





一、开始 Python 之旅交互模式

1.Ctrl + D 输入一个 EOF 字符来退出解释器,也可以键入 exit() 来退出
2.#!/usr/bin/env python3 中#!称为 Shebang,目的是告诉shell使用Python 解释器执行其下面的代码。
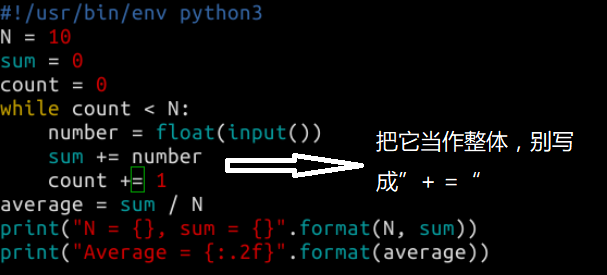
3.注意遵守以下约定:
使用 4 个空格来缩进
永远不要混用空格和制表符
在函数之间空一行
在类之间空两行
字典,列表,元组以及参数列表中,在 , 后添加一个空格。对于字典,: 后面也添加一个空格
在赋值运算符和比较运算符周围要有空格(参数列表中除外),但是括号里侧不加空格:a = f(1, 2) + g(3, 4)
4.模块是包含能复用的代码的文件,包含了不同的函数定义,变量。模块文件通常以 .py 为扩展名,在使用模块前先导入它。

二、变量和数据类型
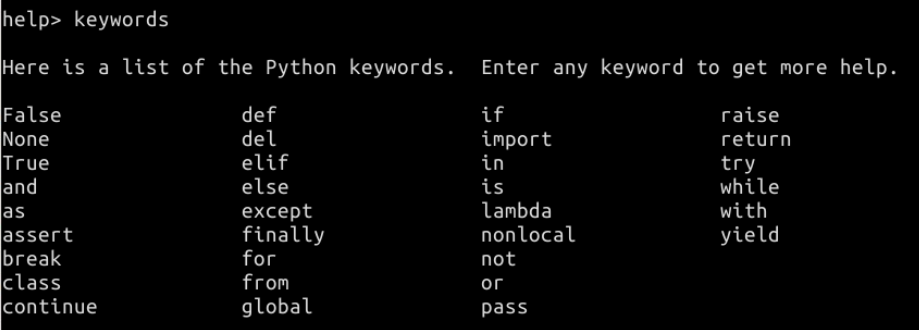
1.关键字(不能用于通常的标识符)
2.定义变量
不需要为变量指定数据类型,操作字符串时用单引号或双引号括起来
3.从键盘读取输入
number = int(input("Enter an integer: "))
4.在一行内将多个值赋值给多个变量
>>> a , b = 4, 5
>>> a
4
>>> b
5
用逗号创建元组,在赋值语句的右边创建元组称这为元组封装(tuple packing),赋值语句的左边做的是元组拆封 (tuple unpacking)。
三、运算符和表达式
divmod()
divmod()函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b):
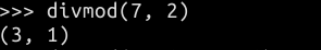
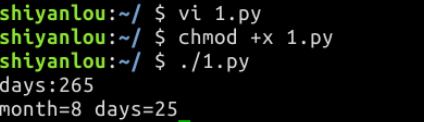
若现在通过获得用户输入的天数,算出月份数和天数,则可以使用该函数轻松get到答案:
#!/usr/bin/env python3
days = int(input("Enter days: "))
print("Months = {} Days = {}".format(*divmod(days, 30))) 用 * 运算符拆封这个元组
整除
如果要进行整除,使用 // 运算符,它将返回商的整数部分:

思考:如果是12 / 3,结果是多少呢?大家一定会说是不是傻?肯定是4啊!那试试呗:
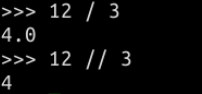
和你想的不一样吧!所以/不管是不是整除,结果都是浮点数。
逻辑运算符
逻辑运算符 and 和 or 也称作短路运算符:它们的参数从左向右解析,一旦结果可以确定就停止 。作用于一个普通的非逻辑值时,短路运算符的返回值通常是能够最先确定结果的那个操作数。
运算符
逻辑表达式
描述
and
x and y
如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。
or
x or y
如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。
not
not x
如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。
>>> 5 and 4 (5为True还要往后看,所以最先确定的操作数是4)
4
>>> 0 and 4 (0为False不需往后看,所以最先确定的操作数是0)
0
>>> False or 3 or 0 (False还要往后看,3为True不需往后看,所以最先确定的操作数是3)
3
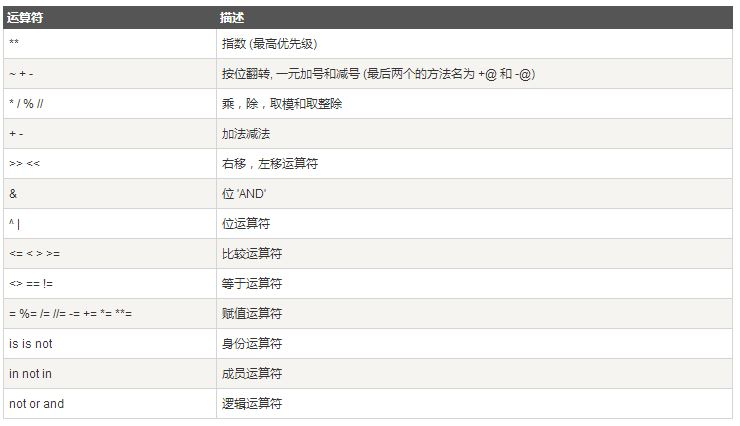
运算符优先级
类型转换
类型转换中,int、float转字符串用str()就行了,非常容易理解,字符串是"数字"字符串('1234')转int也好理解,但如果是字符串'a'呢?可能你会想到ASCII,用int('a')可以吗?

