





1、JSON(JavaScript Object Notation的简称)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。它是一种轻量级数据交换格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的一个子集。
2、准备数据
>>> obj = """
... {"name":"Wes",
... "places_lived":["United States", "Spain", "Germany"],
... "pet":null,
... "siblings":[{"name":"Scott", "age":25, "pet":"Zuko"}, {"name":"Katie", "age":33, "pet":"Cisco"}]
... }
... """
处理之后,则:
{
"name": "Wes",
"places_lived": [
"United States",
"Spain",
"Germany"
],
"pet": null,
"siblings": [
{
"name": "Scott",
"age": 25,
"pet": "Zuko"
},
{
"name": "Katie",
"age": 33,
"pet": "Cisco"
}
]
}
说明:
对象(字典)中所有的键都必须是字符串。
3、数据操作
>>> import json
>>> result = json.loads(obj)
>>> result
{u'pet': None, u'siblings': [{u'pet': u'Zuko', u'age': 25, u'name': u'Scott'}, {u'pet': u'Cisco', u'age': 33, u'name': u'Katie'}], u'name': u'Wes', u'places_lived': [u'United States', u'Spain', u'Germany']}
>>> type(result)
>>> asjson = json.dumps(result)
>>> asjson
'{"pet": null, "siblings": [{"pet": "Zuko", "age": 25, "name": "Scott"}, {"pet": "Cisco", "age": 33, "name": "Katie"}], "name": "Wes", "places_lived": ["United States", "Spain", "Germany"]}'
说明:
(1)许多Python库都可以读写JSON数据,我们将使用json,因为它是构建与Python标准库中的。通过json.loads即可将JSON字符串转换成Python形式。
(2)相反,json.dumps则将Python对象转换成JSON格式。
4、JSON与DataFrame
>>> import pandas as pd
>>> siblings = pd.DataFrame(result['siblings'], columns=['name', 'age'])
>>> siblings
name age
0 Scott 25
1 Katie 33
5、数据类型
下面这个列表简要地描述了Python内置数据类型(适用于Python 3.x):
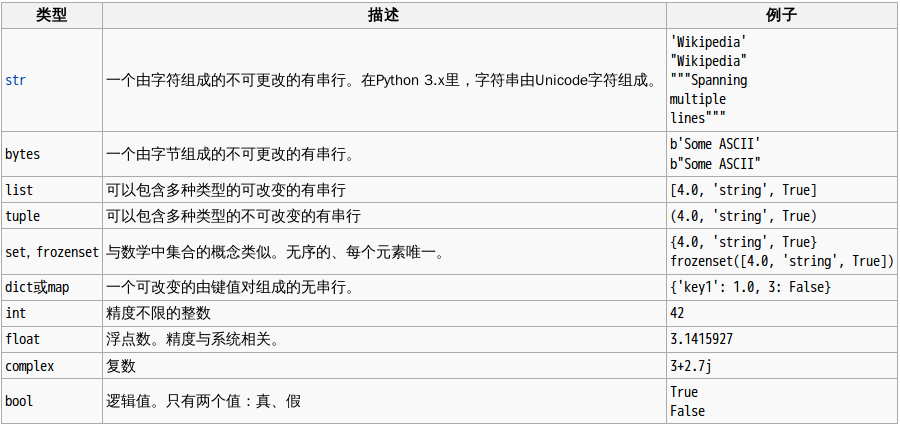
说明:
Python内置丰富的数据类型,除了各种数据类型,Python语言还用类型来表示函数、模块、类型本身、对象的方法、编译后的Python代码、运行时信息等等。因此,Python具备很强的动态性。
6、I/O操作
序列化(Serialization):将对象的状态信息转换为可以存储或可以通过网络传输的过程,传输的格式可以是JSON、XML等。反序列化就是从存储区域(JSON,XML)读取反序列化对象的状态,重新创建该对象。
Python2.6开始加入了JSON模块,无需另外下载,Python的Json模块序列化与反序列化的过程分别是encoding和decoding:
encoding:把一个Python对象编码转换成Json字符串。
decoding:把Json格式字符串解码转换成Python对象。
7、参考文献
[1] 《利用Python进行数据分析》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









