





原文链接:https://medium.com/swlh/an-intuitive-visual-interpretability-for-convolutional-neural-networks-9630007c5857
翻译:【计算机视觉联盟】公众号团队
推荐资源
机器学习手推笔记(https://github.com/Sophia-11/Machine-Learning-Notes,直达笔记地址)
笔记预览


第一个卷积神经网络是Alexander Waibel在1987年提出的时延神经网络(TDNN)[5]。TDNN是应用于语音识别问题的卷积神经网络。它使用FFT预处理语音信号作为输入。它的隐藏层由两个一维卷积核组成,以提取频域中的平移不变特征[6]。在TDNN出现之前,人工智能领域在反向传播(BP)研究中取得了突破性进展[7],因此TDNN能够使用BP框架进行学习。在原作者的对比实验中,在相同条件下,TDNN的性能要优于隐马尔可夫模型(HMM),后者是1980年代语音识别的主流算法[6]。
1988年,张伟提出了第一个二维卷积神经网络转换不变人工神经网络(SIANN),并将其应用于医学图像的检测[1]。Yann LeCun还在1989年,为计算机视觉问题构建了卷积神经网络[2],即LeNet的原始版本中。LeNet包含两个卷积层,两个完全连接层,总共60,000个学习参数,其规模远远超过TDNN和SIANN,其结构非常接近现代卷积神经网络[4]。LeCun(1989)采用[2]随机梯度下降(SGD)进行随机初始化后的权值学习。后来的深度学习学院保留了这一策略。此外,LeCun(1989)在讨论其网络结构[2]时首次使用了卷积一词,并以此命名卷积神经网络。
对于深度卷积神经网络,经过多次卷积和合并后,其最后的卷积层包含最丰富的空间和语义信息。卷积神经网络中的每个卷积单元实际上都扮演着对象检测器的角色,它本身具有定位对象的能力但是其中包含的信息对于人类来说是难以理解的,并且难以以视觉方式显示。
在本文中,我们将回顾类激活映射(CAM),CAM借鉴了著名的论文《网络中的网络》(Network In Network)中的思想,用全局平均池(GAP)代替了全连接层。
所提出的CNN网络具有强大的图像处理和分类功能,同时还可以定位图片的关键部分。
卷积层(Convolution Layers)
卷积神经网络(CNN) ,主要是通过单个过滤器连续提取特征,从局部特征到总体特征,以便进行图像识别等功能。
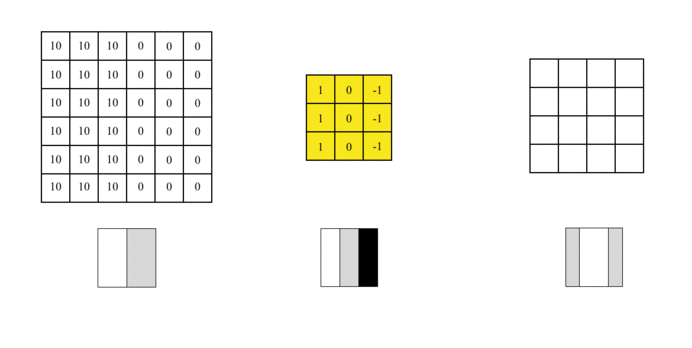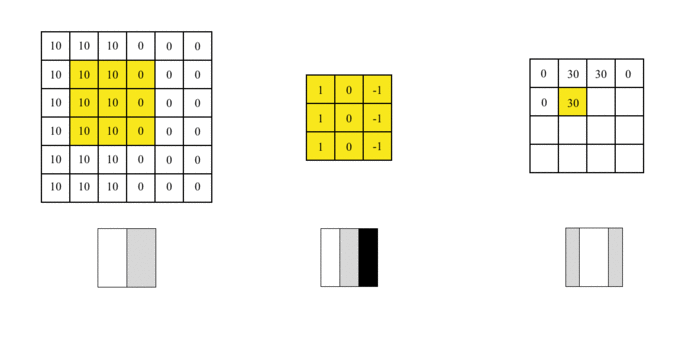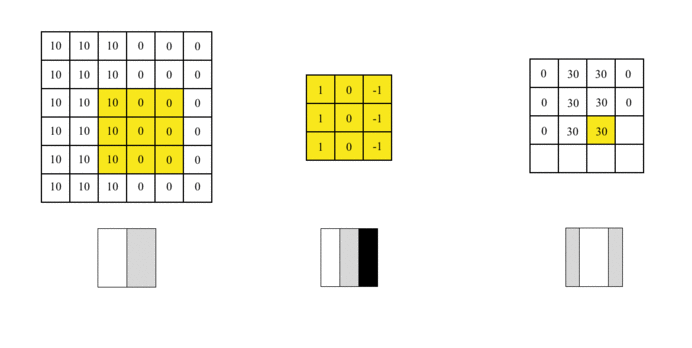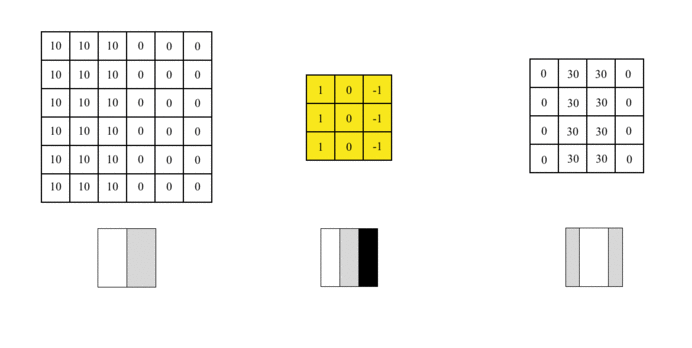