结果显示不可以,所以,再恶补点知识吧!
1.十进制字符串转整数
int('12') ==12
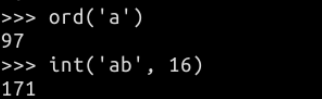
2.十六进制字符转整数
int('a',16) == 10
例MAC地址转整数:
a='FF:FF:FF:FF:FF:FF'.split(:)
int(a[0],16) = 255
int(a[1],16) = 255
int(a[2],16) = 255
int(a[3],16) = 255
int(a[4],16) = 255
int(a[5],16) = 255
3.字符转整数
ord('a')==97
4.整数转为字符
chr(65) == 'A'
四、循环
range()
range() 生成一个等差数列(并不是列表):
>>> for i in range(3):
... print(i)
...
0
1
2
>>> range(1, 5)
range(1, 5)
>>> list(range(1, 5))
[1, 2, 3, 4]
>>> list(range(1, 15, 3))
[1, 4, 7, 10, 13]
循环的 else 语句
可以在循环后面使用可选的 else 语句,它将会在循环完毕后执行,除非有 break 语句终止了循环。
斐波那契(Fibonacci)数列
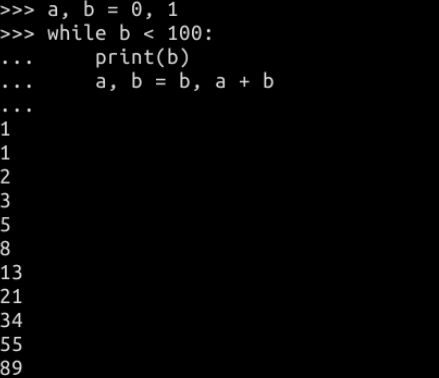
Python 中赋值语句执行时会先对赋值运算符右边的表达式求值,然后将这个值赋值给左边的变量。
如果要把结果输出不换行呢?print() 除了打印提供的字符串之外,还会打印一个换行符,所以每调用一次 print() 就会换一次行。可以通过参数 end 来替换换行符:
a, b = 0, 1
while b < 100:
print(b, end=' ')
a, b = b, a + b
print()

幂级数:e^x = 1 + x + x^2 / 2! + x^3 / 3! + ... + x^n / n! (0 < x < 1)
#!/usr/bin/env python3
x = float(input("Enter the value of x: "))
n = term = num = 1
result = 1.0
while n <= 100:
term *= x / n
result += term
n += 1
if term < 0.0001:
break
print("No of Times= {} and Sum= {}".format(n, result))
打印图形
print("#" * 50)字符串若是乘上整数 n,则返回由 n 个此字符串拼接起来的新字符串。如要打印出下图:
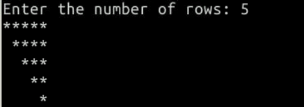
row = int(input("Enter the number of rows: "))
n = row
while n >= 0:
x = "*" * n
y = " " * (row - n)
print(y + x)
n -= 1
五、数据结构
列表
列表可以写作中括号之间的一列逗号分隔的值。列表的元素不必是同一类型,通过索引来访问列表中的每一个值,列表允许修改元素,允许嵌套。
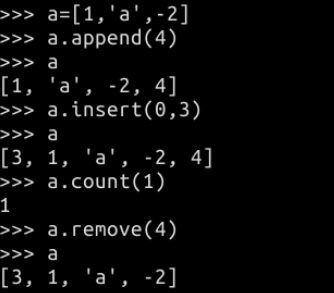
a.append() 添加元素到列表的末端
a.insert(0, 1) 在列表索引 0 位置添加元素 1
a.count(s) 返回列表中 s 元素出现的次数。
a.remove(s) 移除列表中s元素
a.pop(n) 返回索引为n的元素并把它从列表中删除,无参数时默认最后一个元素
del a[n] 删除索引为n的列表元素
a.reverse() 反转整个列表
a.sort() 给列表排序,排序的前提是列表的元素是可比较的
a.extend(b) 将b列表的所有元素添加到a列表末尾,注意是添加 b 的元素而不是 b 本身
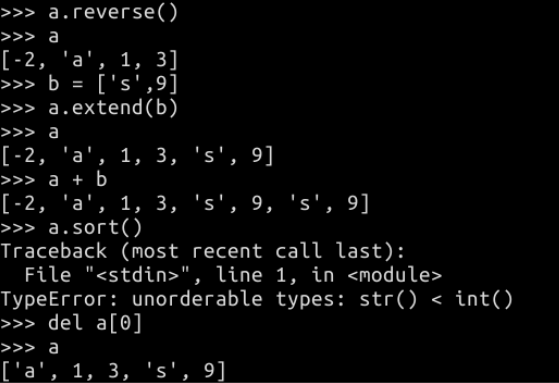
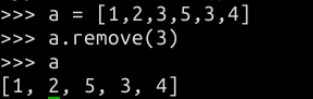
思考:如果列表中有相同的元素,用remove删除的是前面那个还是后面那个,亦或是全删除呢?实践一下呗!
