





导读:本文主要介绍Google发表在KDD 2019的图嵌入工业界最新论文[1],提出Cluster-GCN,高效解决工业界训练大规模深度图卷积神经网络问题,性能大幅提升基础上依靠可训练更深层网络达到SOTA效果,并开源了源代码。
作者:yyl424525,遵循 CC4.0BY 版权协议
来源: https:// blog.csdn.net/yyl424525 /article/details/100057907
更多关于深度推荐系统优质内容请关注如下频道。
知乎专栏:深度推荐系统
微博:深度传送门
公众号:深度传送门
摘要
图卷积网络(GCN)已经成功地应用于许多基于图形的应用,然而,大规模的GCN的训练仍然具有挑战性。目前基于SGD的算法要么面临着随GCN层数呈指数增长的高计算成本,要么面临着保存整个图形和每个节点的embedding到内存的巨大空间需求。本文提出了一种新的基于图聚类结构且适合于基于SGD训练的GCN算法 — Cluster-GCN。
Cluster-GCN的工作原理如下:在每个步骤中,它对一个与通过用图聚类算法来区分的密集子图相关联的一组节点进行采样,并限制该子图中的邻居搜索。这种简单且有效的策略可以显著提高内存和计算效率,同时能够达到与以前算法相当的测试精度。
为了测试算法的可扩展性,作者创建了一个新的Amazon2M数据集,它有200万个节点和6100万个边,比以前最大的公开可用数据集(Reddit)大5倍多。在该数据上训练三层GCN,Cluster-GCN比以前最先进的VR-GCN(1523秒vs 1961秒)更快,并且使用的内存更少(2.2GB vs 11.2GB)。此外,在该数据上训练4层GCN,Cluster-GCN可以在36分钟内完成,而所有现有的GCN训练算法由于内存不足而无法训练。此外,Cluster-GCN允许在短时间和内存开销的情况下训练更深入的GCN,从而提高了使用5层Cluster-GCN的预测精度,作者在PPI数据集上实现了最先进的test F1 score 99.36,而之前的最佳结果是98.71。
背景介绍
图卷积网络(GCN)[9]在处理许多基于图的应用中日益流行,包括半监督节点分类[9]、链路预测[17]和推荐系统[15]。对于一个图,GCN采用图卷积运算逐层地获取节点的embedding:在每一层,要获取一个节点的embedding,需要通过采集相邻节点的embedding,然后进行一层或几层线性变换和非线性激活。最后一层embedding将用于一些最终任务。例如,在节点分类问题中,最后一层embedding被传递给分类器来预测节点标签,从而可以对GCN的参数进行端到端的训练。
由于GCN中的图卷积运算(operator)需要利用图中节点之间的交互来传播embeddings,这使得训练变得相当具有挑战性。不像其他神经网络,训练损失可以在每个样本上完美地分解为单独的项(decomposed into individual terms),GCN中的损失项(例如单个节点上的分类损失)依赖于大量的其他节点,尤其是当GCN变深时。由于节点依赖性,GCN的训练非常慢,需要大量的内存——反向传播需要将计算图上的所有embeddings存储在GPU内存中。
现有GCN训练算法缺陷
为了证明开发可扩展的GCN训练算法的必要性,文中首先讨论了现有方法的优缺点,包括:内存需求、每个epoch的时间、每个epoch收敛速度。
这三个因素是评估训练算法的关键。注意,内存需求直接限制了算法的可扩展性,后两个因素结合在一起将决定训练速度。在接下来的讨论中,用N为图中的节点数,F为embedding的维数,L为分析经典GCN训练算法的层数。
- GCN的第一篇论文提出了全批次梯度下降(Full-batch gradient descent)。要计算整个梯度,它需要存储所有中间embeddings,导致O(NFL)内存需求,这是不可扩展的。
- GraphSAGE中提出了Mini-batch SGD。它可以减少内存需求,并在每个epoch执行多次更新,从而加快了收敛速度。然而,由于邻居扩展问题,mini-batch SGD在计算L层单个节点的损失时引入了大量的计算开销。
- VR-GCN提出采用variance减少技术来减小邻域采样节点的大小。但它需要将所有节点的所有中间的embeddings存储在内存中,从而导致O(NFL)内存需求。
朴素Cluster-GCN
作者定义了“Embedding utilization”的概念来表达计算效率。如果节点i在第l层的embedding在计算第l+1层的embeddings时被重用了u次,那么就说相应的的embedding utilization是u。
下表中总结了现有GCN训练算法相应的时间和空间复杂度。显然,所有基于SGD的算法的复杂度都和层数呈指数级关系。对于VR-GCN,即使r很小,也会产生超出GPU内存容量的巨大空间复杂度。
本文提出的的Cluster-GCN算法,它实现了两全其美的效果:即每个epoch和full gradient descent具有相同的时间复杂度, 同时又能与朴素GD具有相同的空间复杂度。

