





六、 MySQL 查询数据
1 MySQL 的基本查询
1.1 MySQL 的列选择
SELECT*| 投影列 FROM 表名
1.1.1示例
查询 departments 表中的所有数据 select*from departments;
1.2 MySQL 的行选择
SELECT*| 投影列 FROM 表名 WHERE 选择条件
1.2.1示例
查询 departments 表中部门 ID 为 4 的部门名称与工作地点 ID。 select department_name,location_id from departments where department_id =4;
1.3 SELECT 语句中的算术表达式
+ :加法运算 - :减法运算 * :乘法运算 / :除法运算,返回商 % :求余运算,返回余数
1.3.1示例一
修改 employees 表添加 salary。 alter table employees add column salary float(9,2);
1.3.2示例二
查询雇员的年薪。 select employees_id,last_name,email,12*salary from employees;
1.3.3示例三
计算 employees 表中的员工全年薪水加 100 以后的薪水是多少? select employees_id , last_name,email,12*salary+100 from employees;
1.4 MySQL 中定义空值
包含空值的算术表达式计算结果为空。
1.4.1示例
在 employees 中添加 commission_pct,计算年薪包含佣金。 alter table employees add column commission_pct float(5,2); select12*salary*commission_pct from employees;
1.5 MySQL 中的列别名
SELECT 列名 AS 列别名 FROM 表名 WHERE 条件
1.5.1示例
查询 employees 表将雇员 laser_name 列名改为 name。 select last_name as name from employees;
1.6 MySQL 中的连字符
MySQL中并不支持||作为连字符,需要使用concat函数。在参数数量上与oracle的concat 函数有区别。
1.6.1示例
查询雇员表中的所有数据,将所有数据连接到一起,每列值中通过#分割。 select concat(employees_id,'#',last_name,'#',email,"#",salary,"#",commission_pct) from employees;
1.7 MySQL 中去除重复
在 SELECT 语句中用 DISTINCT 关键字除去相同的行。
1.7.1示例
查询 employees 表,显示唯一的部门 ID。 select distinct dept_id from employees;
2 约束和排序数据
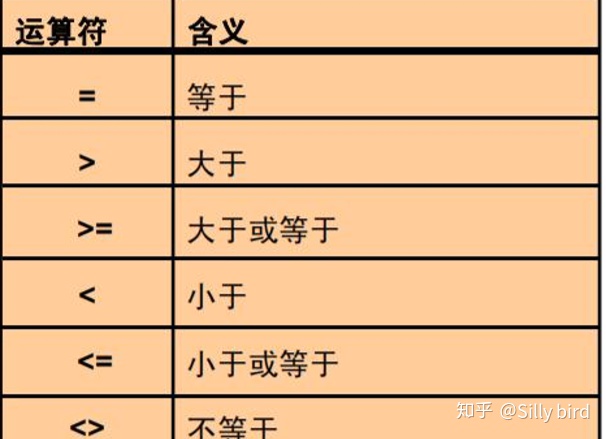
2.1 MySQL 中的比较条件
2.1.1比较运算符
• 等于= • 大于> • 大于等于>= • 小于< • 小于等于<= • 不等于!=或<>
2.1.1.1 示例一 查询 employees 表,员工薪水大于等于 3000 的员工的姓名与薪水。 select*from employees where salary>=3000;
2.1.1.2 示例二 查询 employees 表,员工薪水不等于 5000 的员工的姓名与薪水。 select*from employees where salary<>5000;
2.1.2模糊查询
•like •%表示任意多个任意字符 •_表示一个任意字符
2.1.2.1 示例 查询 employees 中雇员名字第二个字母是 e 的雇员信息。 select*from employees where last_name like'_e%'
2.1.3逻辑运算符
•and •or •not
2.1.3.1 示例一 查询 employees 表中雇员薪水是 5000 的并且名字中含有 d 的雇员信息 select*from employees where salary=5000 and last_name like'%e%'
2.1.3.2 示例二 查询 employees 表中雇员名字中不包含 u 的雇员信息
select*from employees where last_name not like'%u%'
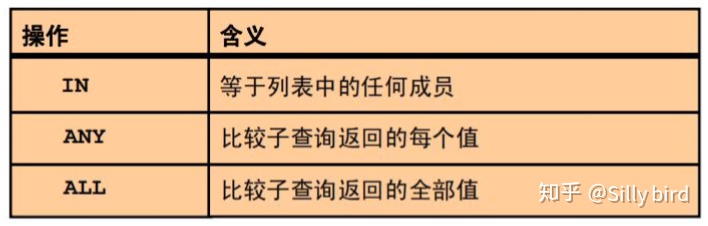
2.1.4范围查询
•between...and •in 表示在一个非连续的范围内
2.1.4.1 示例一 查询 employees 表,薪水在 3000-8000 之间的雇员信息
select*from employees where salary between 3000 and 8000
