





上次我们学习了文本分析中重要的一些技术和理论,包括中文的分词和词性的标注,也说明了关键字提取的重要性。我们可以通过词性,词频,TF-IDF等方式来过滤关键词。
今天我们利用上次学习到的知识,来完成一个文本挖掘的实际应用——文本分类。
未经许可请勿转载
更多数据分析内容参看这里
一. 文本分类基本流程
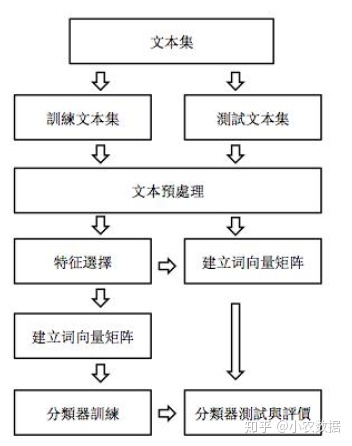
文本分类是用计算机对文本集按照一定的分类体系或标准进行自动分类标记的过程。文本分类的主要环节如下:文本集首先会分为训练和测试集。对于训练集,文本预处理包括分词,词性标注,过滤关键词。然后根据训练集做特征选取,从而构建词的向量矩阵,一个词对应一个特征。建完词向量矩阵非结构化就成为结构化数据,然后透过分类器训练我们的文本。对于测试集,同样首先经过文本预处理,然后利用训练集上筛选的特征,构建起测试集的词向量矩阵,然后利用分类器进行测试,并对结果进行评价。
二. R语言文本分类实践
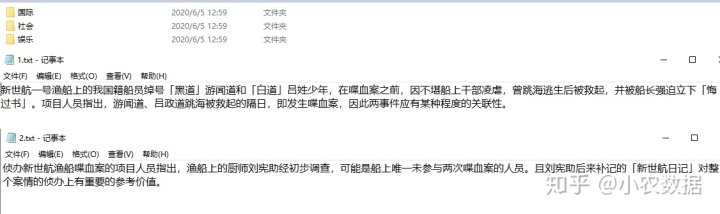
我们的训练集一共有五篇文章,分为国际、社会、娱乐三个类型,如下所示。这些数据一般可以通过爬虫取得。测试数据集同样有五篇文章,可以分为三个类型。
- 数据预处理处理
(1)训练集数据预处理
library(jiebaR)
library(stringr)
# 繁简体
chineseType <- 'simplifiedChinese'
#traditionalChinese
#simplifiedChinese
# Working Directory
wd <- 'E:/data/wbfx'
user_dic <- paste(wd,'/data/textClassification/simplifiedChinese/user.dict.utf8', sep = '')
stop_word <- paste(wd,'/data/stop_s.txt', sep = '')
# 建立分词引擎,type="tag" 带词性标注
mixseg <- worker(stop_word = stop_word, user = user_dic, type = "tag")
# 训练文本集路径
trlibrAd <- paste(wd,'/data/textClassification/',chineseType,'/train',sep = '')
# 测试文本集路径
telibrAd <- paste(wd,'/data/textClassification/',chineseType,'/test',sep = '')
# ---------------------------------------------------------------------------
# 训练文本集处理
trlib <- data.frame()
counter <- 1
for(i in dir(trlibrAd))
{
# 类别路径
classAd <- paste(trlibrAd, '/', i, sep = '')
for(j in dir(classAd))
{
# 文档路径
docAd <- paste(classAd, '/', j, sep = '')
# 文档读取
doc <- readLines(docAd, encoding = 'UTF-8')
print(docAd)
seq_doc <- NULL # Word Segmentation Results
seq_tag <- NULL # POS Tagging Results
for(k in 1:length(doc))
{
# 中文分词
w <- segment(as.vector(doc[k]), mixseg)
#合并段落
seq_doc <- c(seq_doc, w)
# 词性标注
t <- names(tagging(as.vector(doc[k]), mixseg))
seq_tag <- c(seq_tag , t)
# 分词 & 词性 Print
print(paste(str_c(w, t, sep="|"), collapse = " "))
}
print('-----------------------------------------------------------------')
# 分词 & 词性 Save
seq <- data.frame(seq_doc, seq_tag)
#词性过滤 (Just Reserve Noun)
seq <- seq[seq_tag=='n'|seq_tag=='nr'|seq_tag=='nrt'|seq_tag=='ns'|seq_tag=='nt'|seq_tag=='nz',]
