





二维偏序是这样一类问题:已知点对的序列
什么叫偏序呢?数学中讲偏序是满足自反性、反对称性和传递性的序关系。但这听上去太抽象了,事实上,在二维的情形,我们分别对两个属性定义序关系,一定能得到一种偏序关系:
好像更抽象了(逃)。我们还是来举例子吧:
POJ 2352 Stars
Description
Astronomers often examine star maps where stars are represented by points on a plane and each star has Cartesian coordinates. Let the level of a star be an amount of the stars that are not higher and not to the right of the given star. Astronomers want to know the distribution of the levels of the stars.
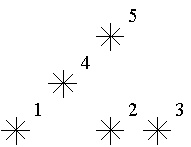
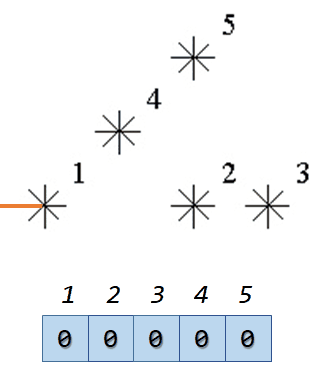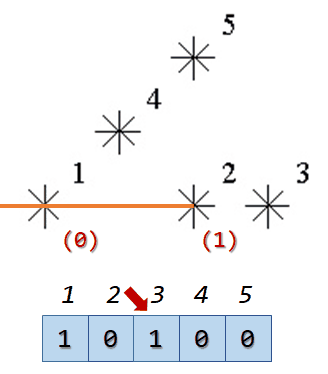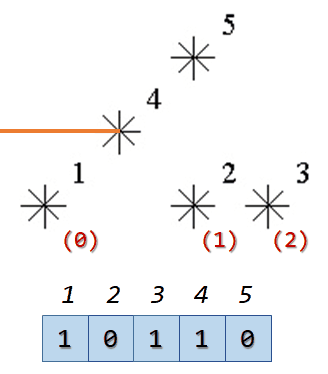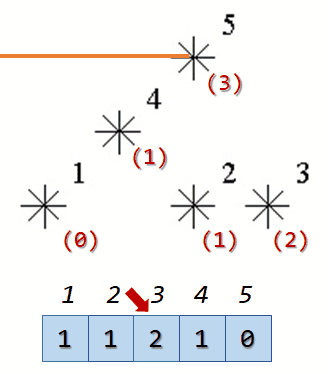
For example, look at the map shown on the figure above. Level of the star number 5 is equal to 3 (it's formed by three stars with a numbers 1, 2 and 4). And the levels of the stars numbered by 2 and 4 are 1. At this map there are only one star of the level 0, two stars of the level 1, one star of the level 2, and one star of the level 3.
You are to write a program that will count the amounts of the stars of each level on a given map. Input
The first line of the input file contains a number of stars N (1<=N<=15000). The following N lines describe coordinates of stars (two integers X and Y per line separated by a space, 0<=X,Y<=32000). There can be only one star at one point of the plane. Stars are listed in ascending order of Y coordinate. Stars with equal Y coordinates are listed in ascending order of X coordinate. Output
The output should contain N lines, one number per line. The first line contains amount of stars of the level 0, the second does amount of stars of the level 1 and so on, the last line contains amount of stars of the level N-1.
题意是,给你一张星图,定义星星的等级是既不在它上面也不在它右边的星星的数量,求每个等级的星星的数量。这其实就是定义了这样的偏序关系:
二维偏序问题一般用树状数组解决。
这道题的数据已经以y坐标为第一关键词、x坐标为第二关键词排好序了,但一般是需要我们手动排一下序的。排序的目的是让所有可能小于当前点的点都在当前点前面被处理。然后我们把这些点的x坐标一个一个地压入树状数组。
因为已经确保了所有可能小于当前点的点都在当前点前面出现,我们只需要使用树状数组不断动态求前缀和即可。树状数组的下标需要从1开始,所以在处理的时候还要稍微注意一下。
#include <cstdio>
#define MAXN 15010
#define MAXM 32010
#define lowbit(x) ((x) & (-x))
// 树状数组
int tree[MAXM], ans[MAXN];
void update(int i, int x)
{
for (; i <= MAXM; i += lowbit(i))
tree[i] += x;
}
int query(int n)
{
int ans = 0;
for (; n; n -= lowbit(n))
ans += tree[n];
return ans;
}
int main()
{
int n, x;
scanf("%d", &n);
for (int i = 0; i < n; ++i)
{
scanf("%d%*d", &x); // 已经排好序了,y坐标可以不要了
ans[query(x + 1)]++; // 统计
update(x + 1, 1); // 更新,注意这两行都要+1
}
for (int i = 0; i < n; ++i)
{
printf("%dn", ans[i]);
}
return 0;
}
实际上,这道题是最简单的二维偏序。其他种类的偏序方式往往需要转化成这种关系进行处理。一个很常见的例子是逆序对。如这道模板题:
POJ 2299 Ultra-QuickSort
Description
In this problem, you have to analyze a particular sorting algorithm. The algorithm processes a sequence of n distinct integers by swapping two adjacent sequence elements until the sequence is sorted in ascending order. For the input sequence
9 1 0 5 4 ,
Ultra-QuickSort produces the output
0 1 4 5 9 .