2.1.4.2 示例二 查询 employees 表,找出薪水是 5000,6000,8000 的雇员信息
select*from employees where salary in(5000,6000,8000)
2.1.5空值判断
• 判断空 is null • 判断非空 is not null
2.1.5.1 示例一 找出 emloyees 表中那些没有佣金的雇员
select*from employees where commission_pct is null;
2.1.5.2 示例二 找出 employees 表中那些有佣金的雇员
select*from employees where commission_pct is not null;
2.2使用 ORDER BY 排序
• 用 ORDER BY 子句排序 •ASC: 升序排序,默认 •DESC: 降序排序
2.2.1.1 示例一 查询 employees 表中的所有雇员,薪水按升序排序。
select*from employees order by salary
2.2.1.2 示例二 查询 employees 表中的所有雇员,雇员名字按降序排序。
select*from employees order by last_name desc
3 MySQL 中常见的单行函数
3.1大小写控制函数
LOWER(str) 转换大小写混合的字符串为小写字符串 UPPER(str) 转换大小写混合的字符串为大写字符串。
3.2字符处理
CONCAT(str1,str2,...) 将 str1、str2 等字符串连接起来
SUBSTR(str,pos,len) 从 str 的第 pos 位(范围:1~str.length)开始,截取长度为 len 的字符串 LENGTH(str) 获取 str 的长度
INSTR(str,substr) 获取 substr 在 str 中的位置
TRIM(str) 从 str 中删除开头和结尾的空格(不会处理字符串中间含有的空格)
LTRIM(str) 从 str 中删除左侧开头的空格 RTRIM(str) 从 str 中删除右侧结尾的空格 REPLACE(str,from_str,to_str) 将 str 中的 from_str 替换为 to_str(会替换掉所有符合 from_str 的字符串)
3.3数字函数
ROUND(arg1,arg2):四舍五入指定小数的值。 ROUND(arg1):四舍五入保留整数。 TRUNC(arg1,arg2):截断指定小数的值,不做四舍五入处理。 MOD(arg1,arg2):取余。
3.4日期函数
SYSDATE() 或者 NOW() 返回当前系统时间,格式为 YYYY-MM-DDhh-mm-ss CURDATE() 返回系统当前日期,不返回时间
CURTIME() 返回当前系统中的时间,不返回日期
DAYOFMONTH(date) 计算日期 d 是本月的第几天
DAYOFWEEK(date) 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 DAYOFYEAR(date) 返回指定年份的天数
DAYNAME(date) 返回 date 日期是星期几
LAST_DAY(date) 返回 date 日期当月的最后一天
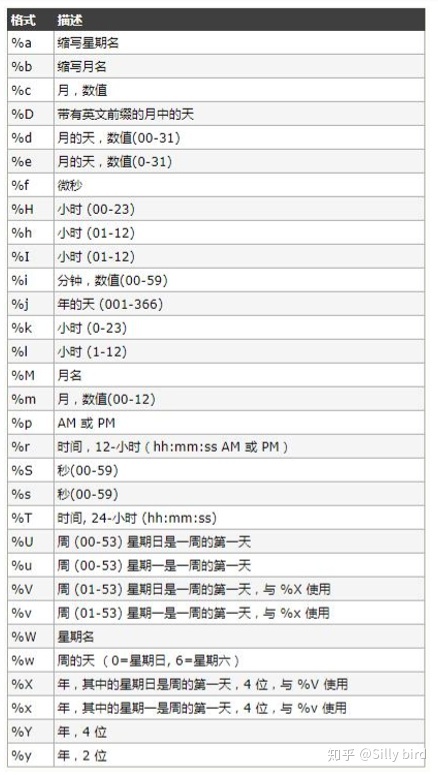
3.5转换函数
DATE_FORMAT(date,format) 将日期转换成字符串(类似 oracle 中的 to_char())
STR_TO_DATE(str,format) 将字符串转换成日期(类似 oracle 中的 to_date())
3.6示例一
向 employees 表中添加 hire_date 列 类型为 date 类型
alter table employees add column hire_datedate
3.7示例二
向 employees 表中添加一条数据,名字:King ,email:king@sx.cn,部门 ID:1,
薪水:9000,入职时间:2018 年 5 月 1 日,佣金:0.6 insert into employees values(default,'King','king@sx.cn',1,9000,0.6,STR_TO_DATE('2018 年 5 月 1 日','%Y 年%m 月%d 日'))
3.8示例三
查询 employees 表中雇员名字为 King 的雇员的入职日期,要求显示格式为 yyyy 年 MM 月 dd 日。 select DATE_FORMAT(hire_date,'%Y 年%m 月%d 日') from employees where last_name = 'King'
3.9通用函数
IFNULL(expr1,expr2) 判断 expr1 是否为 null,如果为 null,则用 expr2 来代替 null (类似 oracle 的 NVL()函数)