假设我们需要处理尺寸为6x6像素的单通道灰度图像,将其转换为二维矩阵,如下所示:
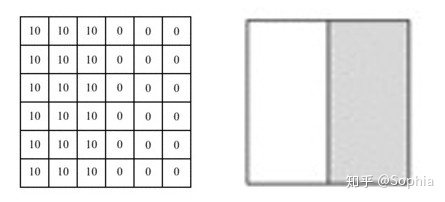
图片中的数字表示该位置的像素值,像素值越大,颜色越亮。图片中间的两种颜色之间的分界线是我们要检测的边界。
我们可以设计一个过滤器(也称为kernel)来检测该边界。然后,将该过滤器与输入图片进行曲面组合以提取边缘信息,可以将图片上的卷积操作简化为以下动画:
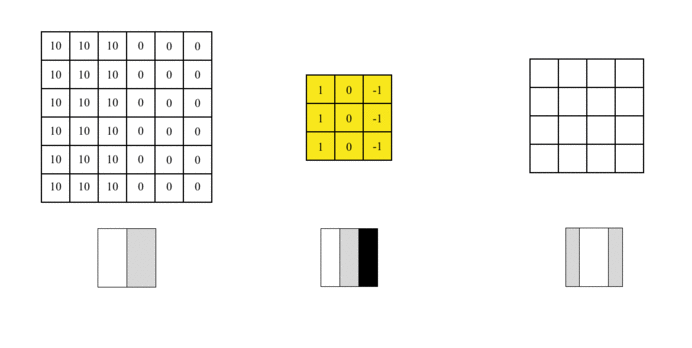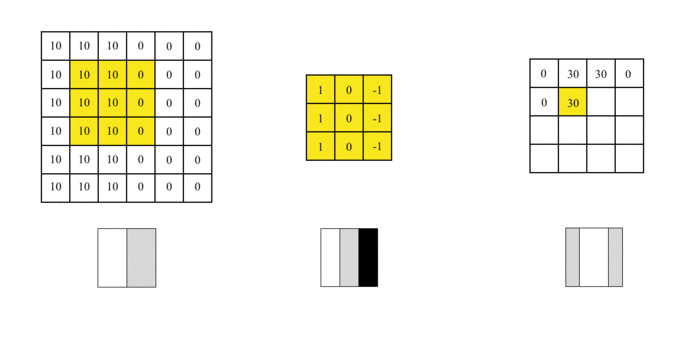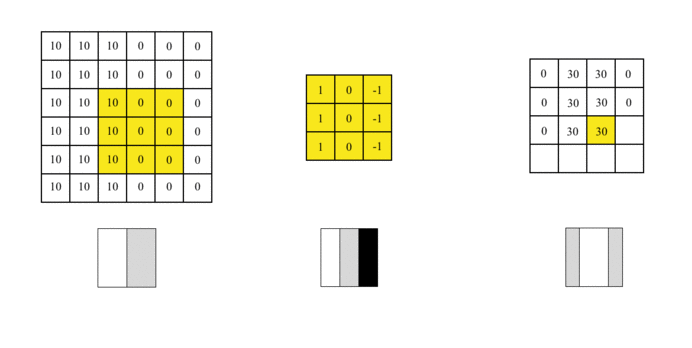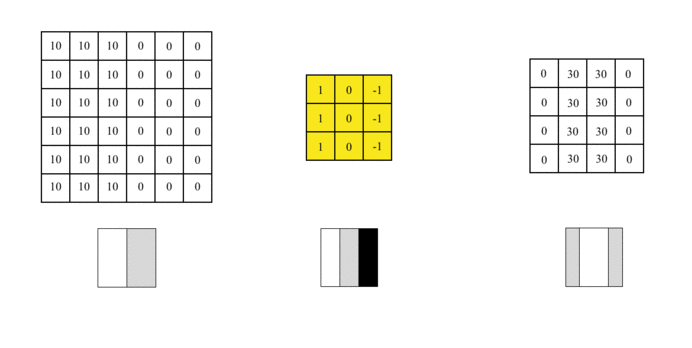
我们使用此过滤器覆盖图片,覆盖与过滤器一样大的区域,将相应的元素相乘,然后求和。计算一个区域后,移至其他区域,然后计算直到覆盖原始图片的所有区域。
输出矩阵称为特征图(Feature Map),它的中间颜色较浅,两侧颜色较深,反映了原始图像中间的边界。
卷积层主要包含两个部分,一个过滤器和一个特征图,这是数据流经CNN网络的第一个神经层,通过学习使用的过滤器越多,将自动调整CNN的过滤器矩阵,将得到更多的特征。
要设置的常规超参数包括过滤器的数量,大小和步长。
池化层(Pooling)
池化也称为空间池化或子采样。其主要功能是提取特定区域的主要特征并减少参数数量,以防止模型过度拟合。
这里没有我们需要学习的参数。需要指定的超参数包括池化类型,常用的方法包括Maxpooling或Averagepooling,窗口大小和步长。通常,我们更多地使用Maxpooling,并且通常采用大小为(2,2),步长为2的过滤器,因此在合并之后,输入长度和宽度将减少2倍,并且通道不会更改,如下图所示:

最大值在合并窗口内获取,并在特征图矩阵上顺序合并后生成新矩阵。同样,我们也可以使用求平均或求和的方法,但是在通常情况下,使用最大值方法获得的效果相对更好。
经过几次卷积和合并后,我们最终将多维数据展平为一维数组,然后将它们连接到完全连接层。

它的主要功能是基于通过卷积层和池化层提取的特征集对处理后的图片进行分类。
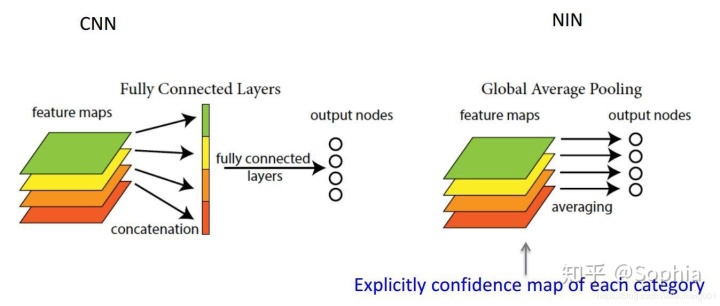
诸如GoogleNet [10]之类的全卷积神经网络避免使用全连接层,而使用全局平均池(GAP)。这样,不仅可以减少参数以避免过度拟合,而且可以创建到类别关联的特征图。
全局平均池化层(Global Average Pooling)
