





前言
Pandas是机器学习三剑客之一,我们知道Numpy能够对数据进行很好的分析、操作、矩阵计算等,Pandas更侧重于数据的处理和分析,它的底层是使用Numpy实现的,在数据处理和分析方面提供了强大的功能。下面就总结一下日常使用操作,以问题的形式罗列。
程序运行环境:window10 Python3.7 (Anaconda) Pandas 1.0.1
编辑工具:jupyter
在日常数据分析中,经常使用的是CSV文件,本文也主要记录该文件的相关处理方式。
(补充:默认的csv文件是以“,”隔开的文本文件,使用excel打开时与xls文件类似)
相关文档可参考:Pandas中文文档[1] 、Pandas英文文档[2]
数据类型
数据预处理是做数据分析、数据挖掘、机器学习等的第一步。下面以泰坦尼克号乘客信息数据(titanic.csv)数据集做介绍。部分数据展示可参见对应jupyter数据文件。
通常使用pandas读取数据后会返回一个「DataFrame」数据结构,查看某一列(行)数据的数据类型返回一个「Series」,也就是说DataFrame由Series组成,读取数据是默认把第一行数据当作列名,可将一个DataFrame认为是一个二维数组数据结构。

问题
「查看数据的基本信息」
DataFrame提供了info()方法,该方法返回DataFrame数据的样本规模、每列数据信息等。展示如下:

从结果中可以看出,数据891个实体,默认每一行为一个实体,一共12列,每列的信息也有所展示,例如对应的数据类型,object说明该数据类型为字符串,该文件在读到内存的大小等。
「查看数据的统计信息」
DataFrame提供了describe()方法,可以查看数据的个数、均值、标准差、最大值、最小值等信息。也可从中看出数据是否存在问题。
df.describe()「查看某列各属性个数」
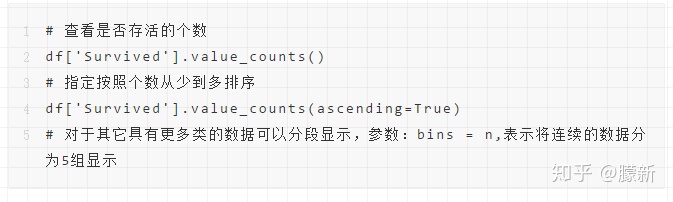
「获取数据的列名」

「获取数据的索引」
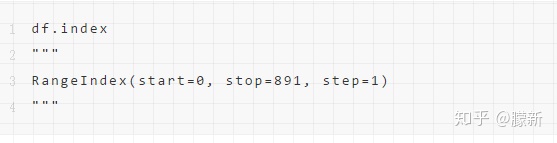
「获取每列数据对应的数据类型」















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