NULLIF(expr1,expr2) 判断 expr1 和 expr2 是否相等,如果相等则返回 null,如果不 相等则返回 expr1 IF(expr1,expr2,expr3) 判断 expr1 是否为真(是否不为 null),如果为真,则使用 expr2 替代 expr1;如果为假,则使用 expr3 替代 expr1(类似 oracle 的 NVL2()函数)
COALESCE(value,...) 判断 value 的值是否为 null,如果不为 null,则返回 value;如 果为 null,则判断下一个 value 是否为 null……直至出现不为 null 的 value 并返回或者返回最 后一个为 null 的 value CASE WHEN THEN ELSE END 条件函数
4 多表连接查询
4.1等值连接
4.1.1示例
查询雇员 King 所在的部门名称 select d.department_name from employees e,departments d where e.dept_id = d.department_id and e.last_name='King'
4.2非等值连接
4.2.1示例一
创建 sal_level 表,包含 lowest_sal,highest_sal,level。
create table sal_level(lowest_salint,highest_salint,levelvarchar(30))
4.2.2示例二
插入数据 1000 2999 A 2000 4999 B 5000 7999 C 8000 12000 D
insert into sal_level values(8000,12000,'D)
4.2.3示例三
查询所有雇员的薪水级别。
select e.last_name,s.level from employees e ,sal_level s where e.salary between s.lowest_sal and highest_sal;
4.3自连接
4.3.1示例一
修改 employees 表,添加 manager_id 列
ALTER table employees add COLUMN manager_id int
4.3.2示例二
修改数据 Oldlu 是 kevin 与 King 的经理 Taylor 是 Fox 的经理
4.3.3示例三
查询每个雇员的经理的名字以及雇员的名字。
select emp.last_name,man.last_name from employees emp ,employees man where emp.manager_id=man.employees_id
5 外连接(OUTER JOIN)
5.1左外连接(LEFT OUTER JOIN)
5.1.1示例一
向 employees 表中添加一条数据,名字:Lee,email:lee@sxt.cn,入职时间为今天。他 没有薪水,没有经理,没有佣金。
insert into employees(last_name,email,hire_date)values('Lee','lee@sxt.cn',SYSDATE())
5.1.2示例二
查询所有雇员的名字以及他们的部门名称,包含那些没有部门的雇员。 select e.last_name,d.department_name from employees e LEFT OUTER JOIN departments d one.dept_id=d.department_id
5.2右外连接(RIGHT OUTER JOIN)
5.2.1示例一
向 departments 表中添加一条数据,部门名称为 Testing,工作地点 ID 为 5。
insert into departments values(default,'Testing',5)
5.2.2示例二
查询所有雇员的名字以及他们的部门名称,包含那些没有雇员的部门。
select e.last_name,d.department_name from employees e right OUTER join departments d on e.dept_id=d.department_id;
5.3全外链接
注意:MySQL 中不支持 FULL OUTER JOIN 连接 可以使用 union 实现全完连接。
5.3.1 UNION
可以将两个查询结果集合并,返回的行都是唯一的,如同对整个结果集合使用了 DISTINCT。
5.3.2 UNION ALL
只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据, 那么返回的结果集就会包含重复的数据了。
5.3.3语法结构
SELECT 投影列 FROM 表名 LEFT OUTER JOIN 表名 ON 连接条件 UNION SELECT 投影列 FROM 表名 RIGHT OUTER JOIN 表名 ON 连接条件
5.3.3.1 示例
