





1、 交换类排序
基本思想:
两两比较待排序记录的关键字,如果发生逆序(即排列顺序与排序后的次序正好相反),则交换之,直到所有记录都排好序为止。
交换排序的主要算法有:
(1) 冒泡排序
(2) 快速排序
2、 冒泡排序(Bubble Sort)
基本思想:
每趟不断将相邻记录两两比较,并按“前小后大”(或“前大后小”)规则交换。
步骤:
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
void 算法分析:
优点:每趟结束时,不仅能找出一个最大值到最后面位置,还能同时部分理顺其他元素;一旦下趟没有交换发生,还可以提前结束排序。
时间复杂度 :O(n²)
空间效率:O(1) —只在交换时用到一个辅助单元
算法稳定性:稳定排序算法
实 质:把小(大)的元素往前(后)调
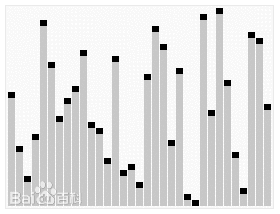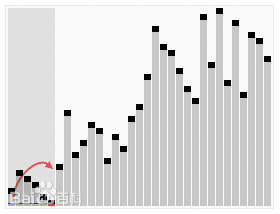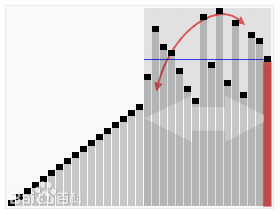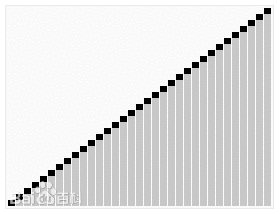
3. 快速排序(Quicksort)
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
步骤:
- 从后向前比,用基准值和最后一个值比较,如果比基准值小,就交换位置,否则就接着往前找,直到找到第一个比基准值小的值。
- 在从后往前找到第一个比基准值小的值并交换位置后,又开始从前往后比较。如果有比基准值大的,就交换位置;如果没有,则继续比较下一个,直到找到第一个比基准值大的值才交换位置。
- 重复执行以上步骤,直到从前向后比较的索引大于等于从后往前的索引,则结束一次循环。这时,对于基准值来说,左右两边都是有序的数据序列。
- 重复循环以上过程,分别比较左右两边的序列,直到整个数据序列有序。
优点:通过一次交换消除多个逆序,所以特别快!
public 时间效率:O(nlog2n)(但最坏情况下为:O(n2))
平均时间复杂度: O(nlog2n)。
稳 定 性: 不 稳 定
为改善最坏情况下的时间性能,可采用其他方法选取中间数。通常采用“三者值取中”方法,即比较H->r[low].key、H->r[high].key与H->r[(low+high)/2].key,取三者中关键字为中值的元素为中间数。
从空间性能上看,尽管快速排序只需要一个元素的辅助空间,但快速排序需要一个栈空间来实现递归。最好的情况下,即快速排序的每一趟排序都将元素序列均匀地分割成长度相近的两个子表,所需栈的最大深度为log2(n+1);但最坏的情况下,栈的最大深度为n。这样,快速排序的空间复杂度为O(log2n))。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









