





tfdbg 是 TensorFlow 的专用调试程序。借助该调试程序,您可以在训练和推理期间查看运行中 TensorFlow 图的内部结构和状态,由于 TensorFlow 的计算图模式,使用通用调试程序(如 Python 的 pdb)很难完成调试。
本指南重点介绍 tfdbg 的命令行界面 (CLI)。要了解如何使用 tfdbg 的图形界面 (GUI)(即 TensorBoard 调试程序插件),请访问相关 README 文件(https://github.com/tensorflow/tensorboard/blob/master/tensorboard/plugins/debugger/README.md)。
注意:TensorFlow 调试程序使用基于 curses 的文本界面。在 Mac OS X 上,ncurses 库是必需的,而且可以使用 brew install ncurses 进行安装。在 Windows 上,curses 并没有得到同样的支持,因此基于 readline 的界面可以与 tfdbg 配合使用(具体方法是使用 pip 安装 pyreadline)。如果您使用的是 Anaconda3,则可以使用 "C:\Program Files\Anaconda3\Scripts\pip.exe" install pyreadline 等命令进行安装。您可以在此处下载非官方 Windows curses 软件包,然后使用 pip install .whl 进行安装;不过,Windows 上的 curses 可能无法像 Linux 或 Mac 上的 curses 一样稳定地运行。
本教程展示了如何使用 tfdbg CLI 调试出现 nan 和 inf 的问题,这是 TensorFlow 模型开发期间经常出现的一种错误。下面的示例适用于使用低阶 TensorFlow Session API 的用户。本文档的后面部分介绍了如何将 tfdbg 与 TensorFlow 的更高阶 API(包括 tf.estimator、tf.keras / keras 和 tf.contrib.slim)结合使用。要观察此类问题,请在不使用调试程序的情况下运行以下命令(可在 此处 找到源代码 https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/debug/examples/debug_mnist.py):
python -m tensorflow.python.debug.examples.debug_mnist
此代码训练了一个简单的神经网络来识别 MNIST 数字图像。请注意,在完成第一个训练步之后,准确率略有提高,但之后停滞在较低(近机会)水平:
