





接上一节(爬虫系列(0):项目搭建)
网络爬虫的都是通过多线程,多任务逻辑实现的,在springboot框架中已封装线程池(ThreadPoolTaskExecutor),我们只需要使用就是了。
这一节我们主要实现多线程抓取网页连接信息,并将信息存储在队列里面。
引入新包
在pom中引入新包,具体如下:
org.apache.commonscommons-lang3org.jsoupjsoup1.8.3org.projectlomboklombokprovided为了简化编码,这里引入了lombok,在使用时候IDE需要安装lombok插件,否则会提示编译错误。
配置管理
springboot的配置文件都是在application.properties(.yml)统一管理的,在这里,我们也把爬虫相关的配置通过@ConfigurationProperties注解来实现。直接上代码:
package mobi.huanyuan.spider.config;import lombok.Data;import org.springframework.boot.context.properties.ConfigurationProperties;/** * 爬虫配置. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 11:10 */@Data@ConfigurationProperties(prefix = "huanyuan.spider")public class SpiderConfig { /** * 爬取页面最大深度 */ public int maxDepth = 2; /** * 下载页面线程数 */ public int minerHtmlThreadNum = 2; //================================================= // 线程池配置 //================================================= /** * 核心线程池大小 */ private int corePoolSize = 4; /** * 最大可创建的线程数 */ private int maxPoolSize = 100; /** * 队列最大长度 */ private int queueCapacity = 1000; /** * 线程池维护线程所允许的空闲时间 */ private int keepAliveSeconds = 300;}然后,需要修改这些配置,只需要修改application.properties(.yml)里边即可:
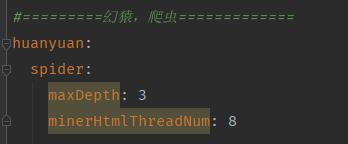
幻猿简易爬虫配置
线程池
线程池使用springboot已有的,配置也在上边配置管理里边有,这里只初始化配置即可:
package mobi.huanyuan.spider.config;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.ThreadPoolExecutor;/** * 线程池配置. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 11:35 */@Configurationpublic class ThreadPoolConfig { @Autowired private SpiderConfig spiderConfig; @Bean(name = "threadPoolTaskExecutor") public ThreadPoolTaskExecutor threadPoolTaskExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setMaxPoolSize(spiderConfig.getMaxPoolSize()); executor.setCorePoolSize(spiderConfig.getCorePoolSize()); executor.setQueueCapacity(spiderConfig.getQueueCapacity()); executor.setKeepAliveSeconds(spiderConfig.getKeepAliveSeconds()); // 线程池对拒绝任务(无线程可用)的处理策略 executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); return executor; }}队列管理
这一节我们主要是抓取URL并保存进队列,所以涉及到的队列有待抓取队列和待分析队列(下一节分析时候用,这里只做存储),此外,为了防止重复抓取同一个URL,这里还需要加一个Set集合,将已访问过的地址做个记录。
package mobi.huanyuan.spider;import lombok.Getter;import mobi.huanyuan.spider.bean.SpiderHtml;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.HashSet;import java.util.LinkedList;import java.util.Queue;import java.util.Set;/** * 爬虫访问队列. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 10:54 */public class SpiderQueue { private static Logger logger = LoggerFactory.getLogger(SpiderQueue.class); /** * Set集合 保证每一个URL只访问一次 */ private static volatile Set urlSet = new HashSet<>(); /** * 待访问队列