查询所有雇员的名字以及他们的部门名称,包含那些没有雇员的部门以及没有部门的雇
员。
(select e.last_name,d.department_name from employees e LEFT OUTER JOIN departments
d on e.dept_id = d.department_id) UNION (select e1.last_name,d1.department_name from employees e1 RIGHT OUTER JOIN departments d1 on d1.department_id = e1.dept_id)
6 SQL 99 标准中的查询
MySQL 5.7 支持 SQL99 标准。
6.1SQL99 中的交叉连接(CROSS JOIN)
6.1.1示例
使用交叉连接查询 employees 表与 departments 表
select* from employees cross join departments
6.2SQL99 中的自然连接(NATURAL JOIN)
6.2.1示例一
修改 employees 表中的 dept_id 列将该列的名称修改为
department_id alter table employees change columndept_id department_id int
6.2.2示例二
使用自然连接查询所有有部门的雇员的名字以及部门名称。
select e.last_name,d.department_name from employees e natural join departments d
6.3SQL99 中的内连接(INNER JOIN)
6.3.1示例
查询雇员名字为 OldLu 的雇员 ID,薪水与部门名称。 select e.employees_id,e.salary,d.department_name from employees e inner JOIN departments done.department_id=d.department_idwheree.last_name ='Oldlu';
7 聚合函数
7.1AVG(arg)函数
对分组数据做平均值运算。 arg:参数类型只能是数字类型。
7.2SUM(arg)函数
对分组数据求和。 arg:参数类型只能是数字类型。
7.3MIN(arg)函数
求分组中最小数据。 arg:参数类型可以是字符、数字、日期。
7.4MAX(arg)函数
求分组中最大数据。 arg:参数类型可以是字符、数字、日期。
7.5COUNT 函数
返回一个表中的行数。
COUNT 函数有三种格式: •COUNT(*) •COUNT(expr) •COUNT(DISTINCTexpr)
8 数据组(GROUPBY)
8.1创建数据组
8.1.1示例
计算每个部门的平均薪水 selectavg(e.salary)fromemployeesegroupbye.department_id
8.2约束分组结果(HAVING)
显示那些最高薪水大于 5000 的部门的部门号和最高薪水。 select e.department_id,max(e.salary) from employees e group by e.department_id HAVING MAX(e.salary)>5000
9 子查询
可以将子查询放在许多的 SQL 子句中,包括: • WHERE 子句
• HAVING 子句 • FROM 子句
9.1使用子查询的原则
• 子查询放在圆括号中。 • 将子查询放在比较条件的右边。 • 在单行子查询中用单行运算符,在多行子查询中用多行运算符。
9.1.1示例
谁的薪水比 Oldlu 高 select em.last_name,em.salary from employees em where em.salary > (select e.salary from employeesewheree.last_name ='Oldlu')
9.2单行子查询
9.2.1示例
查询 Oldlu 的同事,但是不包含他自己。 select empl.last_name from employees empl where empl.department_id = (select e.department_idfromemployeesewheree.last_name ='Oldlu')andempl.last_name<>'Oldlu'
9.3多行子查询
示例 查找各部门收入为部门最低的那些雇员。显示他们的名字,薪水以及部门 ID。 select em.last_name,em.salary,em.department_id from employees em where em.salary in(selectmin(e.salary)fromemployeesegroup bye.department_id)
10 MySQL 中的正则表达式
