





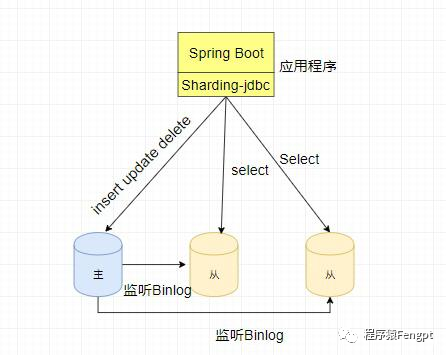
Sharding-JDBC是当当网的一个开源项目,只需引入jar即可轻松实现读写分离与分库分表。
读写分离,简单来说,就是将DML交给主数据库去执行,将更新结果同步至各个从数据库保持主从数据一致,DQL分发给从数据库去查询,从数据库只提供读取查询操作。读写分离特别适用于读多写少的场景下,通过分散读写到不同的数据库实例上来提高性能,缓解单机数据库的压力。
前期准备
三个数据库,一个主库 ,两个备份库 ,在此之前实现主从同步。
一、创建spring boot项目,加入相关pom jar包
<dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starter-webartifactId>dependency><dependency><groupId>org.mybatis.spring.bootgroupId><artifactId>mybatis-spring-boot-starterartifactId><version>1.3.2version>dependency><dependency><groupId>mysqlgroupId><artifactId>mysql-connector-javaartifactId>dependency><dependency><groupId>com.alibabagroupId><artifactId>druid-spring-boot-starterartifactId><version>1.1.10version>dependency><dependency><groupId>org.projectlombokgroupId><artifactId>lombokartifactId>dependency><dependency><groupId>io.shardingspheregroupId><artifactId>sharding-jdbc-spring-boot-starterartifactId><version>3.1.0.M1version>dependency>
二、配置相关配置文件
sharding:jdbc:dataSource:names: db-test0,db-test1,db-test2# 配置主库db-test0: #org.apache.tomcat.jdbc.pool.DataSourcetype: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://10.12.12.12:3304/test_master?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword:#最大连接数maxPoolSize: 20db-test1: # 配置第一个从库type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://10.12.12.12:3304/test_slave01?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMTusername: rootpassword:maxPoolSize: 20db-test2: # 配置第二个从库type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://10.12.12.12:3304/test_slave02?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMTusername: rootpassword:maxPoolSize: 20config:masterslave: # 配置读写分离load-balance-algorithm-type: round_robin # 配置从库选择策略,提供轮询与随机,这里选择用轮询//random 随机 //round_robin 轮询name: db1s2master-data-source-name: db-test0slave-data-source-names: db-test1,db-test2props:sql: # 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志!!!show: trueserver:port: 8081
三、接下来我们测试下
1、先准备三个库,和一个表
CREATE TABLE `user` (`id` BIGINT(20) NOT NULL AUTO_INCREMENT,`name` VARCHAR(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=INNODB
2、编写一个insert、和select的方法
UserMapper
public interface UserMapper {@Insert({ " })Integer createUser(@Param("user") User user);@Select({ "select * from user" })ListgetUserList();}
UserController
@RestControllerpublic class UserController {@AutowiredUserService userService;@PostMapping("/create")public Integer createUser(@RequestBody User user) {return userService.createUser(user);}@GetMapping("/getList")public ListgetUserList() {return userService.getUserList();}}
3、通过postman测试
为了方便测试,我把三个库的数据制造成不一样的。
1)首先测试insert的
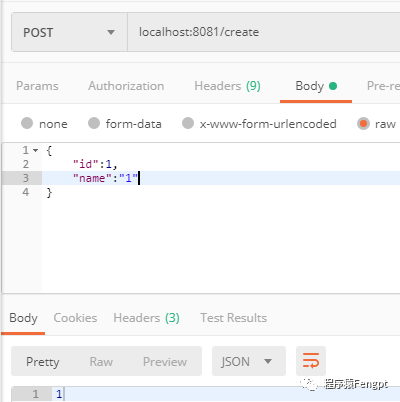
这时候,我们查看三个库,只发现主库,新增了数据,其他的库没有新增数据。