Accuracy at step 0: 0.1113
Accuracy at step 1: 0.3183
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
Accuracy at step 4: 0.098
您想知道哪里出了问题,怀疑训练图中的某些节点生成了错误数值(例如 inf 和 nan),因为这是导致此类训练失败的常见原因。我们可以使用 tfdbg 来调试此问题,并确定第一次出现此数字问题的确切图节点。
使用 tfdbg 封装 TensorFlow 会话
要向示例中的 tfdbg 添加支持,我们只需添加下列代码行,并使用调试程序封装容器封装会话对象。此代码已添加到 debug_mnist.py 中,因此您可以在命令行中使用 --debug 标记激活 tfdbg CLI。
# Let your BUILD target depend on "//tensorflow/python/debug:debug_py"
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
sess = tf_debug.LocalCLIDebugWrapperSession(sess)
此封装容器与会话具有相同的界面,因此启用调试时不需要对代码进行其他更改。该封装容器还提供其他功能,包括:
在每次 Session.run() 调用前后调出 CLI,以便您控制执行情况和检查图的内部状态
允许您为张量值注册特殊 filters,以便诊断问题
在本示例中,我们已经注册了一个名为 tfdbg.has_inf_or_nan 的张量过滤器,它仅仅确定任何中间张量(不是 Session.run() 调用的输入或输出、而是位于从输入到输出的路径中的张量)中是否存在任何 nan 或 inf 值。此过滤器可以确定是否存在 nan 和 inf,这是一种常见的用例,我们在 debug_data 模块中包含了此过滤器。
注意:您还可以自行编写自定义过滤器。要了解详情,请参阅 DebugDumpDir.find() 的 API 文档。
使用 tfdbg 调试模型训练
我们尝试再次训练模型,但这次添加 --debug 标记:
python -m tensorflow.python.debug.examples.debug_mnist --debug
调试封装容器会话会在将要执行第一次 Session.run() 调用时提示您,而屏幕上会显示关于获取的张量和 feed 字典的信息。
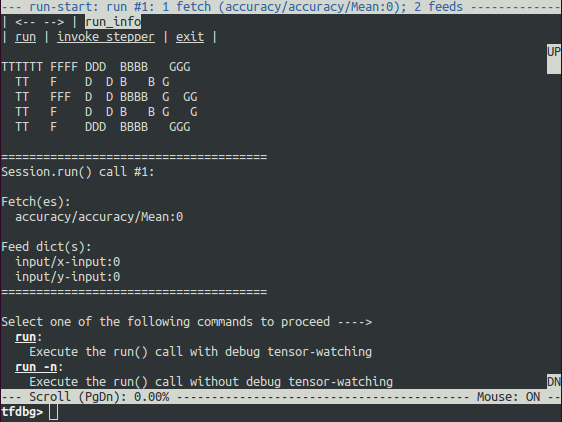
这就是我们所说的 run-start CLI。它先列出对当前 Session.run 调用的 feed 和 fetch,然后再执行任何操作。