Your task is to determine how many swap operations Ultra-QuickSort needs to perform in order to sort a given input sequence. Input
The input contains several test cases. Every test case begins with a line that contains a single integer n < 500,000 -- the length of the input sequence. Each of the the following n lines contains a single integer 0 ≤ a[i] ≤ 999,999,999, the i-th input sequence element. Input is terminated by a sequence of length n = 0. This sequence must not be processed. Output
For every input sequence, your program prints a single line containing an integer number op, the minimum number of swap operations necessary to sort the given input sequence.
虽然我在树状数组的笔记中介绍过逆序对的求法,但那时我还的认识还不够本质。其实逆序对本质上就是一种二维偏序:
我们可以先用上面的方法求出非严格顺序对,然后用总对数去减(就像之前那篇笔记那样)。但也有另一种方法,注意到数据很大,我们需要离散化。所以只要在离散化时,将数据按从大到小的顺序排序,就可以转化为之前的那种偏序关系了。部分代码如下(省略树状数组和快读):
const int MAXN = 500005;
int A[MAXN], C[MAXN], L[MAXN], tree[MAXN];
int main()
{
int n;
while (n = read())
{
ll sum = 0;
for (int i = 0; i < n; ++i)
A[i] = read();
memset(tree, 0, sizeof(tree));
memcpy(C, A, sizeof(int) * n);
sort(C, C + n, greater<int>());
int l = unique(C, C + n) - C;
for (int i = 0; i < n; ++i)
L[i] = lower_bound(C, C + l, A[i], greater<int>()) - C + 1;
for (int i = 0; i < n; ++i)
{
update(L[i], 1);
sum += query(L[i] - 1);
}
cout << sum << endl;
}
return 0;
}
再来看一个不那么明显的二维偏序题:
CF1311F Moving Points
There arepoints on a coordinate axis
. The
-th point is located at the integer point
and has a speed
can be non-integer) is calculated as. It is guaranteed that no two points occupy the same coordinate. All nn points move with the constant speed, the coordinate of the ii-th point at the moment tt (tt
.
Consider two pointsand
. Let
non-integer). It means that if two pointsbe the minimum possible distance between these two points over any possible moments of time (even
and
coincide at some moment, the value
will be
.
Your task is to calculate the valueInput(the sum of minimum distances over all pairs of points).
The first line of the input contains one integer(
) — the number of points.
The second line of the input contains nn integers, where
is the initial coordinate of the
-th point. It is guaranteed that all
are distinct.
The third line of the input contains nn integers, where vivi is the speed of the
Output-th point.
Print one integer — the value(the sum of minimum distances over all pairs of points).
题意是,给出直线上若干个不同的动点的初始位置和速度,求每两个点之间能达到的最短距离之和。
注意到,对于两个点
但是这里不是求点对的数量而是求距离之和,所以需要使用两个树状数组,一个维护目前为止所有点到原点的距离之和
void update(ll x, ll d, ll tree[])
{
for (ll i = x; i < MAXN; i += lowbit(i))
tree[i] += d;
}
ll query(ll x, ll tree[])
{
ll sum = 0;
for (ll i = x; i > 0; i -= lowbit(i))
sum += tree[i];
return sum;
}
pair<ll, ll> P[MAXN];
ll C[MAXN], L[MAXN], len[MAXN], tot[MAXN];
int main()
{
ll n = read(), sum = 0;
for (int i = 0; i < n; ++i)
P[i].first = read();
for (int i = 0; i < n; ++i)
P[i].second = read();
for (int i = 0; i < n; ++i)
C[i] = P[i].second;
sort(P, P + n); // 排序
sort(C, C + n);
unique(C, C + n);
for (int i = 0; i < n; ++i)
L[i] = lower_bound(C, C + n, P[i].second) - C + 1; // 离散化
for (int i = 0; i < n; ++i)
{
update(L[i], P[i].first, len);
update(L[i], 1, tot);
sum += query(L[i], tot) * P[i].first - query(L[i], len);
}
cout << sum << endl;
return 0;
}
总而言之,最简单的二维偏序
而其他二维偏序关系,可以作不同的处理转化为最简单的二维偏序。例如:
-
逆序排序。
:把第一关键词的小于等于改成小于,需要在对第二关键词排序时进行
-
逆序排序。
把第一关键词的小于等于改成大于等于,需要在对第一关键词排序时进行
-
逆序排序。
把第一关键词的小于等于改成大于,需要在对两个关键词排序时都进行
-
:把第二关键词的小于等于改成小于,查询时使用
query(x-1)而不是query(x)。 -
离散化时进行逆序排序。
:把第二关键词的小于等于改成大于等于,对第二关键词
-
离散化时进行逆序排序,并且查询时使用
:把第二关键词的小于等于改成大于等于,对第二关键词
query(x-1)而不是query(x)。
前面两个例题没有对第二关键词逆序排序的原因,是它们都保证了第一关键词不重复,这样是小于还是小于等于就无所谓了,但一般的情形,还是需要自己写结构体实现的。
Pecco:算法学习笔记(目录)zhuanlan.zhihu.com















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