• MySQL 中允许使用正则表达式定义字符串的搜索条件,性能要高于 like。 • MySQL 中的正则表达式可以对整数类型或者字符类型检索。 • 使用 REGEXP 关键字表示正则匹配。 • 默认忽略大小写,如果要区分大小写,使用 BINARY关键字
10.1正则表达式的模式及其含义
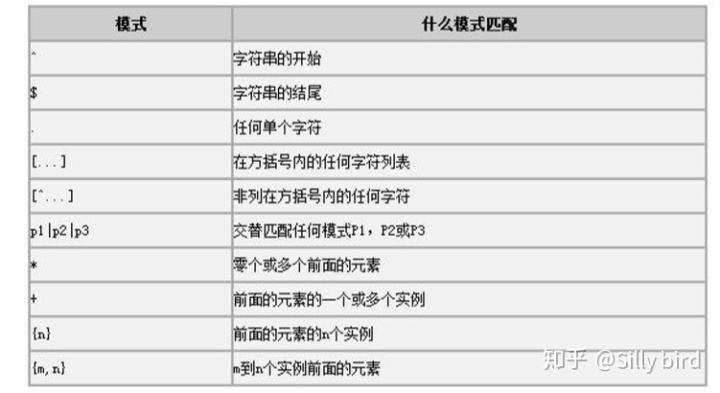
10.2“^”符号
^在正则表达式中表示开始
10.2.1 语法
查询以 x 开头的数据(忽略大小写) SELECT 列名 FROM 表名 WHERE 列名 REGEXP'^x';
10.2.2 示例
查询雇员表中名字是以 k 开头的雇员名字与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXPbinary'^K'
10.3“$”符号
10.3.1 语法
查询以 x 结尾的数据(忽略大小写) SELECT 列名 FROM 表名 WHERE 列名 REGEXP'x$';
10.3.2 示例
查询雇员表中名字是以 n 结尾的雇员名字与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXPbinary'n$'
10.4“.”符号
10.4.1 语法
英文的点,它匹配任何一个字符,包括回车、换行等。 SELECT 列名 FROM 表名 WHERE 列名 REGEXP'x.';
10.4.2 示例
查询雇员表中名字含有 o 的雇员的姓名与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'o.'
10.5“*”符号
10.5.1 语法
“*”:星号匹配 0 个或多个字符,在它之前必须有内容。
10.6“+”符号
10.6.1 语法
"+":加号匹配 1 个或多个字符,在它之前也必须有内容。 SELECT 列名 FROM 表名 WHERE 列名 REGEXP'x+';-匹配大于 1 个的任意字符
10.7“?”符号
10.7.1 语法
“?”:问号匹配 0 次或 1 次。 SELECT 列名 FROM 表名 WHERE 列名 REGEXP'x?';-匹配 0 个或 1 个字符
10.8“|”符号
10.8.1 语法
“|”:表示或者含义 SELECT 列名 FROM 表名 WHERE 列名 REGEXP'abc|bcd';-匹配包含 abc 或 bcd
10.8.2 示例
查询雇员表中名字含有 ke 或者 lu 的雇员的名字与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'ke|lu'
10.9“[a-z]”
10.9.1 语法
“[a-z]”:字符范围 “^[....]”:以什么字符开头的 “[^....]”:匹配不包含在[]的字符 SELECT 列名 FROM 表名 WHERE 列名 REGEXP'[a-z]';-匹配内容包含a-z范围的数
据
10.9.2 示例一
查询雇员表中名字包含 x、y、z 字符的雇员的名字和薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'[x-z]'
10.9.3 示例二
查询雇员名字是 t、f 开头的雇员名字与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'^[t|f]'
10.9.4 示例三
查询雇员的名字与薪水,不包含 oldlu。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'[^oldlu]'
10.10 “{n}”
10.10.1 语法
“{n}”:固定次数。 select*fromstudentwherenameREGEXP's{2}';--匹配以 s 连续出现 2 次的所有数据
10.10.2 示例一
查询雇员名字含有连续两个 e 的雇员的姓名与薪水 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'e{2}'
10.10.3 示例二
查询名字中含有两个 o 的雇员的名字与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'o.{2}'
10.11 “{n,m}”
10.11.1语法
“{n,m}”:范围次数。 select * from student where name REGEXP'^s{2,5}';--匹配以 s 开头且重复 2 到 5 次的所 有数据
10.11.2示例
查询雇员名字中包含 1 个或者两个 o 的雇员姓名与薪水。 selectlast_name,salaryfromemployeeswherelast_nameREGEXP'o.{1,2}'
七、 MySQL 中的其他对象
1 索引
MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
1.1MySQL 中的索引类型
• 普通索引 • 唯一索引 • 主键索引 • 组合索引 • 全文索引
1.2普通索引