列表推导式由包含一个表达式的中括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句。结果是一个列表,由表达式依据其后面的 for 和 if 子句上下文计算而来的结果构成。以下两种方式等同:
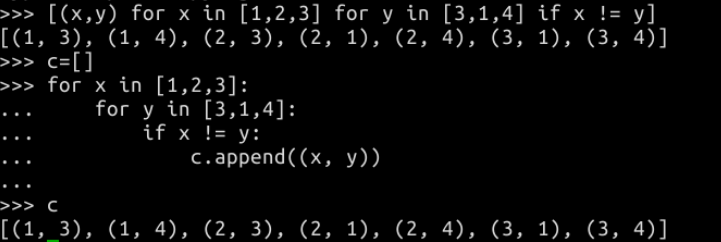
列表推导式也可以嵌套:
>>> a=[1,2,3]
>>> z = [x + 1 for x in [x ** 2 for x in a]]
>>> z
[2, 5, 10]
如果在遍历列表(或任何序列类型)的同时获得元素索引值,可以使用 enumerate():
>>> for i, j in enumerate(['a', 'b', 'c']):
... print(i, j)
...
0 a
1 b
2 c
同时遍历两个序列类型可以使用zip() :
>>> a = ['a', 'b']
>>> b = ['c', 'd']
>>> for x, y in zip(a, b):
... print("{} and {}".format(x, y))
元组
元组是由数个逗号分割的值组成,且为不可变类型,意味着不能在元组内删除或添加或编辑任何值。
>>> a = 'a', 'b', 'c',
>>> a
('a', 'b', 'c')
创建只含有一个元素的元组,在值后面跟一个逗号,这是因为括号()既可以表示元组,又可以表示数学公式中的小括号,这就产生了歧义。
>>> a = (123) 这样定义的将是123这个元素,而不是一个元组。
>>> a
123
>>> type(a)
>>> a = (123, )
>>> b = 321,
>>> a
(123,)
>>> b
(321,)
>>> type(a)
>>> type(b)
可以对任何一个元组执行拆封操作并赋值给多个变量,注意赋值时数量要匹配:
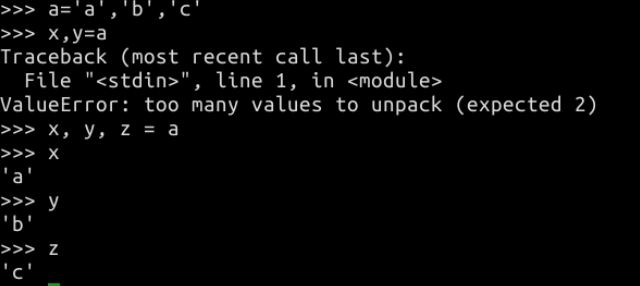
集合
集合是一个无序不重复元素的集,大括号或 set() 可以用来创建集合
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) 可以看到重复的元素被去除
{'orange', 'banana', 'pear', 'apple'}
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'} a 去重后的字母
>>> a - b a 有而 b 没有的字母
>>> a | b 存在于 a 或 b 的字母
>>> a & b a 和 b 都有的字母
>>> a ^ b 存在于 a 或 b 但不同时存在的字母
>>> a.add('c')
>>> a
{'c',a', 'r', 'b', 'c', 'd'} 不同于列表的append(),在起始位置添加
字典
字典是是无序的键值对(key:value)集合,同一个字典内的键必须是互不相同的。一对大括号 {}创建一个空字典。字典中的键必须是不可变类型,比如不能使用列表作为键。
>>> data = {'kushal':'Fedora', 'kart_':'Debian', 'Jace':'Mac'}
>>> data['kart_']
'Debian'
