






在本文中,我尽可能将内容保持简单。我将向您展示如何获取在线未标记数据,如何创建一个简单的卷积网络,使用一些监督数据对其进行训练,并在以后使用它来分类我们从网络收集的数据。
1.数据抓取
在深度学习中我们经常会使用Fashion MNIST数据集。它是一个超级简单的28x28图像集合,包含60,000个示例的训练集和10,000个示例的测试集。该数据与10个类别的标签相关联,如Trouser,Pullover,Dress,Coat ......

时尚MNIST
所以这个想法很简单,我们用MNIST数据训练我们的网络,然后我们用它来分类从实际的Zalando(https://www.zalando.es)目录中获得的数据。
数据抓取是一项非常重要的任务。大多数情况下,您将无法获得所需的数据,因此您需要从网络上获取数据。如果您了解一点HTML和CSS,那么该过程非常简单。
from selenium import webdriverfrom bs4 import BeautifulSoupimport requestsimport pandas as pdimport osimport sysimport argparsefrom downloader import download_urlsdef main(args): # Init selenium driver options = webdriver.ChromeOptions() driver = webdriver.Chrome(options=options, executable_path=r'./chromedriver') image_url_list = [] base_url = 'https://www.zalando.es/ropa-de-mujer/?p={}' i = 2 image_counter = 0 # Prepare output folder base_folder = args.base_folder output_file = 'data.csv' if not os.path.exists(base_folder): os.makedirs(base_folder) while 1: new_url = base_url.format(i) driver.get(new_url) current_url = driver.current_url x = driver.find_elements_by_css_selector('div.cat_articleContain-1Z60A') garments = [link.find_element_by_css_selector('a').get_attribute('href') for link in x] for garment in garments: if image_counter == args.n_images: break # Get url for specific garment html_details = requests.get(garment) # Access url details_soup = BeautifulSoup(html_details.text, 'html.parser') # Get all images pictures = details_soup.find_all('img', class_='h-image-img h-flex-auto responsive') # Look for zoom images garment_urls = [pic['src'].replace('thumb', 'zoom') for pic in pictures if 'packshot/pdp-thumb' in pic['src']] # Get only first one if exists if garment_urls: image_url_list.append(garment_urls[0]) image_counter += 1 # Save to csv file if not i % 2 or image_counter == args.n_images: tmp_data = pd.DataFrame(image_url_list, columns=['url']) with open(os.path.join(base_folder, output_file), 'a' if i > 2 else 'w') as f: tmp_data.to_csv(f, header=(i == 2)) if new_url != current_url: print('This page does not exist: {}'.format(new_url)) print('You have been redirected to main page (images also downloaded)') break i += 1 print('Total pages: {}'.format(i-2)) if image_counter == args.n_images: driver.close() break # Download obtained urls