#统计词频
seq_doc <- table(as.character(seq$seq_doc))
#去除数字
seq_doc <- seq_doc[!grepl('[0-9]+', names(seq_doc))]
#文本名、类别
seq_doc <- data.frame(seq_doc, textName = j, clas = i)
trlib <- rbind(trlib, seq_doc)
counter <- counter + 1
}
}

counter <- counter - 1
# trlib <- tbl_df(trlib)
names(trlib)[1] <- 'Keywords'
names(trlib)[2] <- 'Frequency'
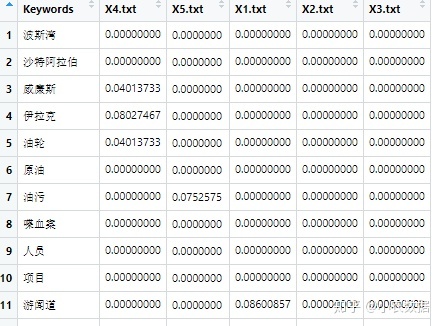
DF <- c(table(trlib$Keywords)) #词出现的不同文章的篇数
FM <- unique(trlib[c("textName", "clas")]) #每篇文章类别
library(reshape2)
TCM <- acast(trlib, Keywords ~ textName, value.var='Frequency', fill=0, drop=FALSE, sum) #统计词在每一个文章中出现的次数
TCB <- ifelse(TCM>0, 1, 0) # 统计词是否在每一个文章中出现
selectedKW <- rowSums(TCM) >= 2 #只选择总出现次数大于1的词
TCM <- as.data.frame(TCM[selectedKW,]) #根据筛选后的结果重新统计每个词在文件出现次数
TCB <- as.data.frame(TCB[selectedKW,]) #根据筛选后的结果重新统计每个词在文件出现与否
DF <- DF[selectedKW] #根据筛选后的结果重新统计每个词不同文章的篇数
IDF <- log10(counter / DF) # 每个词计算IDF值
cbind(rownames(TCM), IDF)
TTF <- colSums(TCM) #计算每一篇文章总的词汇数
TCM_IDF <- t(t(TCM) / TTF) * IDF # 计算最终调整后的TCM_IDF值
TCM <- data.frame(Keywords = rownames(TCM), TCM)
rownames(TCM) <- NULL
TCM_IDF <- data.frame(Keywords = rownames(TCM_IDF), TCM_IDF)
rownames(TCM_IDF) <- NULL
TCB <- data.frame(Keywords = rownames(TCB), TCB)
rownames(TCB) <- NULL
(2)测试数据预处理
# 测试资料处理
telib <- data.frame()
counter <- 1
for(i in dir(telibrAd))
{
# 类别路径
classAd <- paste(telibrAd, '/', i, sep = '')
for(j in dir(classAd))
{
# 文档路径
docAd <- paste(classAd, '/', j, sep = '')
# 文档读取
doc <- readLines(docAd, encoding = 'UTF-8')
print(docAd)
seq_doc <- NULL # Word Segmentation Results
seq_tag <- NULL # POS Tagging Results
for(k in 1:length(doc))
{
# 中文分词
w <- segment(as.vector(doc[k]), mixseg)
seq_doc <- c(seq_doc, w)
# 词性标注
t <- names(tagging(as.vector(doc[k]), mixseg))
seq_tag <- c(seq_tag , t)
# 分词 & 词性 Print
print(paste(str_c(w, t, sep="|"), collapse = " "))
}
print('-----------------------------------------------------------------')
# 分词 & 词性 Save
seq <- data.frame(seq_doc, seq_tag)
#词性过滤 (Just Reserve Noun)
seq <- seq[seq_tag=='n'|seq_tag=='nr'|seq_tag=='nrt'|seq_tag=='ns'|seq_tag=='nt'|seq_tag=='nz',]