* 爬取页面线程从这里取数据 */ private static volatile Queue unVisited = new LinkedList<>(); /** * 等待提取URL的分析页面队列
* 解析页面线程从这里取数据 */ private static volatile Queue waitingMine = new LinkedList<>(); /** * 添加到URL队列 * * @param url */ public synchronized static void addUrlSet(String url) { urlSet.add(url); } /** * 获得URL队列大小 * * @return */ public static int getUrlSetSize() { return urlSet.size(); } /** * 添加到待访问队列,每个URL只访问一次 * * @param spiderHtml */ public synchronized static void addUnVisited(SpiderHtml spiderHtml) { if (null != spiderHtml && !urlSet.contains(spiderHtml.getUrl())) { logger.info("添加到待访问队列[{}] 当前第[{}]层 当前线程[{}]", spiderHtml.getUrl(), spiderHtml.getDepth(), Thread.currentThread().getName()); unVisited.add(spiderHtml); } } /** * 待访问出队列 * * @return */ public synchronized static SpiderHtml unVisitedPoll() { return unVisited.poll(); } /** * 添加到等待提取URL的分析页面队列 * * @param html */ public synchronized static void addWaitingMine(SpiderHtml html) { waitingMine.add(html); } /** * 等待提取URL的分析页面出队列 * * @return */ public synchronized static SpiderHtml waitingMinePoll() { return waitingMine.poll(); } /** * 等待提取URL的分析页面队列大小 * @return */ public static int waitingMineSize() { return waitingMine.size(); }}抓取任务
直接上代码:
package mobi.huanyuan.spider.runable;import mobi.huanyuan.spider.SpiderQueue;import mobi.huanyuan.spider.bean.SpiderHtml;import mobi.huanyuan.spider.config.SpiderConfig;import org.apache.commons.lang3.StringUtils;import org.jsoup.Connection;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.slf4j.Logger;import org.slf4j.LoggerFactory;/** * 抓取页面任务. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 11:43 */public class SpiderHtmlRunnable implements Runnable { private static final Logger logger = LoggerFactory.getLogger(SpiderHtmlRunnable.class); private static boolean done = false; private SpiderConfig config; public SpiderHtmlRunnable(SpiderConfig config) { this.config = config; } @Override public void run() { while (!SpiderHtmlRunnable.done) { done = true; minerHtml(); done = false; } } public synchronized void minerHtml() { SpiderHtml minerUrl = SpiderQueue.unVisitedPoll(); // 待访问出队列。 try { //判断当前页面爬取深度 if (null == minerUrl || StringUtils.isBlank(minerUrl.getUrl()) || minerUrl.getDepth() > config.getMaxDepth()) { return; } //判断爬取页面URL是否包含http if (!minerUrl.getUrl().startsWith("http")) { logger.info("当前爬取URL[{}]没有http", minerUrl.getUrl()); return; } logger.info("当前爬取页面[{}]爬取深度[{}] 当前线程 [{}]", minerUrl.getUrl(), minerUrl.getDepth(), Thread.currentThread().getName()); Connection conn = Jsoup.connect(minerUrl.getUrl()); conn.header("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");//配置模拟浏览器 Document doc = conn.get(); String