文中的Cluster-GCN技术是由以下问题驱动的:在mini-batch SGD更新中,我们可以设计一个batch和相应的计算子图来最大限度地提高embedding utilization吗?文中使用了图聚类算法来划分图。图聚类的方法,旨在在图中的顶点上构建分区,使簇内连接远大于簇间连接,从而更好地捕获聚类和社区结构。
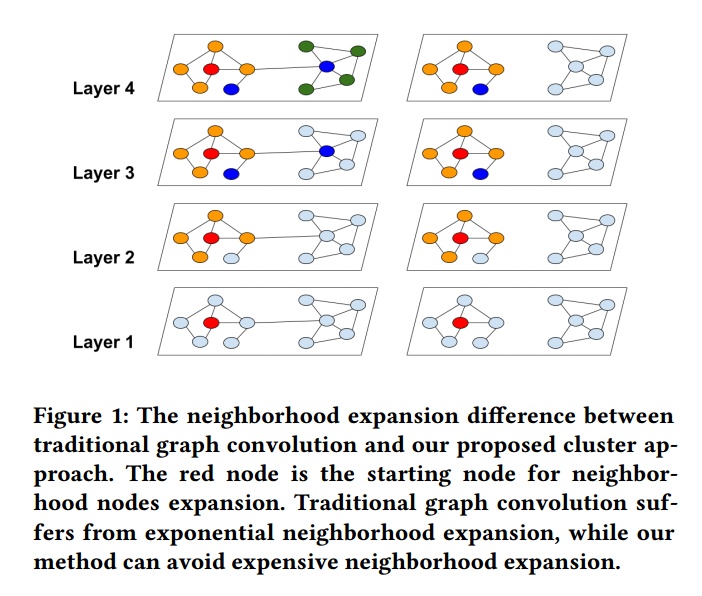
下图展示了两种不同的节点分区策略:随机分区和clustering分区。可以看到,cluster-GCN可以避免大量的邻域搜索,并且集中在每个簇中的邻居上。作者使用随机分割和Metis聚类方法将图分成10个部分。然后使用一个分区作为一个batch来执行SGD更新。在相同的时间段内,使用聚类划分可以获得更高的精度。这表明使用图聚类是很重要的,分区不应该随机形成。
随机多聚类
尽管朴素Cluster-GCN实现了良好的时间和空间复杂度,但仍然存在两个潜在问题:
- 图被分割后,一些连接被删除。因此,性能可能会受到影响。
- 图聚类算法往往将相似的节点聚集在一起,因此聚类的分布可能不同于原始数据集,从而导致在执行SGD更新时对 full gradient的估计有偏差。
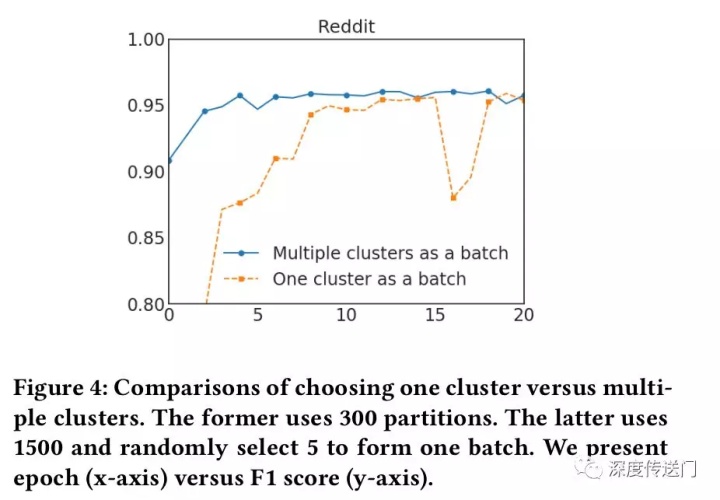
为了解决上述问题,文中提出了一种随机多聚类方法,在簇接之间进行合并,并减少batch间的差异(variance)。作者首先用一个较大的p把图分割成p个簇V1,...,Vp,然后对于SGD的更新重新构建一个batch B,而不是只考虑一个簇。随机地选择q个簇,定义为t1,...,tq ,并把它们的节点包含到这个batch B中。此外,在选择的簇之间的连接也被添加回去。作者在Reddit数据集上进行了一个实验,证明了该方法的有效性。
实验结果
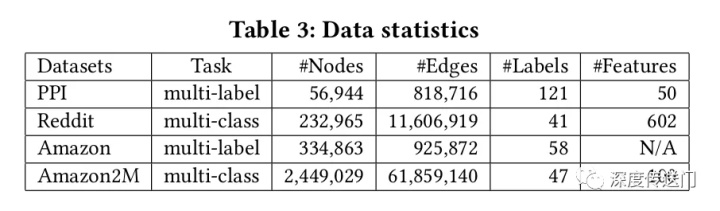
文中评估了所提出的针对四个公共数据集的多标签和多类分类两个任务的GCN训练方法,数据集统计如表3所示。Reddit数据集是迄今为止为GCN所看到的最大的公共数据集,为了测试GCN训练算法在大规模数据上的可扩展性,作者基于Amazon co-purchase network构建了一个更大的图Amazon2M,包含超过200万个节点和6100万条边。
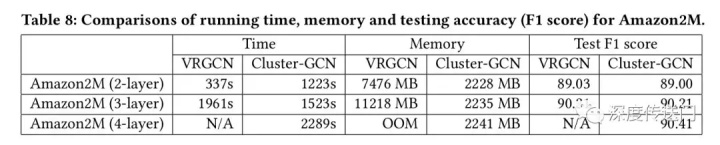
作者比较了不同层次GCNs的VRGCN在训练时间、内存使用和测试准确度(F1分数)方面的差异。从表中可以看出
- 训练两层时VRGCN比Cluster-GCN快,但是当增加一层网络,却慢于实现相似准确率的Cluster-GCN;
- 在内存使用方面,VRGCN比Cluster-GCN使用更多的内存(对于三层的情况5倍多)。当训练4层GCN的时候VRGCN将被耗尽,然而Cluster-GCN当增加层数的时候并不需要增加太多的内存,并且Cluster-GCN对于这个数据集训练4层的GCN将实现最高的准确率。
最后,作者开源了源代码:google-research/google-research。另外第三方PyTorch也有实现:https://github.com/benedekrozemberczki/ClusterGCN。
如果有耐心读到这里的话,就关注一下公众号吧:)

参考文献
1. Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