如果因屏幕尺寸太小而无法显示完整的消息内容,您可以调整屏幕大小。
使用 PageUp/PageDown/Home/End 键可以浏览屏幕上的输出。在大部分没有这些键的键盘上,使用 Fn + Up/Fn + Down/Fn + Right/Fn + Left 也可以。
在命令提示符处输入 run 命令(或只输入 r):
tfdbg> run
run 命令会让 tfdbg 一直执行,直到下一次 Session.run() 调用结束,而此调用会使用测试数据集计算模型的准确率。tfdbg 会扩展运行时图来转储所有中间张量。运行结束后,tfdbg 会在 run-end CLI 中显示所有转储的张量值。例如:
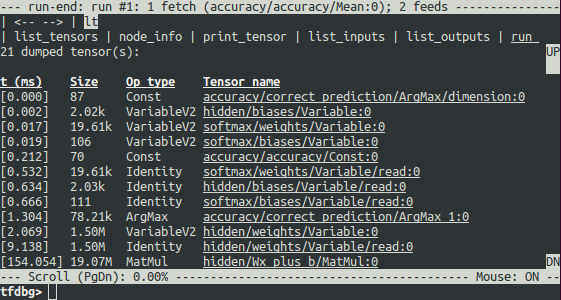
在执行 run 之后运行命令 lt 也可以获得此张量列表。
tfdbg CLI 常用命令
在 tfdbg> 提示符处尝试下列命令(参考 tensorflow/python/debug/examples/debug_mnist.py 中的代码):
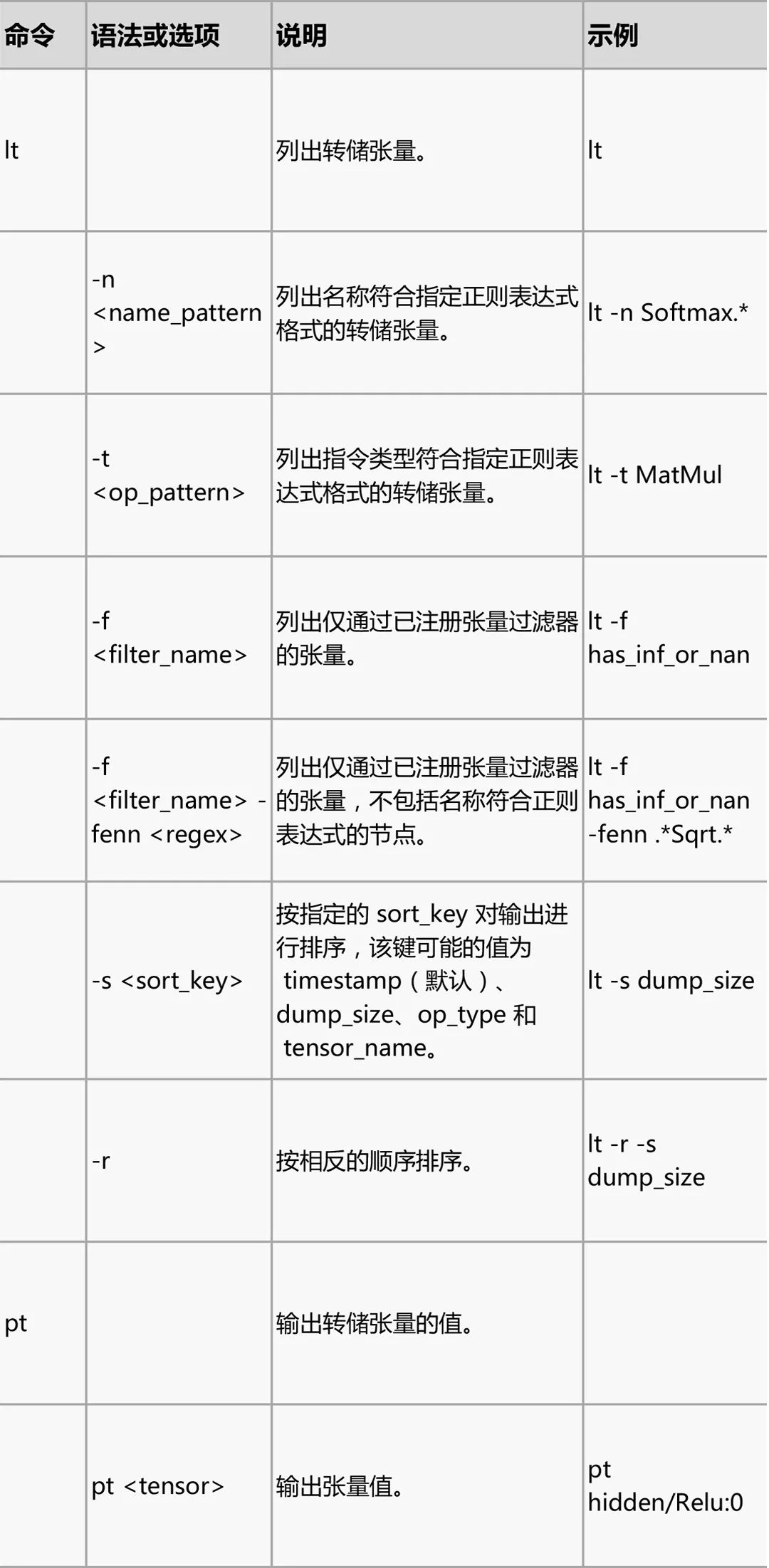
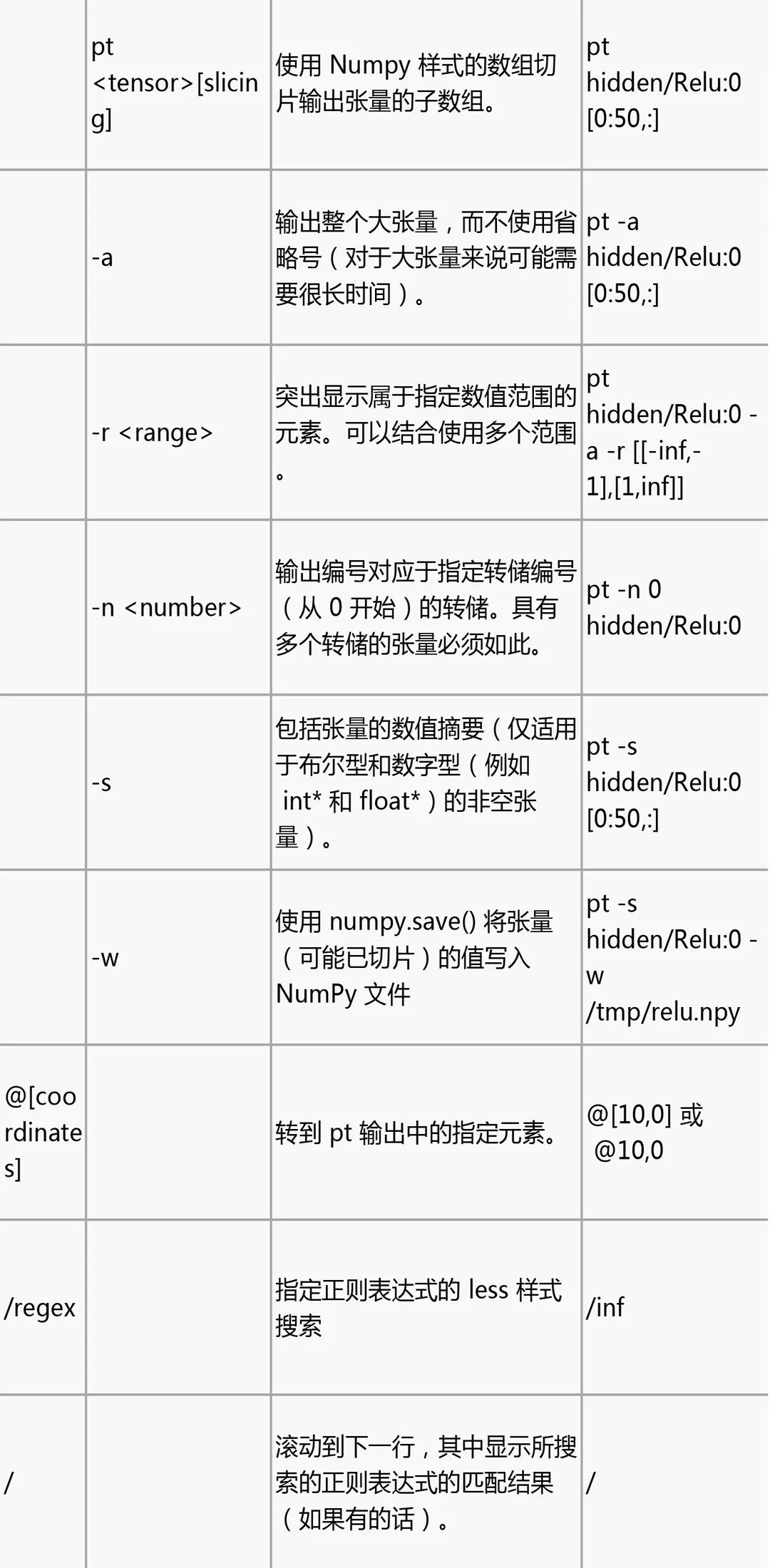
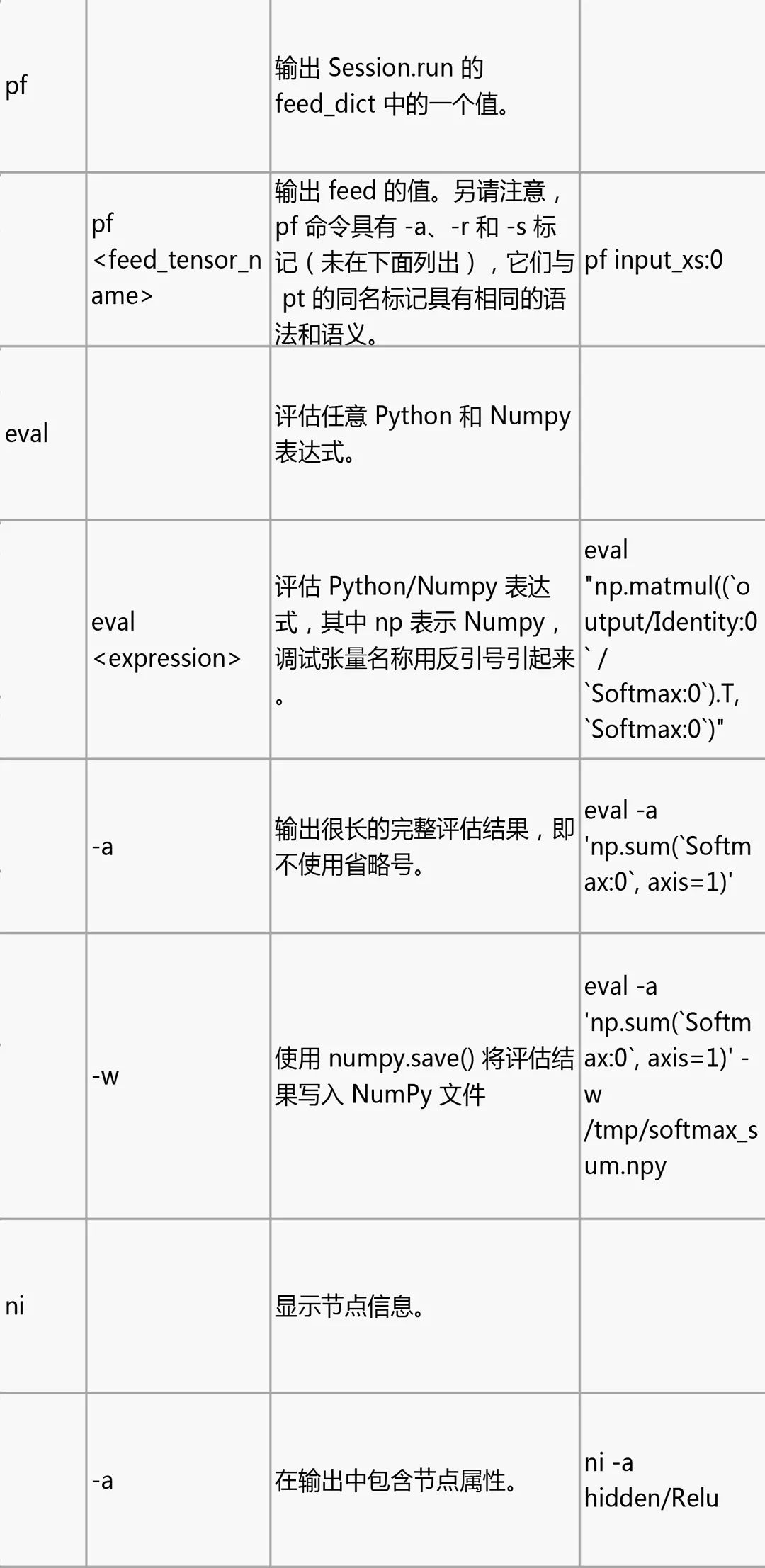