是最基本的索引,它没有任何限制。 在创建索引时,可以指定索引长度。length 为可选参数,表示索引的长度,只有字符串 类型的字段才能指定索引长度,如果是 BLOB 和 TEXT 类型,必须指定 length。 创建索引时需要注意: 如果指定单列索引长度,length 必须小于这个字段所允许的最大字符个数。
查询索引:SHOWINDEXFROMtable_name
1.2.1直接创建索引
CREATEINDEXindex_name ONtable(column(length))
1.2.1.1 示例 为 emp3 表中的 name 创建一个索引,索引名为 emp3_name_index createindexemp3_name_indexONemp3(name)
1.2.2修改表添加索引
ALTERTABLEtable_nameADDINDEX index_name(column(length))
1.2.2.1 示例 修改 emp3 表,为 addrees 列添加索引,索引名为 emp3_address_index altertableemp3addindexemp3_address_index(address)
1.2.3创建表时指定索引列
CREATETABLE`table`( COLUMNTYPE, PRIMARYKEY(`id`), INDEXindex_name(column(length)) )
1.2.3.1 示例 创建 emp4 表,包含 emp_id,name,address 列,同时为 name 列创建索引。索引名为 emp4_name_index create table emp4(emp_id int primary key auto_increment,name varchar(30),address varchar(50),indexemp4_name_index(name))
1.2.4删除索引
DROPINDEXindex_nameONtable
1.2.4.1 示例 删除 mep3 表中索引名为 emp3_address_index 的索引 dropindexemp3_address_indexonemp3
1.3唯一索引
唯一索引与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。它有以 下几种创建方式:
1.3.1创建唯一索引
CREATEUNIQUE INDEXindexName ONtable(column(length))
1.3.1.1 示例 为 emp 表中的 name 创建一个唯一索引,索引名为 emp_name_index createuniqueindexemp_name_indexonemp(name)
1.3.2修改表添加唯一索引
ALTERTABLEtable_nameADDUNIQUE indexName(column(length))
1.3.2.1 示例 修改 emp 表,为 salary 列添加唯一索引,索引名为 emp_salary_index
altertableemp adduniqueemp_salary_index(salary)
1.3.3创建表时指定唯一索引
CREATETABLE`table`( COLUMNTYPE, PRIMARYKEY(`id`), UNIQUEindex_name (column(length)) )
1.3.3.1 示例 创建 emp5 表,包含 emp_id,name,address 列,同时为 name 列创建唯一索引。索引名为 emp5_name_index create table emp5(emp_id int primary key ,name varchar(30),address varchar(30),unique emp5_name_index(name))
1.4主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建 表的时候同时创建主键索引。
1.4.1修改表添加主键索引
ALTERTABLE 表名 ADDPRIMARYKEY(列名)
1.4.1.1 示例 修改 emp 表为 employee_id 添加主键索引 altertableemp addprimary key(employee_id)
1.4.2创建表时指定主键索引
CREATETABLE`table`( COLUMNTYPE, PRIMARYKEY(column) )
1.4.2.1 示例 创建 emp6 表,包含 emp_id,name,address 列,同时为 emp_id 列创建主键索引 create table emp6(employee_id int primary key auto_increment,name varchar(20),address varchar(50))
1.5组合索引
组合索引是指使用多个字段创建的索引,只有在查询条件中使用了创建索引时的第一个 字段,索引才会被使用(最左前缀原则)。
1.5.1最左前缀原则
