





描述
爬取http://fundact.eastmoney.com/banner/pg.html#ln网站的数据,
要求:爬取所有基金(有27页)的基金代码、基金名称、单位净值、日期、日增长率、近1周、近1月、近3月、近6月、近1年、近2年、近3年、今年来、成立来和手续费|起购金额。将爬取的数据放入mariaDB数据库中。
环境描述
python 3.6.3
scrapy 1.4.0
步骤记录
创建scrapy项目
进入打算放代码的地方(F:\myPycharm_ws),创建项目funds,执行命令:
scrapy startproject funds
创建好项目后,查看会发现生成一些文件,这里对相关文件做下说明
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
接下来就可以使用pycharm打开项目进行开发了
设置在pycharm下运行scrapy项目
step 1:在funds项目里创建一个py文件(项目的任何地方都行)
from scrapy import cmdline
cmdline.execute("scrapy crawl fundsList".split())
step 2:配置 Run --> Edit Configurations (本人测试,不配置该步骤,也可运行)
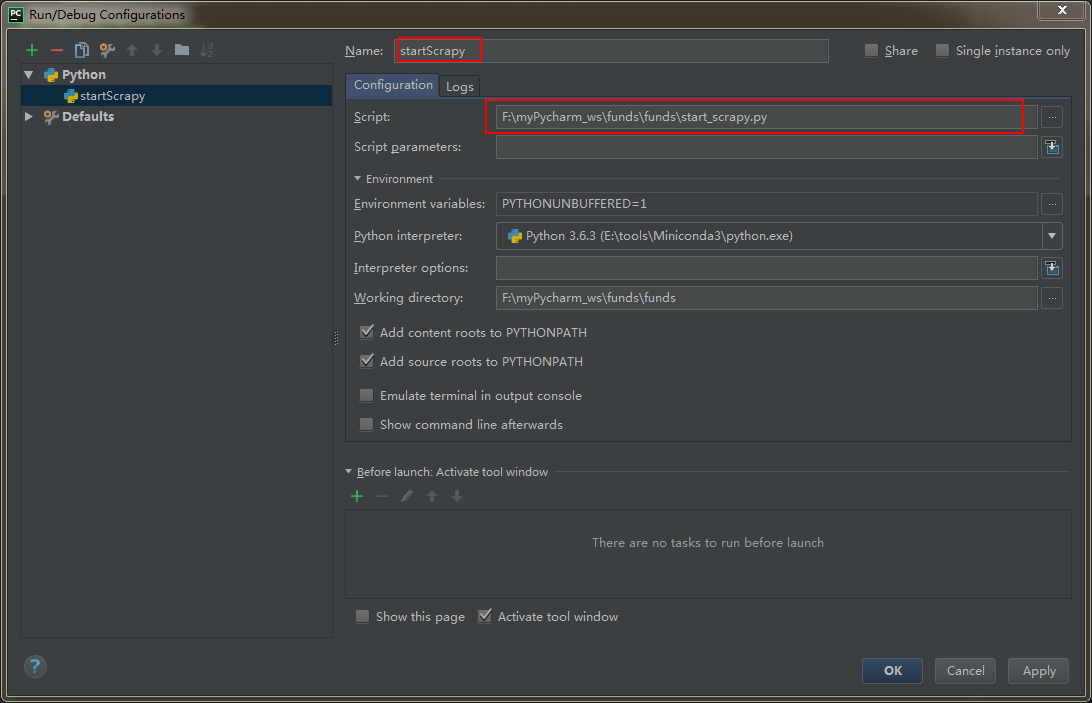
运行方式:直接运行该.py文件即可。
分析如何获取数据
编写代码
step 1:设置item
class FundsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field() # 基金代码
name = scrapy.Field() # 基金名称
unitNetWorth = scrapy.Field() # 单位净值
day = scrapy.Field() # 日期
dayOfGrowth = scrapy.Field() # 日增长率
recent1Week = scrapy.Field() # 最近一周
recent1Month = scrapy.Field() # 最近一月
recent3Month = scrapy.Field() # 最近三月
recent6Month = scrapy.Field() # 最近六月
recent1Year = scrapy.Field() # 最近一年
recent2Year = scrapy.Field() # 最近二年
recent3Year = scrapy.Field() # 最近三年
fromThisYear = scrapy.Field() # 今年以来
fromBuild = scrapy.Field() # 成立以来
serviceCharge = scrapy.Field() # 手续费
upEnoughAmount = scrapy.Field() # 起够金额
pass
step 2:编写spider
import scrapy
import json
from scrapy.http import Request
from funds.items import FundsItem
class FundsSpider(scrapy.Spider):
name = 'fundsList' # 唯一,用于区别Spider。运行爬虫时,就要使用该名字
allowed_domains = ['fund.eastmoney.com'] # 允许访问的域
# 初始url。在爬取从start_urls自动开始后,服务器返回的响应会自动传递给parse(self, response)方法。
# 说明:该url可直接获取到所有基金的相关数据
# start_url = ['http://fundact.eastmoney.com/banner/pg.html#ln']
# custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的scrapy工程里有多个spider的时候这个custom_setting就显得很有用了
# custome_setting = {
#
# }
# spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request 。
# 重写start_requests也就不会从start_urls generate Requests了
def start_requests(self):
url = 'https://fundapi.eastmoney.com/fundtradenew.aspx?ft=pg&sc=1n&st=desc&pi=1&pn=3000&cp=&ct=&cd=&ms=&fr=&plevel=&fst=&ftype=&fr1=&fl=0&isab='
requests = []
request = scrapy.Request(url,callback=self.parse_funds_list)
requests.append(request)
return requests
def parse_funds_list(self,response):
datas = response.body.decode('UTF-8')
# 取出json部门
datas = datas[datas.find('{'):datas.find('}')+1] # 从出现第一个{开始,取到}
# 给json各字段名添加双引号
datas = datas.replace('datas', '\"datas\"')
datas = datas.replace('allRecords', '\"allRecords\"')
datas = datas.replace('pageIndex', '\"pageIndex\"')
datas = datas.replace('pageNum', '\"pageNum\"')
datas = datas.replace('allPages', '\"allPages\"')
jsonBody = json.loads(datas)
jsonDatas = jsonBody['datas']
fundsItems = []
for data in jsonDatas:
fundsItem = FundsItem()
fundsArray = data.split('|')
