






hadoop多节点集群安装配置
为了后续Hadoop实验的进行,我们需要安装多节点的Hadoop集群(实现真正意义上的分布式存储)
本文将用4个节点组织,1个主节点和3个从节点。节点使用VMworkstiaon生成虚拟机来实现。
前排提示
建议在克隆生成节点时使用全部相同的用户名,在后续ssh连接的时候会带来很多方便。而且推荐使用不同的主机名。这也是后续如果出现各个节点进程都能启动但是web端无法显示的问题所在
JDK的安装
和上篇文章相同
sudo 然后查看java的版本来验证是否安装成功
java 将版本切换至最新
updateHadoop的解压安装
由于这次我们需要安装多节点集群,所以需要从主节点克隆出几台虚拟机,所以先进行hadoop的解压安装,减少后续工作量 。
在Ubuntu中下载Hadoop的安装包(我的ubuntu中预装了浏览器,所以之间通过搜索引擎下载的)
之后将其解压
sudo 要注意在解压前,要通过cd 命令进入下载文件所在的目录
然后移动到 /usr/local/hadoop
sudo 配置文件及其解释
配置环境
1设置Hadoop
提一嘴Linux的文本编辑命令gedit 个人认为比vi好用很多,但是我在使用中经常被神秘力量报错,每次都依靠重启大法续命,这里如果有懂的好哥哥,建议教教弟弟。
sudo 打开bashrc这个文件后添加路径,输入下面内容(本节的大多数操作都是打开文件添加或修改,使用sudo命令可以直接在文本编辑器里保存)。
export 然后再使用source命令试环境变量立刻生效,而不必重启
source 2.编辑Hadoop-env.sh
sudo 下面也是和上一节一样修改一下几个配置文件(配置信息源自网络),这里尝试对配置信息进行解释。(如果有不对的地方也希望大家指出)
1.core-site.xml
Hadoop Core的配置项,全局上配置。
这里只配置了临时文件目录,和端口
<该文件可以选用的配置信息可以见官方文档。
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xmlhadoop.apache.org2.hdfs-site.xml
对hdfs的局部配置
<具体配置信息
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xmlhadoop.apache.org3.mapred-site.xml
<4.yarn-site.xml
<创建目录和修改用户权限
这里也和上一篇文章相同,这里用户名为hadoop,详细解释可以看上篇文章
创建NameNode数据存储目录
sudo 创建DataNode数据存储
sudo 更改Hadoop目录的所有者
1、新建用户组
sudo 2、添加用户xx 到hadoop组
sudo 3、新用户修改登录密码,输入2遍确认
sudo 4、赋予hduser用户admin权限
sudo 5.更改Hadoop目录的所有者
sudo 在完成这一步后就可以从主节点克隆出3个从节点了。
ssh免密连接
首先先查看各个节点的ip地址,记录下来
我这里使用的是Ubuntu的操作系统,可以通过图形界面配置,setting→network→wired
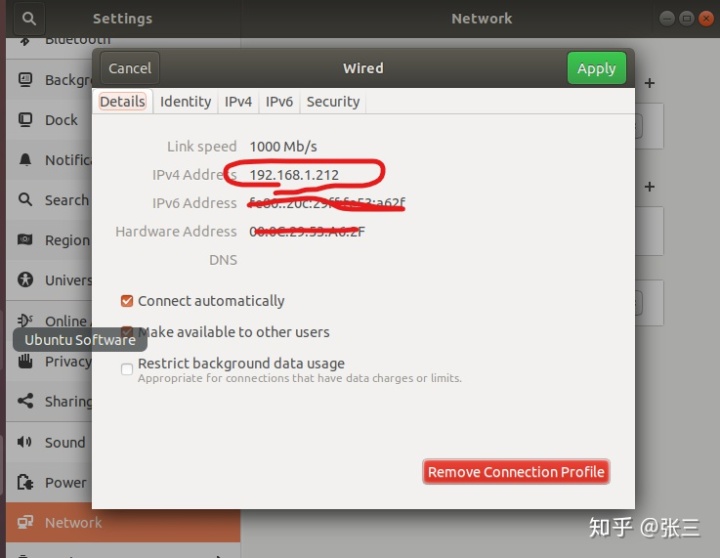
然后固定ip地址(因为DHCP服务器给每个虚拟机分配的IP地址有一段生命期,ip地址的变化,会让我们在后续的使用时需要重新配置文件)
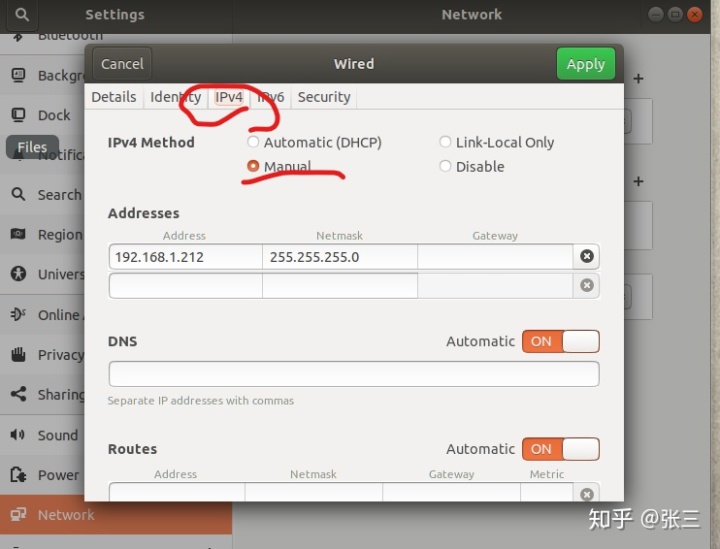
修改时,尽量不要选择太小的ip地址,防止被占用。
(ps之前在我的虚拟机上出现过network菜单没有wired选项的情况在尝试了一篇博客后解决了这个问题。)
sudo 之后再主节点上
su
实际上这个host的修改也可以通过手动打开host文件将节点名和对应ip地址输入。
# 在从节点上也创建密钥
su 将从节点写入workers(同样也可以手动打开修改)
echo 启动和测试
在主节点上输入
start测试各个节点的启动情况(使用jps命令)
主节点

从节点

访问localhost:50070(hadoop 2.xx以后版本的管理界面)
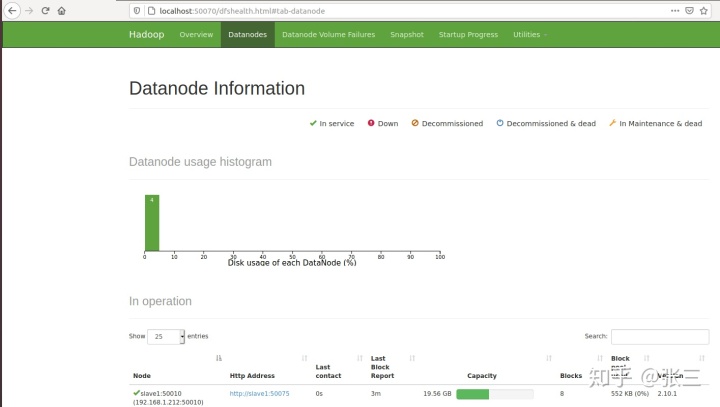
这个我们的集群就配置好了
(ps如果出现各个节点进程都可以正常启动,但是只显示一个节点,这里提供一个解决方案。可能是由于子节点克隆生成version相同,可以通过在各个节点上删除缓存,重新格式化来解决)















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