download_urls(base_folder, args.threads)if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--base_folder', '-bf', help='Base folder for downloaded images', type=str, default='Data/') parser.add_argument('--n_images', '-n', help='Number of images to download', type=int, default=100) parser.add_argument('--threads', '-t', help='Number of threads to use', type=int, default=10) args = parser.parse_args()main(args)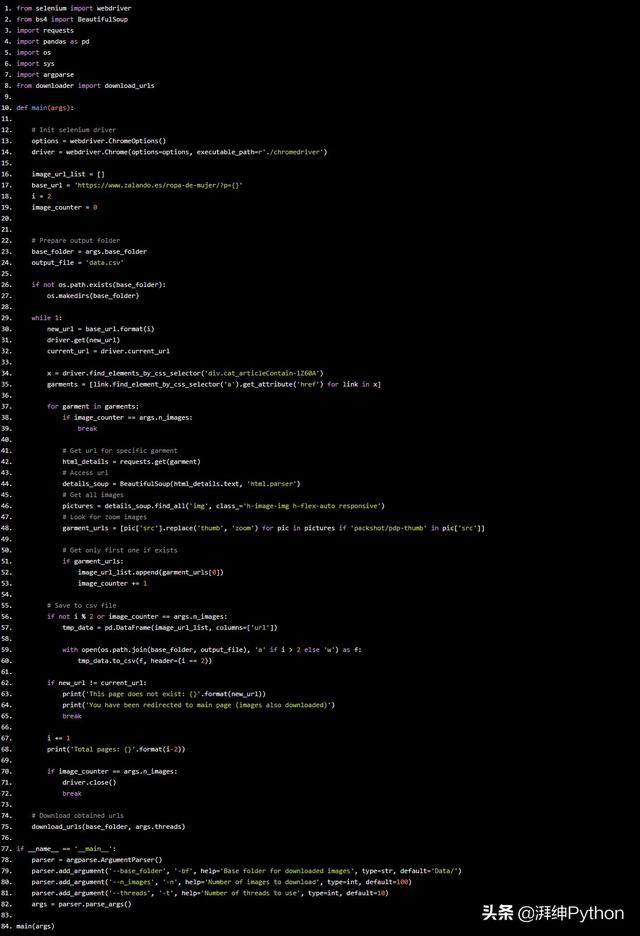
我们使用Python制作数据抓取downloader的代码:
import pandas as pdimport requestsimport osfrom queue import Queuefrom time import timefrom threading import Threadfrom PIL import Imagefrom io import BytesIOclass DownloadWorker(Thread): def __init__(self, queue): Thread.__init__(self) self.queue = queue def run(self): while True: # Get the work from the queue and expand the tuple url, filename = self.queue.get() response = requests.get(url) if response.status_code == 200: img = Image.open(BytesIO(response.content)).convert('RGB') img.thumbnail((400, 400), Image.ANTIALIAS) img.save(filename) else: print('Error with: {}'.format(url)) self.queue.task_done()def download_urls(base_folder='Images', threads=10): print('=====================================================================================================') print(' DOWNLOAD STARTED ') print('=====================================================================================================') ts = time() base_folder = os.path.join(base_folder, 'Images') print('Image destination folder: {}'.format(base_folder)) # Prepare output folder if not os.path.exists(base_folder): os.makedirs(base_folder) # Create a queue to communicate with the worker threads queue = Queue() # Read data data = pd.read_csv('Data/data.csv').url # Create worker threads print('Creating {} threads'.format(threads)) for x in range(threads): worker = DownloadWorker(queue) # Setting daemon to True will let the main thread exit even though the workers are blocking worker.daemon = True worker.start() print('Total URLs: {}'.format(len(data))) # Put the tasks into the queue as a tuple for i, url in enumerate(data[:1000]): queue.put((url, '{}/{}.png'.format(base_folder, i))) # Causes the main thread to wait for the queue to finish processing all the tasks queue.join()print('Took {}'.format(time() - ts)) 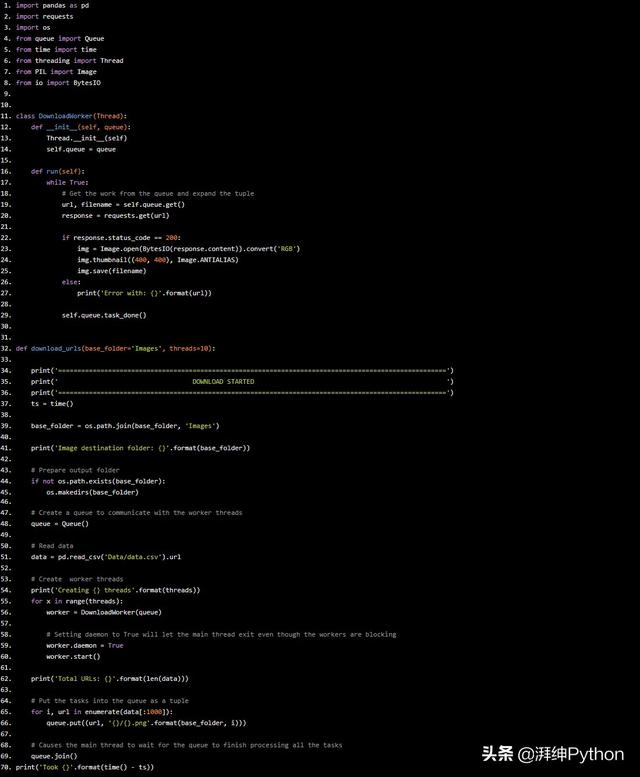