fundsItem['code'] = fundsArray[0]
fundsItem['name'] = fundsArray[1]
fundsItem['day'] = fundsArray[3]
fundsItem['unitNetWorth'] = fundsArray[4]
fundsItem['dayOfGrowth'] = fundsArray[5]
fundsItem['recent1Week'] = fundsArray[6]
fundsItem['recent1Month'] = fundsArray[7]
fundsItem['recent3Month'] = fundsArray[8]
fundsItem['recent6Month'] = fundsArray[9]
fundsItem['recent1Year'] = fundsArray[10]
fundsItem['recent2Year'] = fundsArray[11]
fundsItem['recent3Year'] = fundsArray[12]
fundsItem['fromThisYear'] = fundsArray[13]
fundsItem['fromBuild'] = fundsArray[14]
fundsItem['serviceCharge'] = fundsArray[18]
fundsItem['upEnoughAmount'] = fundsArray[24]
fundsItems.append(fundsItem)
return fundsItems
step 3:配置settings.py
custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的scrapy工程里有多个spider的时候这个custom_setting就显得很有用了。
但是我目前项目暂时只有一个爬虫,所以暂时使用setting.py设置spider。
设置了DEFAULT_REQUEST_HEADERS(本次爬虫由于是请求接口,该项不配置也可)
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'st_pvi=72856792768813; UM_distinctid=1604442b00777b-07f0a512f81594-5e183017-100200-1604442b008b52; qgqp_b_id=f10107e9d27d5fe2099a361a52fcb296; st_si=08923516920112; ASP.NET_SessionId=s3mypeza3w34uq2zsnxl5azj',
'Host':'fundapi.eastmoney.com',
'Referer':'http://fundact.eastmoney.com/banner/pg.html',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
设置ITEM_PIPELINES
ITEM_PIPELINES = {
'funds.pipelines.FundsPipeline': 300,
}
pipelines.py,将数据写入我本地数据库里
import pymysql.cursors
class FundsPipeline(object):
def process_item(self, item, spider):
# 连接数据库
connection = pymysql.connect(host='localhost',
user='root',
password='123',
db='test',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
sql = "INSERT INTO funds(code,name,unitNetWorth,day,dayOfGrowth,recent1Week,recent1Month,recent3Month,recent6Month,recent1Year,recent2Year,recent3Year,fromThisYear,fromBuild,serviceCharge,upEnoughAmount)\
VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (
item['code'], item['name'], item['unitNetWorth'], item['day'], item['dayOfGrowth'], item['recent1Week'], \
item['recent1Month'], item['recent3Month'], item['recent6Month'], item['recent1Year'], item['recent2Year'],
item['recent3Year'], item['fromThisYear'], item['fromBuild'], item['serviceCharge'], item['upEnoughAmount'])
with connection.cursor() as cursor:
cursor.execute(sql) # 执行sql
connection.commit() # 提交到数据库执行
connection.close()
return item
错误处理
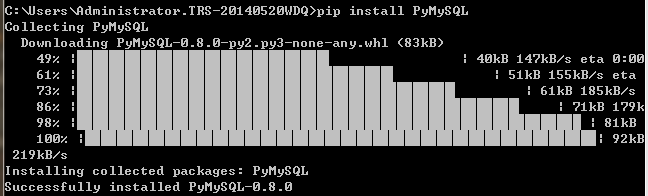
ModuleNotFoundError: No module named 'pymysql'
pip install PyMySQL
1366, "Incorrect string value: '\xE6\x99\xAF\xE9\xA1\xBA...' for column 'name' at row 1"
即:入库的中文是乱码
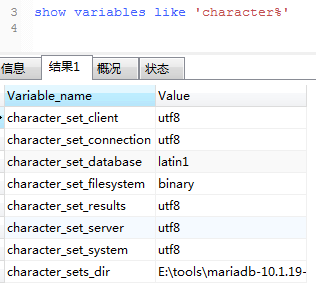
查看数据库编码,为latin1。
解决办法:
alter table funds convert to character set utf8














 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