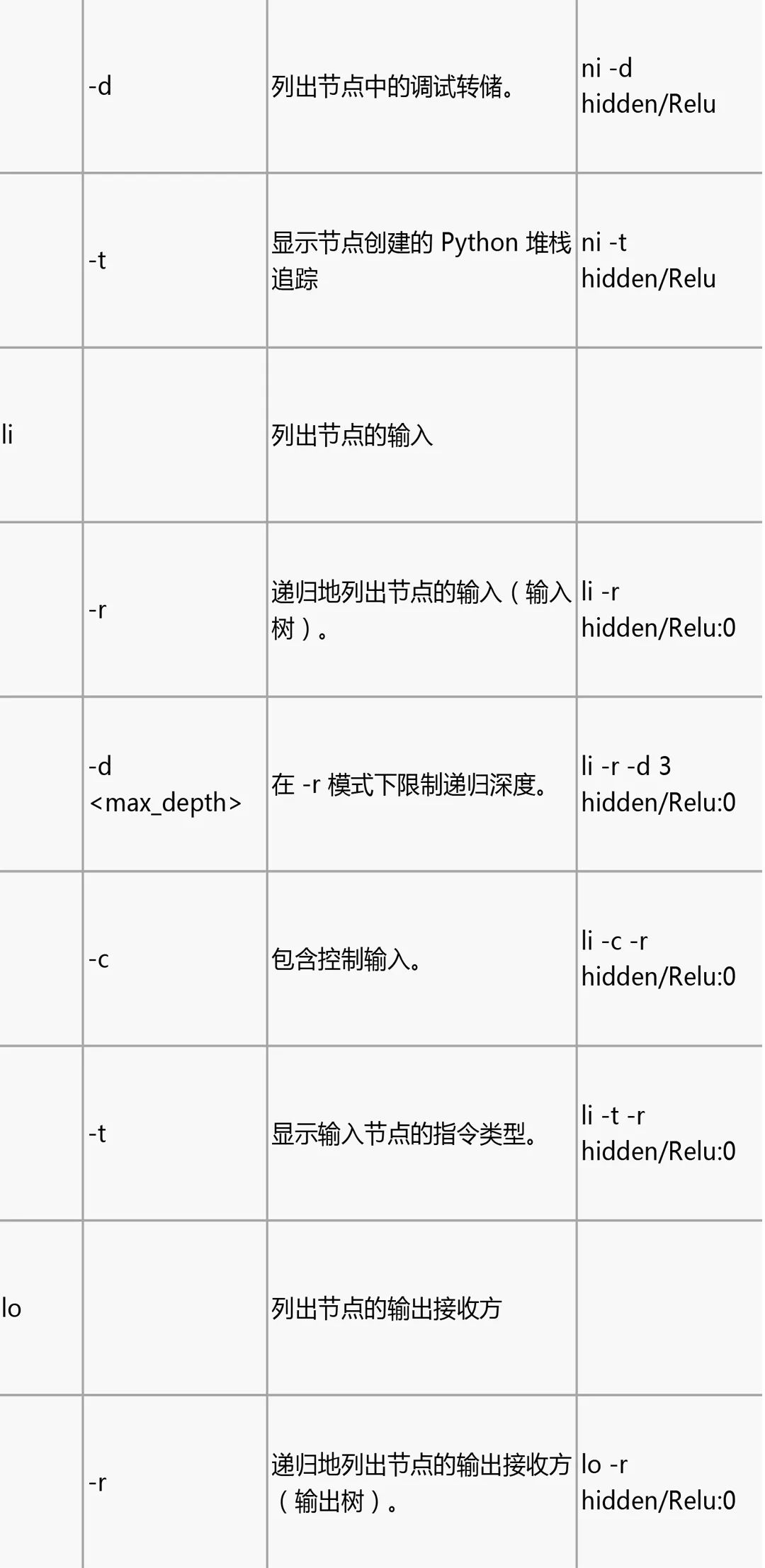
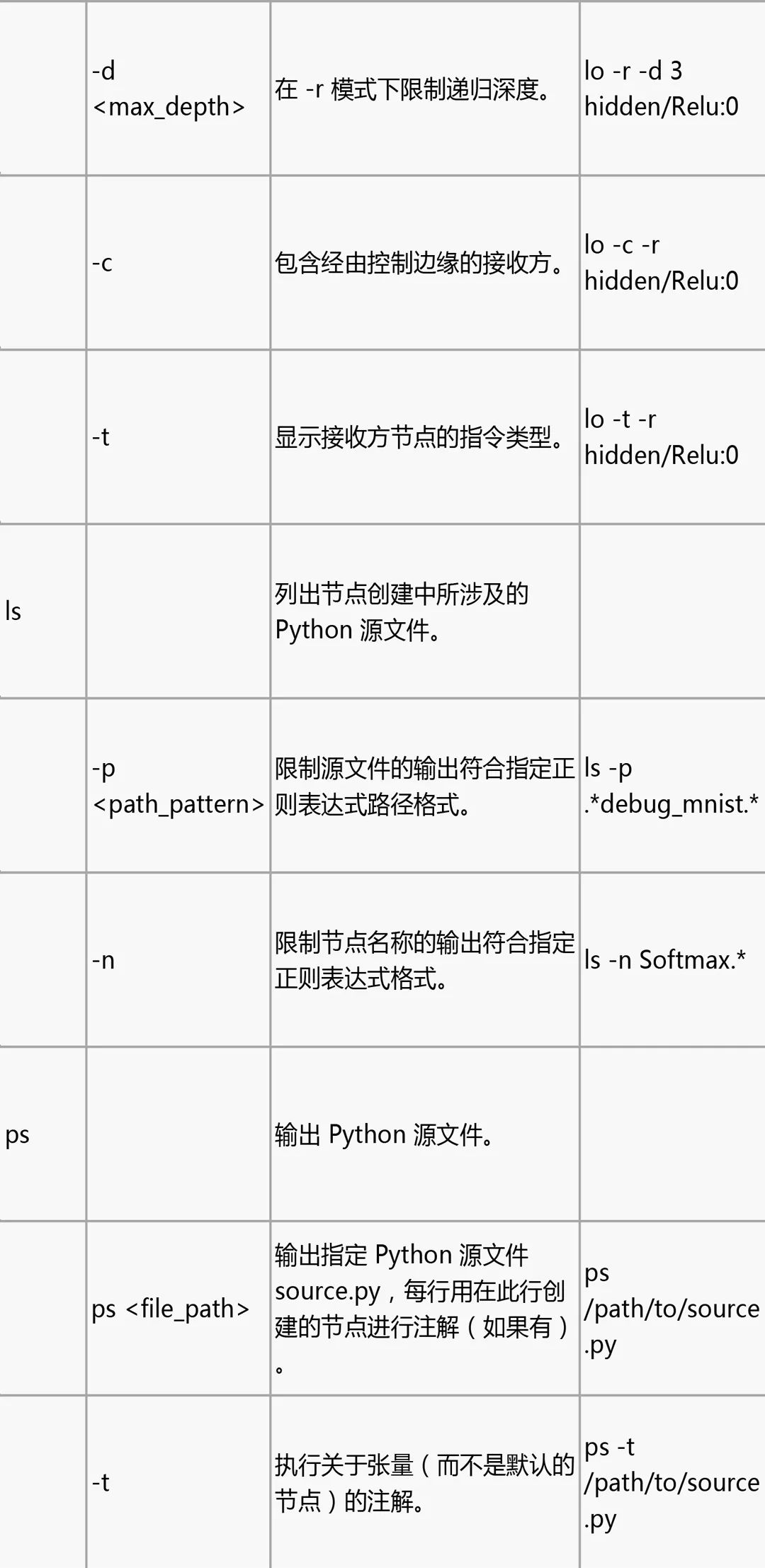
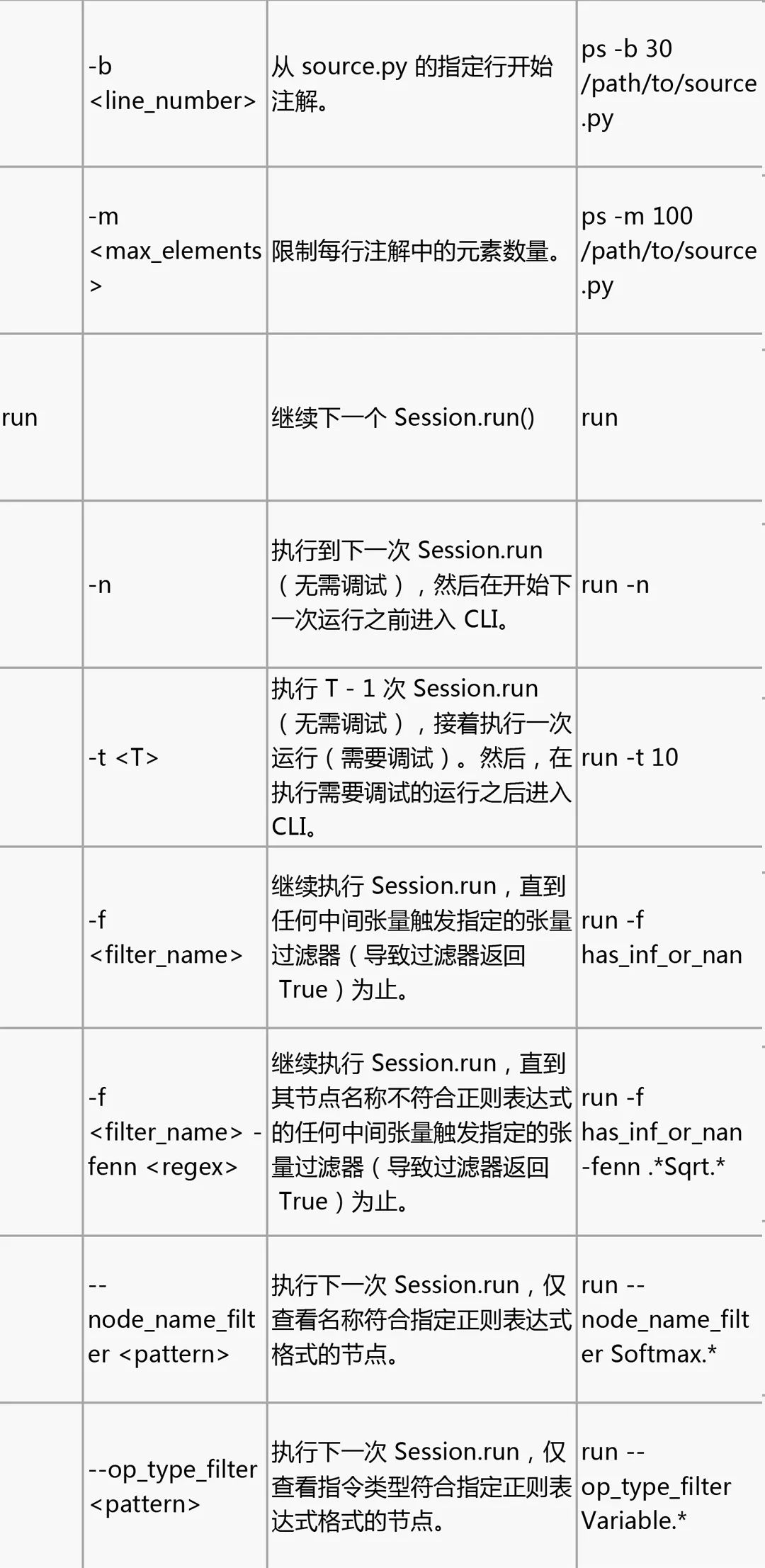
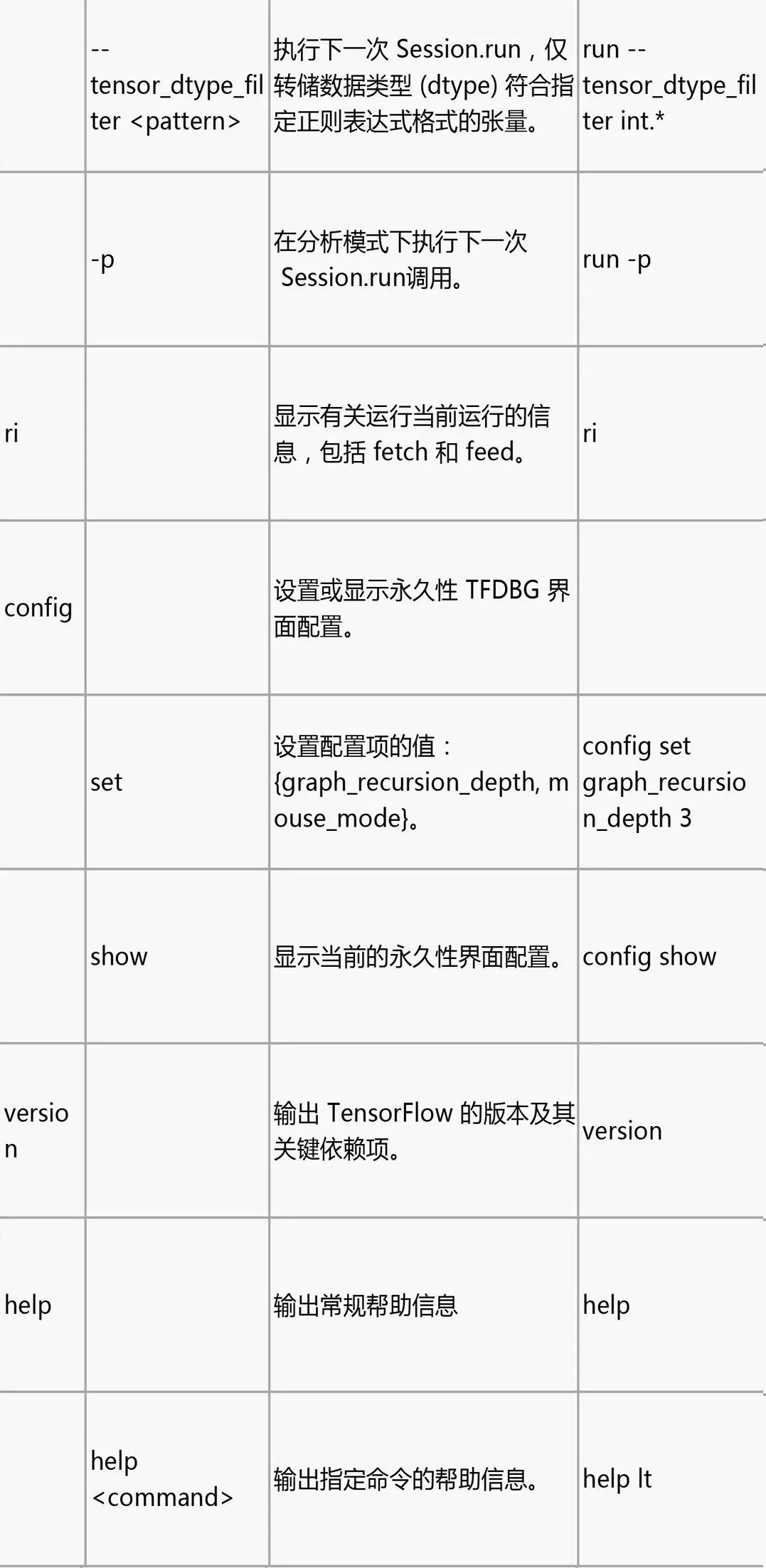
请注意,每次输入命令时,都会显示新的屏幕输出。这有点类似于浏览器中的网页。您可以通过点击 CLI 左上角附近的 文本箭头在这些屏幕之间导航。
tfdbg CLI 的其他功能
除了上面列出的命令外,tfdbg CLI 还提供了下列其他功能:
要浏览之前的 tfdbg 命令,请输入几个字符,然后按向上或向下箭头键。tfdbg 会向您显示以这些字符开头的命令的历史记录
要浏览屏幕输出的历史记录,请执行下列任一操作:
使用 prev 和 next 命令
点击屏幕左上角附近带下划线的 链接
命令(和一些命令参数)的 Tab 补齐功能
要将屏幕输出重定向到文件(而不是屏幕),请使用 bash 样式重定向结束命令。例如,以下命令会将 pt 命令的输出重定向到 /tmp/xent_value_slices.txt 文件:
tfdbg> pt cross_entropy/Log:0[:, 0:10] > /tmp/xent_value_slices.txt
查找 nan 和 inf
在第一个 Session.run() 调用中,没有出现存在问题的数值。您可以使用命令 run 或其简写形式 r 转到下一次运行。
提示:如果您反复输入 run 或 r,则将能够依序在 Session.run() 调用之间移动。
您还可以使用 -t 标记一次向前移动多个 Session.run() 调用,例如:
tfdbg> run -t 10
在每次 Session.run() 调用之后,您无需重复输入 run 并在 run-end 界面中手动搜索 nan 和 inf(例如,通过使用上表中显示的 pt 命令),而是可以使用以下命令让调试程序反复执行 Session.run() 调用(不在 run-start 或 run-end 提示符处停止),直到第一个 nan 或 inf 值出现在图中。这类似于一些程序式语言调试程序中的条件断点:
tfdbg> run -f has_inf_or_nan
注意:上述命令可正常运行,因为在创建封装会话时已为您注册了一个名为 has_inf_or_nan 的张量过滤器。此过滤器会检测 nan 和 inf(如前所述)。如果您已注册任何其他过滤器,则可以使用“run -f”让 tfdbg 一直运行,直到任何张量触发该过滤器(导致过滤器返回 True)为止。
def my_filter_callable(datum, tensor):