然后在我们从网络获取的图像在插入神经网络之前将获取的数据转换为28x28的灰度图像。
import tensorflow as tffrom tensorflow import kerasdef parse_function(filename): image_string = tf.read_file(filename) image = tf.image.decode_png(image_string, channels=3) image = 1 - tf.image.rgb_to_grayscale(image) image = tf.image.convert_image_dtype(image, dtype=tf.float32) image = tf.image.resize_image_with_pad(image, 28, 28) image.set_shape([28, 28, 1]) return imagedef load_unlabeled_data(filenames, batch_size): ''' Reveices a list of filenames and returns preprocessed images as a tensorflow dataset :param filenames: list of file paths :param batch_size: mini-batch size :return: ''' with tf.device('/cpu:0'): dataset = tf.data.Dataset.from_tensor_slices(filenames) dataset = dataset.map(parse_function, num_parallel_calls=4) dataset = dataset.batch(batch_size) dataset = dataset.prefetch(1) return datasetdef load_mnist_data(batch_size): train, test = keras.datasets.fashion_mnist.load_data() datasets = dict() # Create tf dataset with tf.device('/cpu:0'): with tf.variable_scope("DataPipe"): for data, mode in zip([train, test], ['train', 'test']): datasets[mode] = tf.data.Dataset.from_tensor_slices((data[0], data[1])) datasets[mode] = datasets[mode].map(lambda x, y: (tf.image.convert_image_dtype([x], dtype=tf.float32), tf.dtypes.cast(y, tf.int32))) datasets[mode] = datasets[mode].batch(batch_size=batch_size).prefetch(1) return datasets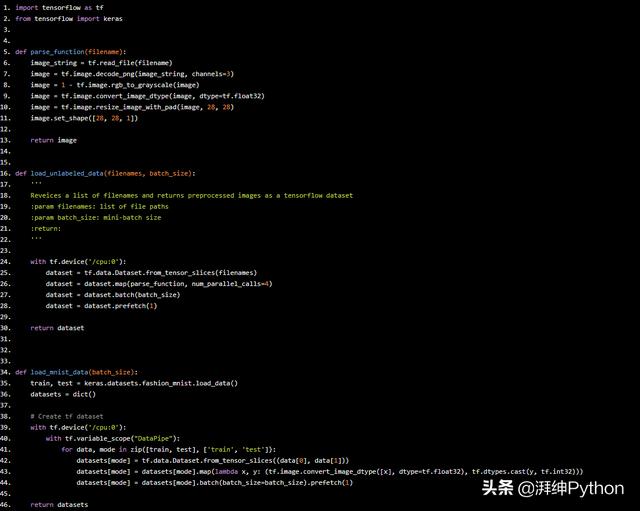
2.神经网络
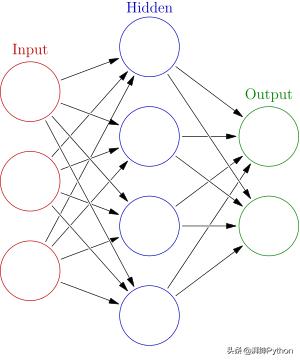
在编码之前,让我们先了解人工神经网络是什么,一个人工神经网络是一个相互关联的组节点,类似于广阔的网络神经元的一个大脑。这里,每个圆形节点表示一个人工神经,箭头表示一个从一个的输出连接人工神经到的另一个输入端。
我们将对小灰度图像进行分类,因此我们不需要超级复杂的架构。我基本上将两个卷积层与其对应的汇集层叠加在一起。在此之后是密集层,然后是dropout操作和具有softmax函数的最终密集层。
import tensorflow as tfimport functoolsdef define_scope(function): # Decorator to lazy loading from https://danijar.com/structuring-your-tensorflow-models/ attribute = '_cache_' + function.__name__ def decorator(self): if not hasattr(self, attribute): setattr(self, attribute, function(self)) return getattr(self, attribute) return decoratorclass Network: def __init__(self, data, labels, learning_rate): self.data = data self.labels = labels self.learning_rate = learning_rate self.forward_pass self.optimize self.accuracy def forward_pass(self): activation = tf.nn.relu with tf.variable_scope('Data'): x = self.data with tf.variable_scope('Network'): x = tf.layers.conv2d(x, filters=64, kernel_size=5, padding='same', activation=activation) x = tf.layers.max_pooling2d(inputs=x, pool_size=[2, 2], strides=2) x = tf.layers.conv2d(x, filters=64, kernel_size=5, padding='same', activation=activation) x = tf.layers.max_pooling2d(inputs=x, pool_size=[2, 2], strides=2) x = tf.layers.flatten(x) # Local latent variables x = tf.layers.dense(x, units=1024, activation=activation) # Dropout self.is_training = tf.placeholder_with_default(True, (), name='is_training') x = tf.layers.dropout(inputs=x, rate=0.4, training=self.is_training) self.logits = tf.layers.dense(inputs=x, units=10) predictions = { 'classes': tf.argmax(input=self.logits, axis=1, name='output_class'), 'probabilities': tf.nn.softmax(self.logits, name='softmax_tensor') } return predictions def optimize(self): with tf.variable_scope('Optimize'): loss = tf.losses.sparse_softmax_cross_entropy(labels=self.labels, logits=self.logits) optimizer = tf.train.AdamOptimizer(self.learning_rate).minimize(loss) tf.summary.scalar('batch_loss', loss) return optimizer def accuracy(self): with tf.name_scope('Metrics'): _, update_acc = tf.metrics.accuracy(self.forward_pass['classes'], self.labels, name="accuracy") tf.summary.scalar('epoch_accuracy', update_acc)return update_acc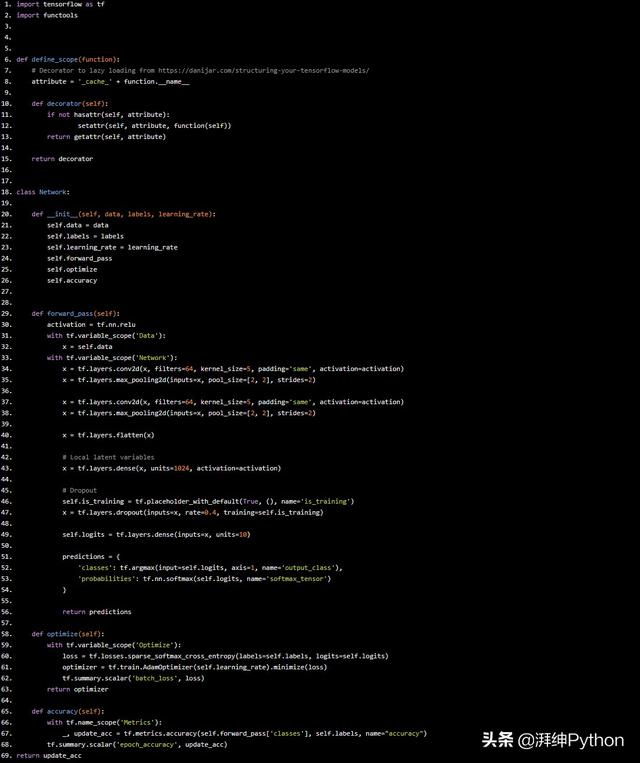
3.训练神经网络
对于训练任务,我使用了Adam Optimizer,让算法只运行了100个周期。您可以训练更长时间的来提高您想要的准确性,我还建议您更改网络结构,添加一些额外的层。
from network import Networkimport tensorflow as tffrom dataset import load_mnist_dataimport osfrom utils import create_folder, delete_old_logs, create_results_folderfrom time import time# Program parameterstf.flags.DEFINE_float('learning_rate', .0001, 'Initial learning rate.')tf.flags.DEFINE_integer('epochs', 1000, 'Number of steps to run trainer.')tf.flags.DEFINE_integer('batch_size', 128, 'Minibatch size')tf.flags.DEFINE_integer('validation_after_n', 2, 'Number of epochs before apply validation testing')tf.flags.DEFINE_integer('save_after_n', 2, 'Number of epochs before saving network')tf.flags.DEFINE_string('logdir', './logs', 'Logs folder')tf.flags.DEFINE_string('model_description', 'garment_classifier', 'Model name')FLAGS = tf.flags.FLAGS# Prepare output directoriesresults_folder = create_results_folder(os.path.join('Results', FLAGS.model_description))model_folder = create_folder(os.path.join('Models', FLAGS.model_description))delete_old_logs(FLAGS.logdir)# Create tf datasetwith tf.name_scope('DataPipe'): datasets = load_mnist_data(FLAGS.batch_size) iterator = tf.data.Iterator.from_structure(datasets['train'].output_types, datasets['train'].output_shapes) # Create the initialisation operations for training and test train_init_op = iterator.make_initializer(datasets['train']) test_init_op = iterator.make_initializer(datasets['test']) # Create iterator input_batch, labels = iterator.get_next() input_batch = tf.reshape(input_batch, shape=[-1, 28, 28, 1]) # This placeholder is necessary to feed new data after training input_data = tf.placeholder_with_default(input_batch, [None, 28, 28, 1], name='input_data')# Create networkmodel = Network(input_data, labels, FLAGS.learning_rate)# Get metrics variables to be reset after each epochmetrics = tf.get_collection(tf.GraphKeys.LOCAL_VARIABLES, scope="metrics/*")reset_metrics = tf.variables_initializer(var_list=metrics)init_vars = [tf.local_variables_initializer(), tf.global_variables_initializer()]saver = tf.train.Saver()# Training loopwith tf.Session() as sess: writer = tf.summary.FileWriter('./logs', sess.graph) sess.run(init_vars) merged_summary_op = tf.summary.merge_all() for epoch in range(FLAGS.epochs): print('Epoch: {}'.format(epoch), end='', flush=True) sess.run(train_init_op) flag = True ts = time() # Training loop while True: try: sess.run(model.optimize) except tf.errors.OutOfRangeError: print(' Time: {}'.format(time() - ts), end='') break # Validation loop if not epoch % FLAGS.validation_after_n: sess.run(test_init_op) while True: try: sess.run(model.accuracy) test_summaries, acc = sess.run([merged_summary_op, model.accuracy], feed_dict={model.is_training: False}) except tf.errors.OutOfRangeError: writer.add_summary(test_summaries, epoch) print(' Validation time: {} Accuracy: {}'.format(time() - ts, acc), end='') sess.run([reset_metrics]) break # Save model if not epoch % FLAGS.save_after_n and epoch > 0: print('Saving model...')saver.save(sess, model_folder)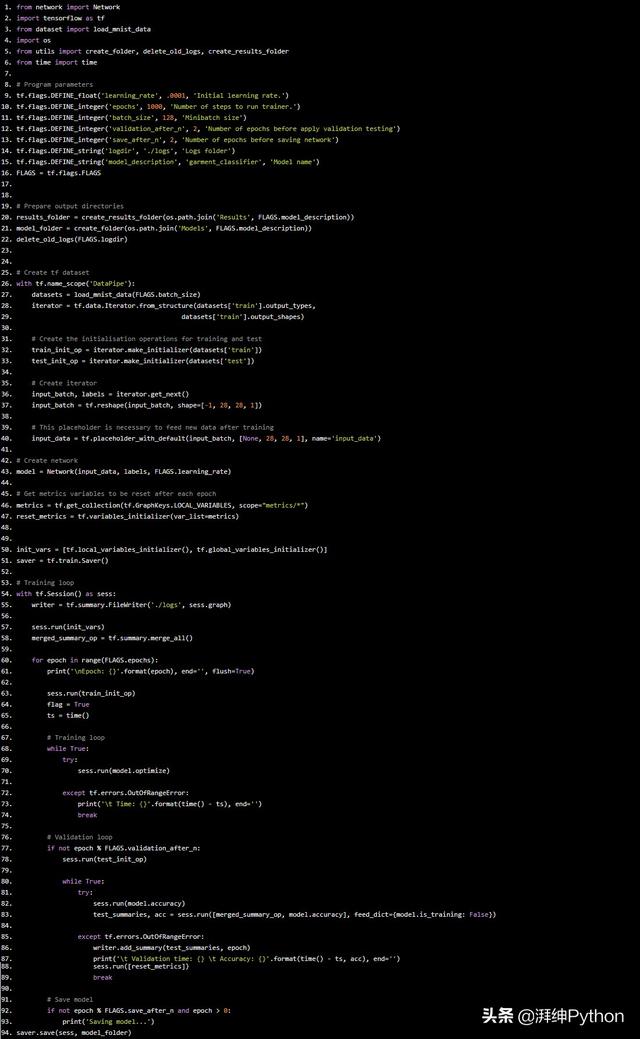
训练文件允许您观察您的准确性和损失如何随着时间的推移而变化。这些是我的结果:
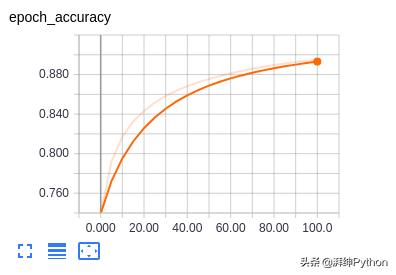
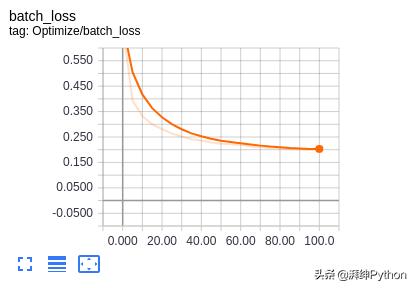
请记住,当我们训练模型时,我们必须使用不同的数据集验证我们的数据,以避免过度拟合问题。在这种情况下,我们可以使用Fashion MNIST测试集!
