





问题描述:
现有一系列气象数据,一个日期对应一个文件夹,每个文件夹中包含有若干个文件,每个文件中记录一个站点当日的数据,需要将所有时刻所有文件合并到一个文件中。
解决思路:
- 单文件读写
pandas.read_csv()函数可以实现将表格型数据读取为DataFrame对象,是我们读取文本文件时最常用的函数。read_csv()函数提供了非常多的可选参数,用于处理处理索引、类型判断、日期解析、迭代和数据清洗等。以文件6pollutants_conc_99006_2019182_72hours.txt作为示例,传入的参数分别为:文件名,header=0指定第一行为表头(列名),sep='s+'表明文件的分隔符为1个或者多个空格符号。
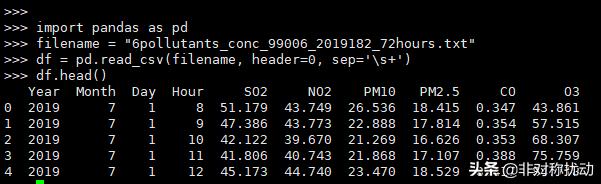
- 文件合并
我们需要挨个打开所有文件,axis=0轴向直接拼接,pd.concat()函数可以实现这个功能。
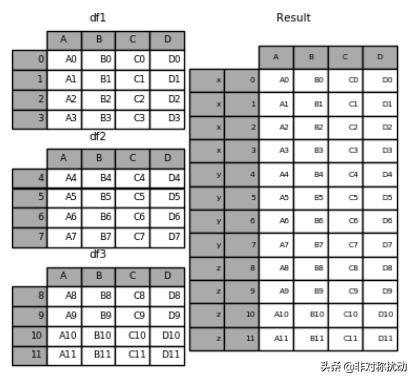
frames = [df1, df2, df3]
result = pd.concat(frames)
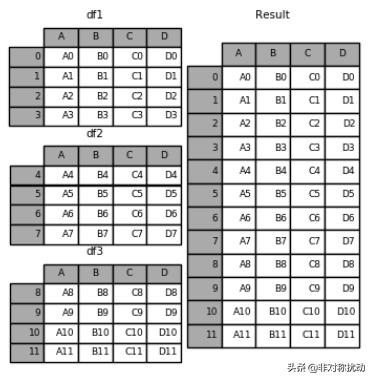
这样直接合并存在一个问题,两个站点的资料合并在一起就无法区分了。好在concat()函数提供了一个可选参数keys,可以将传递进来的键作为最外层构造层次索引。我们这里可以将站号传递给keys,生成一个站号在最外层的多层索引结构。
- 具体实现
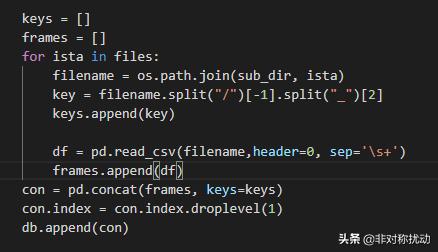
对于一个目录下的所有文件做一个循环,在循环内提取站号信息存入keys列表,读取DataFrame结构数据存入frames列表,循环结束之后调用con = pd.concat(frames, keys=keys)即可将所有站点信息合并。对于不同时刻(不同文件夹),可以在外面再套一层循环,不再赘述。
关注后私信邮箱+文件合并获取源码
推荐阅读
pandas实战:从文本文件中提取数据(数据规整)
pandas实战:计算相对湿度,循环提速300倍
pandas实战:干掉文本文件中的中文字符
pandas实战:从3个月逐小时文件中提取单站点数据(有缺测)















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