# A filter that detects zero-valued scalars.
return len(tensor.shape) == 0 and tensor == 0.0
sess.add_tensor_filter('my_filter', my_filter_callable)
然后在 tfdbg run-start 提示符处运行,直到您的过滤器被触发:
tfdbg> run -f my_filter
请参阅此 API 文档,详细了解与 add_tensor_filter() 搭配使用的谓词 Callable 的预期签名和返回值(https://tensorflow.google.cn/api_docs/python/tfdbg/DebugDumpDir?hl=zh-CN#find)。
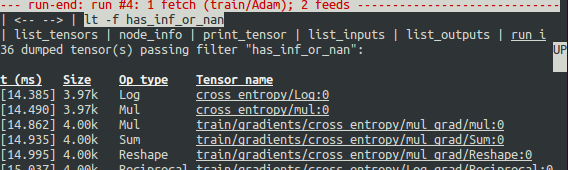
如屏幕所示,在第一行中,has_inf_or_nan 过滤器在第四次 Session.run() 调用期间第一次被触发:Adam 优化器前向-后向训练通过了图。在本次运行中,36 个(共 95 个)中间张量包含 nan 或 inf 值。这些张量按时间先后顺序列出,具体时间戳显示在左侧。在列表顶部,您可以看到第一次出现错误数值的第一个张量:cross_entropy/Log:0。
要查看张量的值,请点击带下划线的张量名称 cross_entropy/Log:0 或输入等效命令:
tfdbg> pt cross_entropy/Log:0
向下滚动一点,您会发现一些分散的 inf 值。如果很难用肉眼找到出现 inf 和 nan 的地方,可以使用以下命令执行正则表达式搜索并突出显示输出:
tfdbg> /inf
或者:
tfdbg> /(inf|nan)
您还可以使用 -s 或 --numeric_summary 命令获取张量中的数值类型的快速摘要:
tfdbg> pt -s cross_entropy/Log:0
您可以从摘要中看到 cross_entropy/Log:0 张量的若干个元素(共 1000 个)都是 -inf(负无穷大)。
为什么会出现这些负无穷大的值?为了进一步进行调试,通过点击顶部带下划线的 node_info 菜单项或输入等效的 node_info (ni) 命令,显示有关节点 cross_entropy/Log 的更多信息:
tfdbg> ni cross_entropy/Log
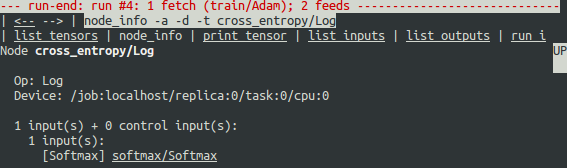
您可以看到,此节点的指令类型为 Log,输入为节点 Softmax。运行以下命令可进一步查看输入张量:
tfdbg> pt Softmax:0
检查输入张量中的值,并搜索其中是否存在零:
tfdbg> /0\.000
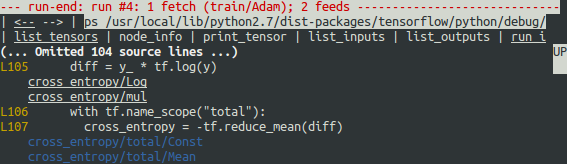
确实存在零。现在很明显,错误数值的根源是节点 cross_entropy/Log 取零的对数。要在 Python 源代码中找出导致错误的行,请使用 ni 命令的 -t 标记来显示节点构造的回溯:
tfdbg> ni -t cross_entropy/Log
如果您点击屏幕顶部的“node_info”,tfdbg 会自动显示节点构造的回溯。
从回溯中可以看到该操作是在以下行构建的 - debug_mnist.py:
diff = y_ * tf.log(y)
tfdbg 有一个可以轻松将张量和指令追溯到 Python 源文件中的行的功能。它可以用行创建的指令或张量注解 Python 文件的行。要使用此功能,只需点击 ni -t 命令的堆栈追踪输出中带下划线的行编号,或者使用 ps(或 print_source)命令,例如:ps /path/to/source.py。例如,以下屏幕截图显示了 ps 命令的输出。
解决问题
要解决此问题,请修改 debug_mnist.py,将原始行:
diff = -(y_ * tf.log(y))
更改为 softmax 交叉熵的在数值上稳定的内置实现:
diff = tf.losses.softmax_cross_entropy(labels=y_, logits=logits)
用 --debug 标记重新运行,如下所示:
python -m tensorflow.python.debug.examples.debug_mnist --debug
在 tfdbg> 提示符处输入以下命令:
run -f has_inf_or_nan`
确认没有任何张量被标记为包含 nan 或 inf 值,并且准确率现在继续上升(而不是停滞不变)。成功!
更多 AI 相关阅读:
TensorFlow Lite 对象检测
标贝科技:TensorFlow 框架提升语音合成效果
使用 TensorFlow Model Analysis 提升模型质量














 3150
3150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









