






原标题:如何将网页中的音频文件提取出来
上网的时候大家经常会在网页上看到一些充满魔性的音乐,也总是忍不住的想要下载分享给身边的朋友们,然而也都会遇到这样的一个问题,那就是无法下载,没有版权,所以说这个时候我们只能想办法去将网页上的音乐提取出来,想了很久,发现了一款比较适合我们大众的工具,是什么工具呢?这是一款新人都可以使用的的哦!操作比较简单,希望你们看完这篇文章之后会有所收获哦!

工具特色:
工具这么多,大家不妨试试它,迅捷音频转换器它是一款多功能的音频编辑处理软件,软件具有音频剪切、音频提取、音频合并和音频转换这四个功能,支持单个文件操作,还支持文件批量操作!的确是个不错的选择。
音频转换器https://www.xunjieshipin.com/download-audioedit
第一步:打开工具
将网页中的音乐准备好,接着将工具打开到界面,可以先试着简单的了解一下。
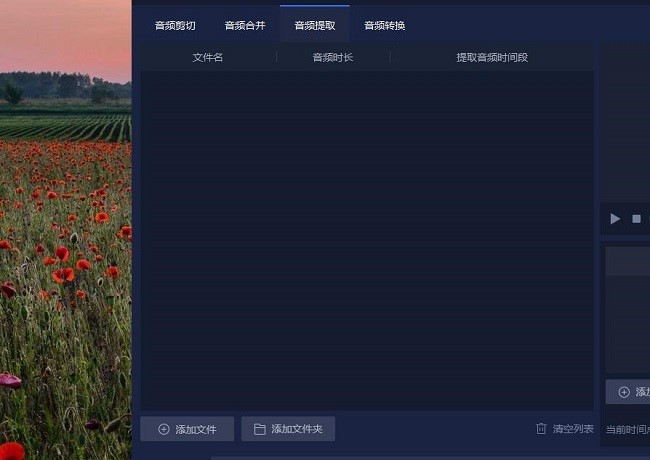
第二步:添加音频文件
今天是提取音乐,所以大家找到音频提取按钮,点击会出现它的界面,它的界面中有添加文件和添加文件夹这两个,大家可以更具自己的文件数量来进行添加就可以了。
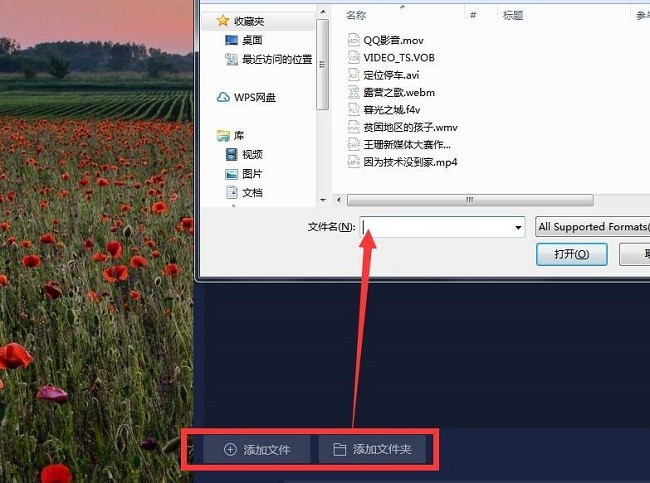
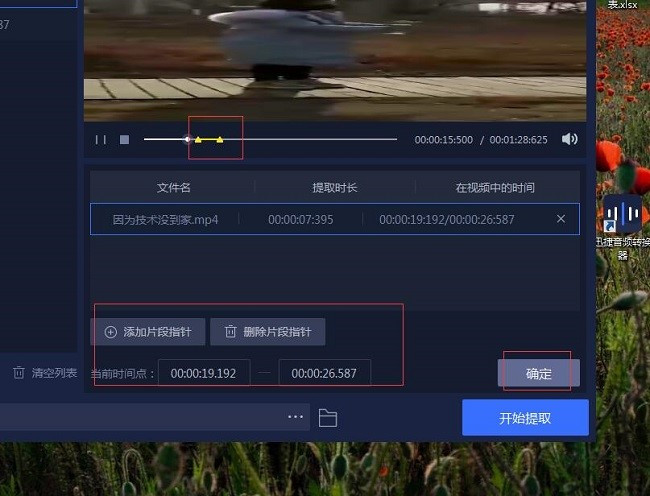
第三步:添加删除片段指南
接着,就是要准备提取音乐片段了,我们看到右边的编辑栏,其中添加片段指南就是你所提取的音乐片段,而删除片段指南,就是简单的删除你不需要的音乐片段,可以拉动上当的进度条进行提取,最后点击确定即可。
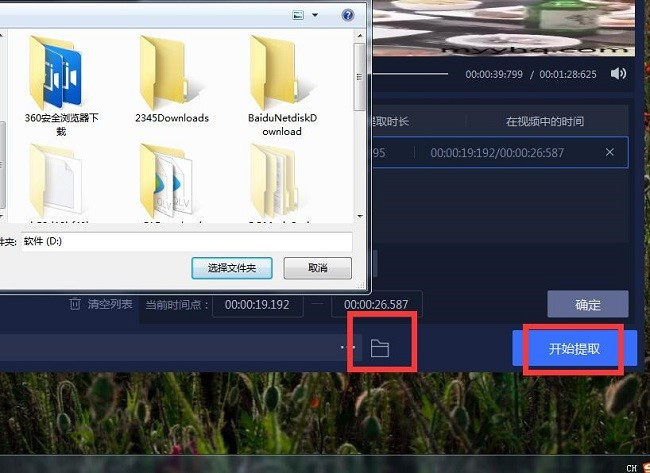
第四步:设置提取音频保存位置
不要以为点击完确定就饿可以了,我们在选择输出格式中设置一下文件的保存位置,然后再点击开始提取按钮。
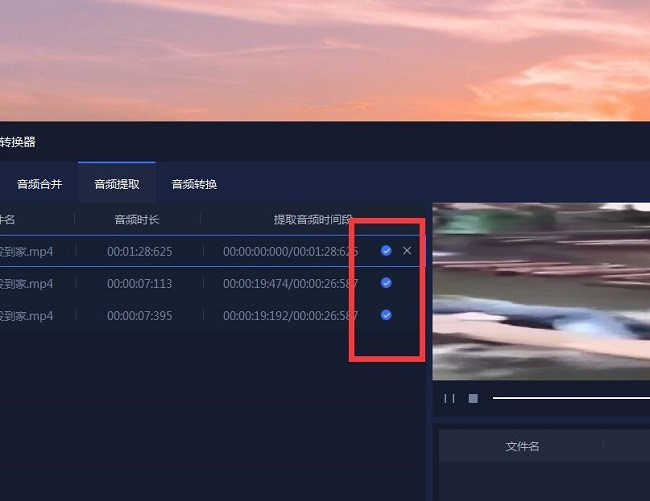
第五步提取成功
点击完后,提取是需要时间的,但是这个时间是非常的快,只要大家看到了对号就已经说明提取成功了,然后如果你们想看的话在自己设置的文件中就可以查看了。
说的再多看得再明白都不如大家亲自动手去操作,最后感谢你们的阅读,希望可以有效的帮助到你们。返回搜狐,查看更多
责任编辑:














 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