就是最左优先。 如:我们使用表中的 name,address,salary 创建组合索引,那么想要组合索引生效, 我们只能使用如下组合: name/address/salary name/address name/ 如果使用 addrees/salary 或者是 salary 则索引不会生效。
1.5.2修改添加组合索引
ALTERTABLEtable_nameADDINDEX index_name(column(length),column(length))
1.5.2.1 示例 修改 emp6 表,为 name,address 列创建组合索引 altertableemp6addindexemp6_index_n_a(name,address)
1.5.3创建表时创建组合索引
CREATETABLE`table`( COLUMNTYPE, INDEXindex_name(column(length),column(length)) )
1.5.3.1 示例 创建 emp7 表,包含 emp_id,name,address 列,同时为 name,address 列创建组合索引。 create table emp7(emp_id int primary key auto_increment ,name varchar(20),address varchar(30),indexemp7_index_n_a(name,address))
1.6全文索引
全文索引(FULLTEXTINDEX)主要用来查找文本中的关键字,而不是直接与索引中的值 相比较。 FULLTEXT 索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的 where 语句的参数匹配。FULLTEXT 索引配合 match against 操作使用,而不是一般的 where 语句 加 like。
全文索引可以从 CHAR、VARCHAR 或 TEXT 列中作为 CREATETABLE 语句的一部分 被创建,或是随后使用 ALTERTABLE 添加。不过切记对于大容量的数据表,生成全文索 引是一个非常消耗时间非常消耗硬盘空间的做法。
1.6.1修改添加全文索引
ALTERTABLEtable_nameADDFULLTEXTindex_content(content)
1.6.1.1 示例一 修改 emp7 表添加 content 列类型为 TEXT altertableemp7addCOLUMN contenttext;
1.6.1.2 示例二 修改 emp7 表,为 content 列创建全文索引 altertableemp7addfulltextemp7_content_fullindex(content)
1.6.2创建表时创建全文索引
CREATETABLE`table`( COLUMNTYPE, FULLTEXTindex_name (column) )
1.6.2.1 示例 创建 emp8 表包含 emp_id 列,content 列该列类型为 text,并为该列添加名为 emp8_content_fulltext 的全文索引 create table emp8(emp_id int primary key auto_increment,content text,fulltext emp8_content_fullindex(content))
1.6.3删除全文索引
DROPINDEXindex_nameONtable ALTERTABLEtable_nameDROPINDEXindex_name
1.6.3.1 示例 删除 emp8 表中名为 emp8_content_full 的索引。 dropindexemp8_content_fullindexonemp8
1.7使用全文索引
全 文 索 引 的 使 用 与 其 他 索 引 不 同 。 在 查 询 语 句 中 需 要 使 用 match(column) against(‘content’) 来检索数据。
1.7.1全文解析器
全文索引中基本单位是”词”。分词,全文索引是以词为基础的,MySQL 默认的分词是 所有非字母和数字的特殊符号都是分词符。在检索数据时我们给定的检索条件也是词。 MySQL 中默认的全文解析器不支持中文分词。如果数据含有中文需要更换全文解析器 NGRAM。
1.7.2使用全文索引
SELECT 投影列 FROM 表名 WHEREMATCH(全文索引列名)AGAINST(‘搜索内容’)
1.7.2.1 示例一 修改 emp8 表,为 content 列创建名为 emp8_content_full 的全文索引 altertableemp8addfulltextemp8_content_full(content)
1.7.2.2 示例二 向 emp8 表中插入一条数据 content 的值为”hello,bjsxt” insertintoemp8values(default,'hellobjsxt')