3.进行模型评估
一旦网络经过训练和保存,我们就可以使用获取的数据集来评估其性能。看看这段代码:
import tensorflow as tffrom dataset import load_unlabeled_datafrom utils import get_files, label_dictimport matplotlib.pyplot as pltimport matplotlib.image as mpimgimport numpy as npimport pandas as pd# Params from model to recovertf.flags.DEFINE_string('model_dir', 'Models/', 'Saved model directory')tf.flags.DEFINE_string('model_description', 'garment_classifier', 'Model name')tf.flags.DEFINE_string('data_path', 'Data/Images', 'Images folder path')tf.flags.DEFINE_integer('batch_size', 5, 'Minibatch size')FLAGS = tf.flags.FLAGS# Create graphgraph = tf.Graph()# Restore networkwith tf.Session(graph=graph) as sess: # Prepare data to predict filenames = get_files(FLAGS.data_path) filenames = ['Data/Images/'+i for i in ['1.png', '5.png', '108.png', '175.png', '33.png']] dataset = load_unlabeled_data(filenames, FLAGS.batch_size) iterator = dataset.make_initializable_iterator() input_batch = iterator.get_next() saver = tf.train.import_meta_graph(FLAGS.model_dir+'{}.meta'.format(FLAGS.model_description)) saver.restore(sess, tf.train.latest_checkpoint(FLAGS.model_dir)) # Recover tensors and ops from graph input_data = graph.get_tensor_by_name('DataPipe/input_data:0') prediction = graph.get_tensor_by_name('Network/output_class:0') sess.run(iterator.initializer) # Simple test to show results f, axarr = plt.subplots(1,5) images = sess.run(input_batch) labels = sess.run(prediction, feed_dict={input_data: images}) for i in range(5): img = mpimg.imread(filenames[i]) axarr[i].imshow(img) axarr[i].axis('off') axarr[i].set_title(label_dict[labels[i]]) plt.show() # Tag the whole dataset predicted_labels = [] sess.run(iterator.initializer) while True: try: images = sess.run(input_batch) labels = sess.run(prediction, feed_dict={input_data: images}) predicted_labels.append(labels) except tf.errors.OutOfRangeError: break predicted_labels = [label_dict[i] for i in np.concatenate(predicted_labels)] labeled_data = pd.DataFrame({'filenames': filenames, 'labels': predicted_labels})labeled_data.to_csv('labeled_data.csv')
模型评估指标用于评估模型和数据之间的拟合度,比较不同模型,在模型选择的背景下,以及预测模型准确性。
import osimport shutildef create_results_folder(results_folder='Results'): for folder in ['Test', 'Train']: if not os.path.exists(os.path.join(results_folder, folder)): os.makedirs(os.path.join(results_folder, folder)) return results_folderdef create_folder(folder): if os.path.exists(folder): delete_old_logs(folder) os.makedirs(folder) return folderdef delete_old_logs(logdir): try: shutil.rmtree(logdir) except: returndef get_files(base_dir): files = [os.path.join(base_dir, file) for file in os.listdir(base_dir)] return fileslabel_dict = { 0: 'T-shirt/top', 1: 'Trouser', 2: 'Pullover', 3: 'Dress', 4: 'Coat', 5: 'Sandal', 6: 'Shirt', 7: 'Sneaker', 8: 'Bag', 9: 'Ankle boot'}
10个类别如下:
0 => T恤/上衣,1 =>裤子,2 =>套衫,3 =>裙子,4 =>外套,5 =>凉鞋,6 =>衬衫,7 =>运动鞋,8 =>背包,9 =>踝靴。
这里很简单。我在这里做的是恢复网络并加载未标记的数据。我恢复了两个重要的张量,这些张量用于提供新数据和输出网络预测。最后,我将5个不同的图像传递给网络,这就是我得到的:

这就是我们使用Python在神经网络中构建了一个简单的模型。















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