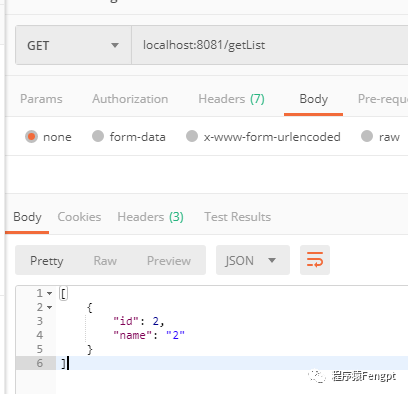
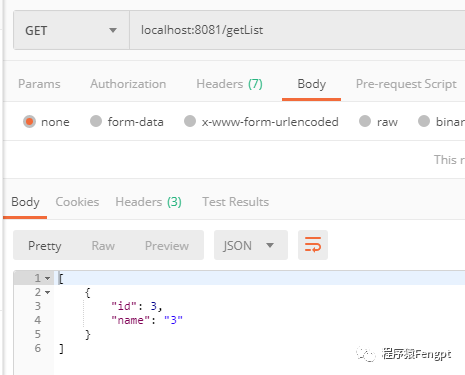
2)测试查询
我们先备份库01的数据写入为 {"id":2,"name":"2"},备份库02的数据写入为 {"id":3,"name":"3"}
我们多次查询,可以发现备份库的数据在轮询查出。
四、说明
1)原理说明
先看下SQL语言四大分类:DQL、DML、DDL、DCL。
DQL(Data QueryLanguage):数据查询语言,比如select查询语句
DML(Data Manipulation Language):数据操纵语言,比如insert、- - delete、update更新语句
DDL():数据定义语言,比如create/drop/alter等语句
DCL():数据控制语言,比如grant/rollback/commit等语句
追溯源码进入MasterSlaveDataSource这个类中
/** * Get data source from master-slave data source. * * @param sqlType SQL type * @return data source from master-slave data source */public NamedDataSource getDataSource(final SQLType sqlType) {if (isMasterRoute(sqlType)) {DML_FLAG.set(true);return new NamedDataSource(masterSlaveRule.getMasterDataSourceName(), masterSlaveRule.getMasterDataSource());}String selectedSourceName = masterSlaveRule.getStrategy().getDataSource(masterSlaveRule.getName(),masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceMap().keySet()));DataSource selectedSource = selectedSourceName.equals(masterSlaveRule.getMasterDataSourceName())? masterSlaveRule.getMasterDataSource() : masterSlaveRule.getSlaveDataSourceMap().get(selectedSourceName);Preconditions.checkNotNull(selectedSource, "");return new NamedDataSource(selectedSourceName, selectedSource);}private boolean isMasterRoute(final SQLType sqlType) {return SQLType.DQL != sqlType || DML_FLAG.get() || HintManagerHolder.isMasterRouteOnly();}
isMasterRoute() 方法判断当前操作是否应该路由到主库数据源,如果SQL类型是DML则返回true
getDataSource() 方法根据SQL类型返回一个数据源。如果SQL类型是DQL则通过配置的算法返回一个从库数据源,如果SQL类型是DML则返回主库数据源。
2)轮询策略源码分析
/** * Round-robin slave database load-balance algorithm. * * @author zhangliang */public final class RoundRobinMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {private static final ConcurrentHashMap COUNT_MAP = new ConcurrentHashMap<>();@Overridepublic String getDataSource(final String name, final String masterDataSourceName, final List slaveDataSourceNames) {AtomicInteger count = COUNT_MAP.containsKey(name) ? COUNT_MAP.get(name) : new AtomicInteger(0);COUNT_MAP.putIfAbsent(name, count);count.compareAndSet(slaveDataSourceNames.size(), 0);return slaveDataSourceNames.get(count.getAndIncrement() % slaveDataSourceNames.size());}
其内部通过并发容器ConcurrentHashMap与AtomicInteger的CAS保障高并发下计数线程安全,使用无锁的方式比加锁效率更高。
这样,我们就可以编写自己的策略了
sharding:jdbc:config:masterslave:load-balance-algorithm-class-name: 自定义算法类的全限定名
2)注意点
Sharding-JDBC目前仅支持一主多从的结构
Sharding-JDBC没有提供主从同步的实现,该功能需要自己额外搭建,可参照《基于Docker搭建MySQL主从复制》简易搭建测试使用
主库和从库的数据同步延迟导致的数据不一致问题需要自己去解决
Sharding-JDBC虽然提供了打印SQL日志的开关,但是如果仅配置了读写分离好像是没有用的
文中配置使用的是HikariCP连接池,使用其他连接池时,需要将jdbc-url配置名该为url,否则可能会抛异常














 2299
2299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









