
4.2 基于Redis的分布式锁
基于setnx预发可以判断是否设置成功,成功代表抢到锁。也可以配置TTL,这样就解决了死锁的问题。优点是简单,引入超时机制,避免死锁;缺点是优点粗暴,容易错误释放。
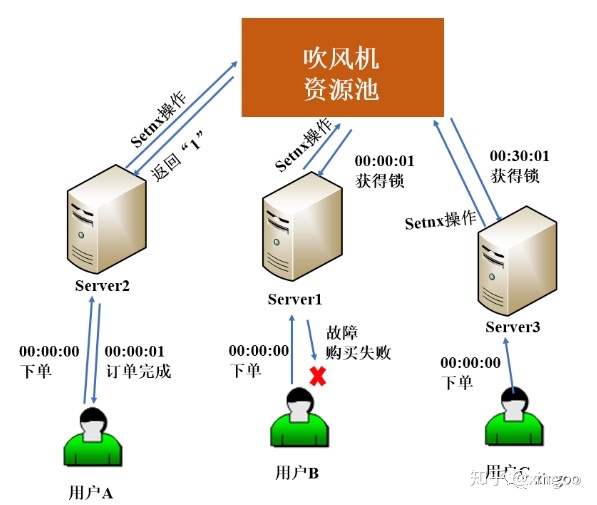
4.3 基于zookeeper的分布式锁
zookeeper中包含永久节点、永久顺序节点、临时节点、临时顺序节点。可以通过临时顺序节点实现读写锁分离的分布式锁。即在某个资源目录下创建临时顺序节点,判断其中的存储内容分辨是读锁还是写锁,从而实现锁的读写分离。优点是解决了单点故障、不可重入、死锁等问题;缺点是频繁删除新增节点,性能不如redis。
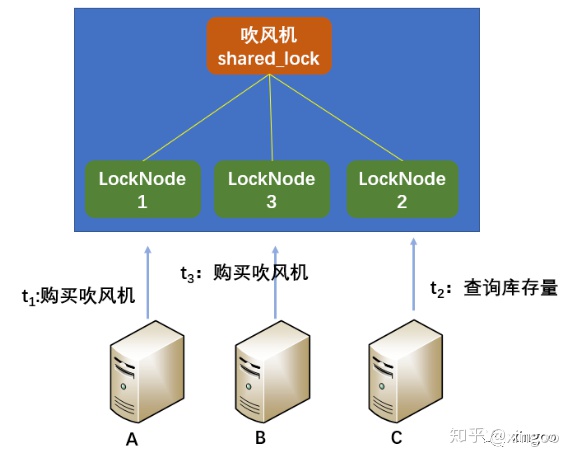
以上就是分布式协同的内容,从互斥、选举、事务、锁等几个方面介绍了分布式中常用的算法和方法。
















 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