#统计词频
seq_doc <- table(as.character(seq$seq_doc))
#去除数字
seq_doc <- seq_doc[!grepl('[0-9]+', names(seq_doc))]
#文本名、类别
seq_doc <- data.frame(seq_doc, textName = j, clas = i)
telib <- rbind(telib, seq_doc)
counter <- counter + 1
}
}
counter <- counter - 1
names(telib)[1] <- 'Keywords'
names(telib)[2] <- 'Frequency'
DF <- c(table(telib$Keywords))
FM <- unique(telib[c("textName", "clas")])
library(reshape2)
eTCM <- acast(telib, Keywords ~ textName, value.var='Frequency', fill=0, drop=FALSE, sum)
eTCB <- ifelse(eTCM>0, 1, 0)
selectedKW <- rowSums(eTCM) >= 2
eTCM <- as.data.frame(eTCM[selectedKW,])
eTCB <- as.data.frame(eTCB[selectedKW,])
DF <- DF[selectedKW]
IDF <- log10(counter / DF)
cbind(rownames(eTCM), IDF)
TTF <- colSums(eTCM)
eTCM_IDF <- t(t(eTCM) / TTF) * IDF
eTCM <- data.frame(Keywords = rownames(eTCM), eTCM)
rownames(eTCM) <- NULL
eTCM_IDF <- data.frame(Keywords = rownames(eTCM_IDF), eTCM_IDF)
rownames(eTCM_IDF) <- NULL
eTCB <- data.frame(Keywords = rownames(eTCB), eTCB)
rownames(eTCB) <- NULL
2. 训练词向量矩阵
colnam <- TCM$Keywords
TCM$Keywords <- NULL
TCM <- as.data.frame(t(TCM))
colnames(TCM) <- colnam
rownames(TCM) <- FM$textName
TCM$clas <- FM$clas

# 测试资料词向量矩阵阵
colnam <- eTCM$Keywords
eTCM$Keywords <- NULL
eTCM <- as.data.frame(t(eTCM))
colnames(eTCM) <- colnam
rownames(eTCM) <- FM$textName
eTCM$clas <- FM$clas
3. 分类器训练
# Build CART Model without Pruning
library(rpart)
library(rpart.plot)
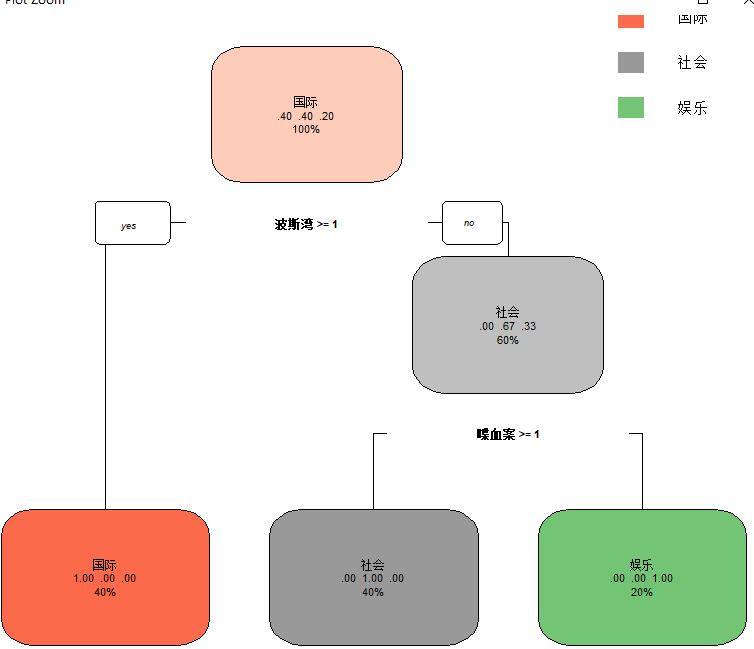
CART.tree <- rpart(clas ~ ., data=TCM,
control=rpart.control(minsplit=2, cp=0))
rpart.plot(CART.tree)
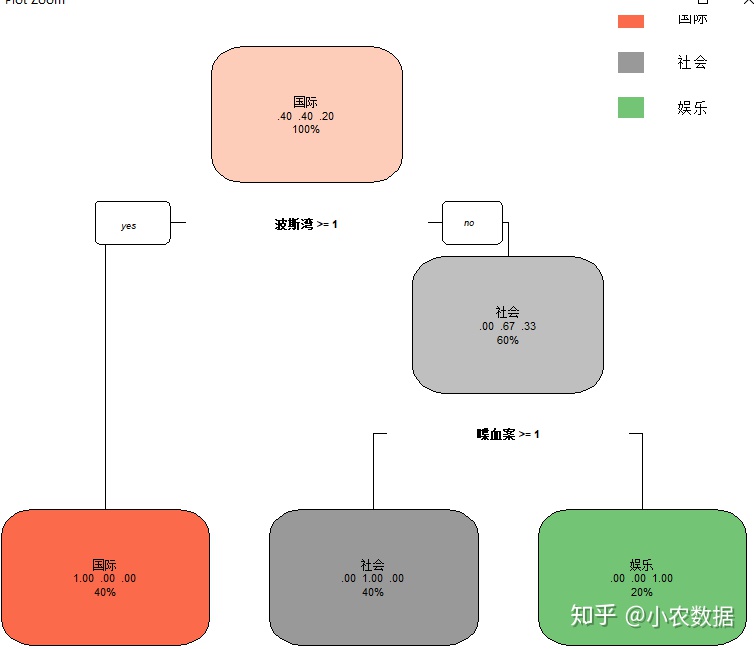
4. 预测和评价
# Make Predictions
CART.Prediction <- predict(CART.tree, newdata=eTCM, type='class')
cbind(CART.Prediction, predict(CART.tree, newdata=eTCM, type='prob'), eTCM$clas)
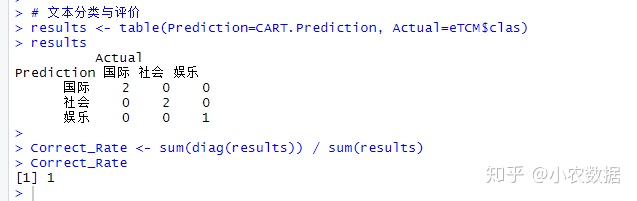
# 文本分类与评价
results <- table(Prediction=CART.Prediction, Actual=eTCM$clas)
results
Correct_Rate <- sum(diag(results)) / sum(results)
Correct_Rate

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