1.7.2.3 示例三 查询 emp8 表中内容包含 bjsxt 的数据。 select*fromemp8 wherematch(content)AGAINST('bjsxt')
1.7.3更换全文解析器
在创建全文索引时可以指定 ngram 解析器 ALTER TABLE table_name ADD FULLTEXT index_content(content) WITH PARSER NGRAM
1.7.3.1 示例一 删除 emp8 表中的 emp8_content_full 全文索引 dropindexemp8_content_fullonemp8
1.7.3.2 示例二 修改 emp8 表,为 content 列添加名称为 emp8_content_full 的全文索引,并指定 ngram 全文解析器。 altertableemp8addfulltextemp8_content_full(content)withparserngram
1.7.3.3 示例三 向 emp8 表中添加一条数据 content 值为”你好,北京尚学堂” insertintoemp8values(default,'你好,北京尚学堂')
1.7.3.4 示例四 查询 emp8 表中内容包含”北京尚学堂”的数据 select*fromemp8 wherematch(content)AGAINST('北京尚学堂')
2 MySQL 中的用户管理
MySQL 是一个多用户的数据库系统,按权限,用户可以分为两种:root 用户,超级管 理员,和由 root 用户创建的普通用户。
2.1MySQL 创建用户
CREATEUSERusernameIDENTIFIEDBY'password';
2.2查看用户
SELECTUSER,NOSTFROMUSER(该表位于 mysql 库中)
2.2.1示例
创建一个 u_sxt 的用户,并查看创建是否成功。 selectuser,hostfrommysql.user createuseru_sxtIDENTIFIEDby'sxt'
2.3分配权限
新用户创建完后是无法登陆的,需要分配权限。 GRANT 权限 ON 数据库.表 TO 用户名@登录主机 IDENTIFIEDBY"密码" GRANTALLPRIVILEGESON*.*TO'username'@'localhost'IDENTIFIEDBY'password' 登陆主机: % 匹配所有主机 localhost localhost 不会被解析成 IP 地址,直接通过 UNIXsocket 连接 127.0.0.1 会通过 TCP/IP 协议连接,并且只能在本机访问; ::1 ::1 就是兼容支持 ipv6 的,表示同 ipv4 的 127.0.0.1
2.3.1权限列表
ALTER: 修改表和索引。 CREATE: 创建数据库和表。 DELETE: 删除表中已有的记录。 DROP: 删除数据库和表。 INDEX: 创建或删除索引。 INSERT: 向表中插入新行。 SELECT: 检索表中的记录。 UPDATE: 修改现存表记录。
FILE: 读或写服务器上的文件。 PROCESS: 查看服务器中执行的线程信息或杀死线程。 RELOAD: 重载授权表或清空日志、主机缓存或表缓存。 SHUTDOWN: 关闭服务器。 ALL: 所有权限,ALLPRIVILEGES 同义词。 USAGE: 特殊的 "无权限" 权限
2.3.2示例
为 u_sxt 用户分配只能查询 bjsxt 库中的 employees 表,并且只能在本机登陆的权限。 grantselectONbjsxt.employeesto'u_sxt'@'localhost'IDENTIFIEDby'sxt'
2.4刷新权限
每当调整权限后,通常需要执行以下语句刷新权限 FLUSHPRIVILEGES
2.5删除用户
DROPUSERusername@localhost
八、 MySQL 分页查询
MySQL 分页查询原则 • 在 MySQL 数据库中使用 LIMIT 子句进行分页查询。 • MySQL 分页中开始位置为 0。 • 分页子句在查询语句的最后侧。
1 LIMIT 子句
1.1语法格式
SELECT 投影列 FROM 表名 WHERE 条件 ORDERBYLIMIT 开始位置,查询数量。
1.1.1示例
查询雇员表中所有数据按 id 排序,实现分页查询,每次返回两条结果。 select*fromemployeesorderbyemployees_idlimit0,2
2 LIMITOFFSET 子句
2.1语法格式
SELECT 投影列 FROM 表名 WHERE 条件 ORDER BY LIMIT 查询数量 OFFSET 开始位置。
2.1.1示例
查询雇员表中所有数据按 id 排序,使用 LIMITOFFSET 实现分页查询,每次返回两条 结果。 select*from employees orderbyemployees_idlimit2offset4














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