长期以来,完全连接的网络一直是CNN分类网络的标准结构。通常,完全连接后将具有用于分类的激活功能。但是完全连接的层具有大量参数,这会降低训练速度,并且容易过拟合。
在网络中的网络 [9]中,提出了全局平均池的概念来代替完全连接的层。
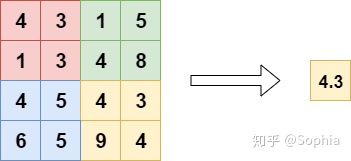
全局平均池和局部平均池之间的区别是池窗口。局部平均池化包括对特征图中的子区域取平均值,而在全局平均池中,我们对整个特征图取平均。
使用全局平均池而不是完全连接的层会大大减少参数的数量。
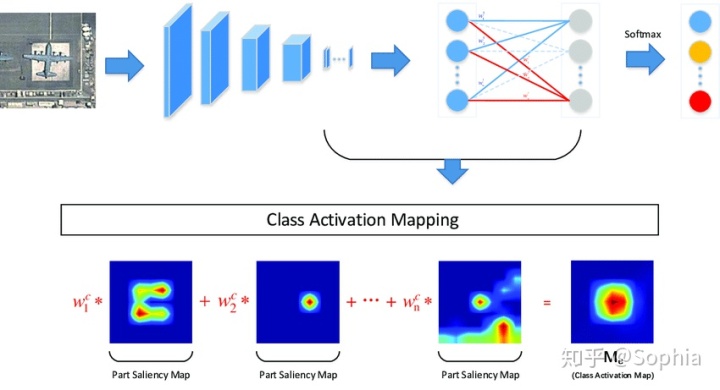
类激活图(Class Activation Map)
当使用全局平均池化时,最后的卷积层被迫生成与我们所针对的类别数量相同数量的特征图,这将为每个特征图赋予非常清晰的含义,即类别可信度图 [11]。
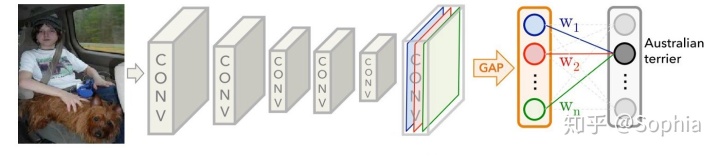
从图中可以看出,在GAP之后,我们获得了最后一个卷积层的每个特征图的平均值,并通过加权和获得了输出。对于每个类别C,每个特征图k的平均值具有相应的权重w。
训练CNN模型后,我们可以获得一个热图来解释分类结果。例如,如果我们要解释C类的分类结果。我们取出与类C对应的所有权重,并找到它们对应的特征图的加权和。由于此结果的大小与特征图一致,因此我们需要对其进行过采样并将其覆盖在原始图像上,如下所示:
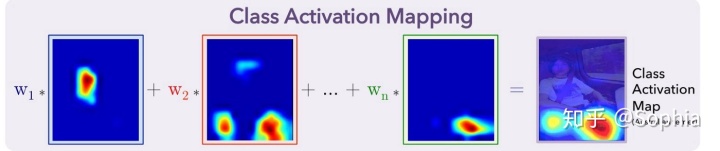
通过这种方式,CAM以热图的形式告诉我们,模型集中在用于确定图片的c类中的像素上。
结论
CAM的解释效果一直很好,但是有一个缺点,那就是它需要修改原始模型的结构,从而导致需要重新训练模型,这极大地限制了它的使用场景。如果模型已经在线,或者培训成本很高,那么我们几乎不可能对其进行再培训。
References
- Zhang, W., 1988. Shift-invariant pattern recognition neural network and its optical architecture. In Proceedings of annual conference of the Japan Society of Applied Physics.
- . LeCun, Y. and Bengio, Y., 1995. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10), 1995.
- LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W. and Jackel, L.D., 1989. Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), pp.541–551.
- LeCun, Y., Kavukcuoglu, K. and Farabet, C., 2010. Convolutional networks and applications in vision. In ISCAS(Vol. 2010, pp. 253–256).
- Waibel, A., 1987. Phoneme recognition using time-delay neural networks. Meeting of the Institute of Electrical, Information and Communication Engineers (IEICE). Tokyo, Japan.
- Waibel, A., Hanazawa, T., Hinton, G., Shikano, K. and Lang, K., 1989. Phoneme recognition using time-delay neural networks, IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(3), pp. 328–339.
- Rumelhart, D.E., Hinton, G.E. and Williams, R.J., 1986. Learning representations by back-propagating errors. nature, 323(6088), p.533.
- LeCun, Y., Bottou, L., Bengio, Y. and Haffner, P., 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), pp.2278–2324.
- Min Lin, Qiang Chen, Shuicheng Yan : Network In Network.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich: Going Deeper with Convolutions.
- Bolei Zhou andAditya Khosla and Agata Lapedriza andAude Oliva andAntonio Torralba :Learning Deep Features for Discriminative Localization














 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