page = doc.html(); SpiderHtml spiderHtml = new SpiderHtml(); spiderHtml.setUrl(minerUrl.getUrl()); spiderHtml.setHtml(page); spiderHtml.setDepth(minerUrl.getDepth()); System.out.println(spiderHtml.getUrl()); // TODO: 添加到继续爬取队列 SpiderQueue.addWaitingMine(spiderHtml); } catch (Exception e) { logger.info("爬取页面失败 URL [{}]", minerUrl.getUrl()); logger.info("Error info [{}]", e.getMessage()); } }}这里就是个Runnable任务,主要目标就是拉去URL数据,然后封装成SpiderHtml对象存放在待分析队列里边。 这里用到了jsoup--一个java对HTML分析操作的工具包,不清楚的可以去搜索看看,之后章节涉及到分析的部分也会用到。
其他
页面信息封装类SpiderHtml
package mobi.huanyuan.spider.bean;import lombok.Data;import java.io.Serializable;/** * 页面信息类. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 11:02 */@Datapublic class SpiderHtml implements Serializable { /** * 页面URL */ private String url; /** * 页面信息 */ private String html; /** * 爬取深度 */ private int depth;}爬虫主类
package mobi.huanyuan.spider;import mobi.huanyuan.spider.bean.SpiderHtml;import mobi.huanyuan.spider.config.SpiderConfig;import mobi.huanyuan.spider.runable.SpiderHtmlRunnable;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;/** * 爬虫. * * @author Jonathan L.(xingbing.lai@gmail.com) * @version 1.0.0 -- Datetime: 2020/2/18 11:23 */@Componentpublic class Spider { private static Logger logger = LoggerFactory.getLogger(Spider.class); @Autowired private ThreadPoolTaskExecutor threadPoolTaskExecutor; @Autowired private SpiderConfig spiderConfig; public void start(SpiderHtml spiderHtml) { //程序启动,将第一个起始页面放入待访问队列。 SpiderQueue.addUnVisited(spiderHtml); //将URL 添加到URL队列 保证每个URL只访问一次 SpiderQueue.addUrlSet(spiderHtml.getUrl()); //download for (int i = 0; i < spiderConfig.getMinerHtmlThreadNum(); i++) { SpiderHtmlRunnable minerHtml = new SpiderHtmlRunnable(spiderConfig); threadPoolTaskExecutor.execute(minerHtml); } // TODO: 监控爬取完毕之后停线程池,关闭程序 try { TimeUnit.SECONDS.sleep(20); logger.info("待分析URL队列大小: {}", SpiderQueue.waitingMineSize()); // 关闭线程池 threadPoolTaskExecutor.shutdown(); } catch (Exception e) { e.printStackTrace(); } }}在"// TODO:"之后的代码逻辑这里是临时的,等后边章节完善之后,这里就慢慢去掉。
最后
要跑起这一节的代码,需要在springboot项目main方法中加入如下代码:
ConfigurableApplicationContext context = SpringApplication.run(SpiderApplication.class, args);Spider spider = context.getBean(Spider.class);SpiderHtml startPage = new SpiderHtml();startPage.setUrl("$URL");startPage.setDepth(2);spider.start(startPage);$URL就是需要抓取的网页地址。
springboot项目启动后,停止需要手动停止,目前没有处理抓取完自动停止运行的逻辑。 运行结果如下图:
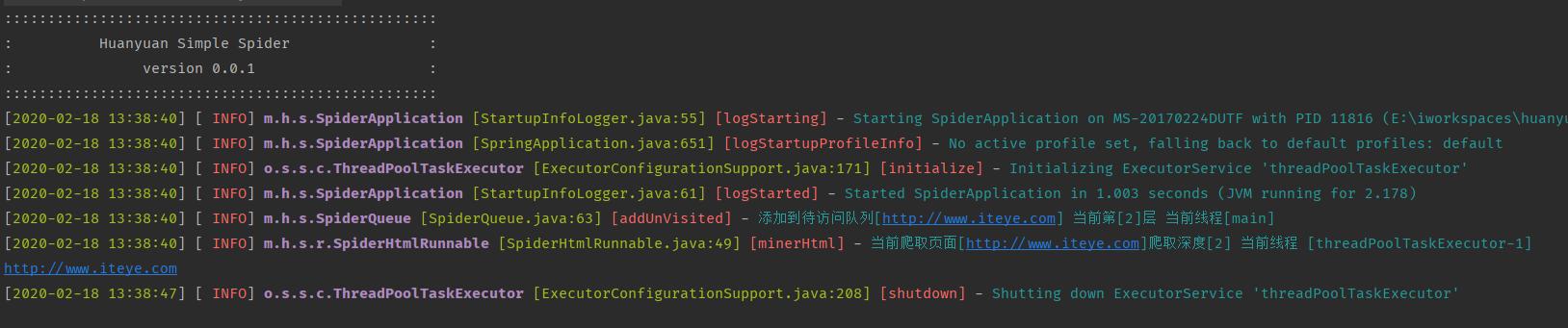
幻猿简易爬虫运行结果
最后,这个章节完成之后整个项目的结构如下图:

幻猿简易爬虫项目结构
关于我

程序界的老猿,自媒体界的新宠 じ☆ve
程序界的老猿,自媒体界的新宠 じ☆ve
联系方式:1405368512@qq.com















 5555
5555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