>>> data['parthan'] = 'Ubuntu' 创建新的键值对
>>> data
{'kushal': 'Fedora', 'Jace': 'Mac', 'kart_': 'Debian', 'parthan': 'Ubuntu'}
>>> del data['kushal'] del 删除任意指定的键值对
>>> data
{'Jace': 'Mac', 'kart_': 'Debian', 'parthan': 'Ubuntu'
>>> dict((('In','Del'),('Bang','Dh'))) dict() 从包含键值对的元组中创建字典
{'In': 'Del', 'Bang': 'Dh'}
>>> for x, y in data.items(): items()获得由键和值组成的列表
... print("{} uses {}".format(x, y))
dic.clear()清空字典
dic.keys()获得键的列表
dic.values()获得值的列表
dic.copy()复制字典
dic.pop(k)删除键k
dic.get(k)获得键k的值
dic.update()更新成员,若成员不存在,相当于加入
很多时候需要往字典中的元素添加数据,使用dict.setdefault(key, default):
>>> data = {}
>>> data.setdefault('names', []).append('Ruby')
>>> data
{'names': ['Ruby']}
>>> data.setdefault('names', []).append('Python')
>>> data
{'names': ['Ruby', 'Python']}
>>> data.setdefault('names', []).append('C')
>>> data
{'names': ['Ruby', 'Python', 'C']}
切片
切片的语法表达式为[start_index : end_index : step]:
start_index表示起始索引
end_index表示结束索引
step表示步长,步长不能为0,且默认值为1
切片操作是指按照步长,截取从起始索引到结束索引,但不包含结束索引的所有元素。
python3支持切片操作的数据类型有list、tuple、string、unicode、range
切片返回的结果类型与原对象类型一致
切片不会改变原对象,而是重新生成了一个新的对象
切片的索引可分为正向和负向两种:
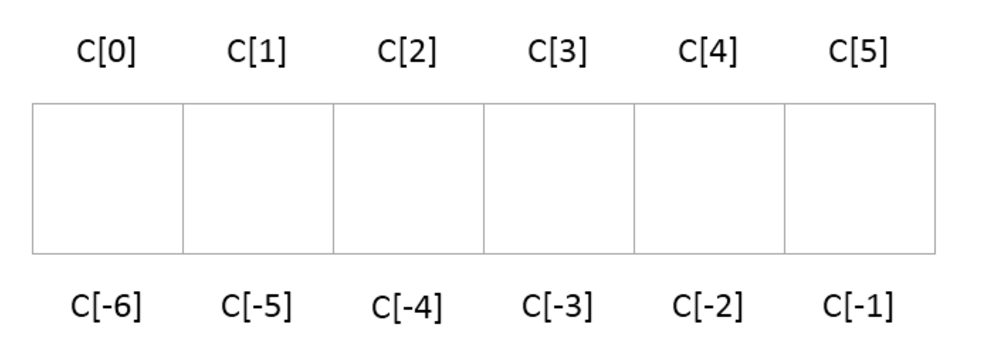
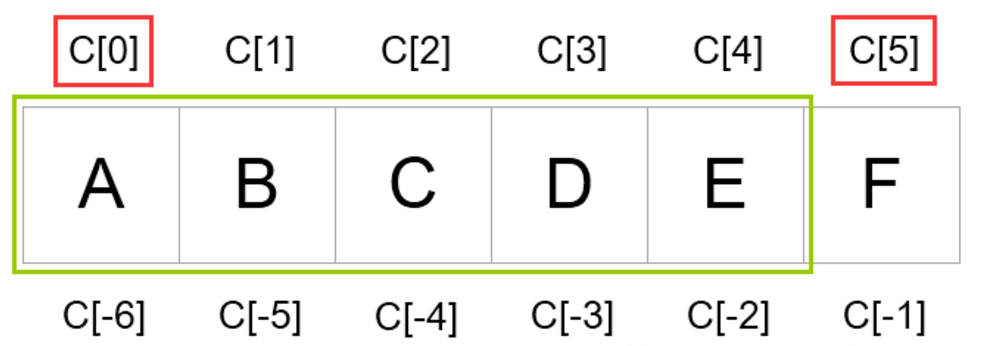
举个例子:
>>> C = ['A','B','C','D','E','F']
>>> C[0:5:1]
['A', 'B', 'C', 'D','E']
省略 start_index 会从第一个元素开始,省略 end_index 会切到最后一个元素为止:
>>> C[2:]
['C', 'D', 'E', 'F']
步长为负数时即为逆着切,一定要保证start_index到end_index的方向与步长step的方向同向,否则会切出空的序列:
>>> C[0:3:-1]
[]
>>> C[3:0:1]
[]
数据结构举例
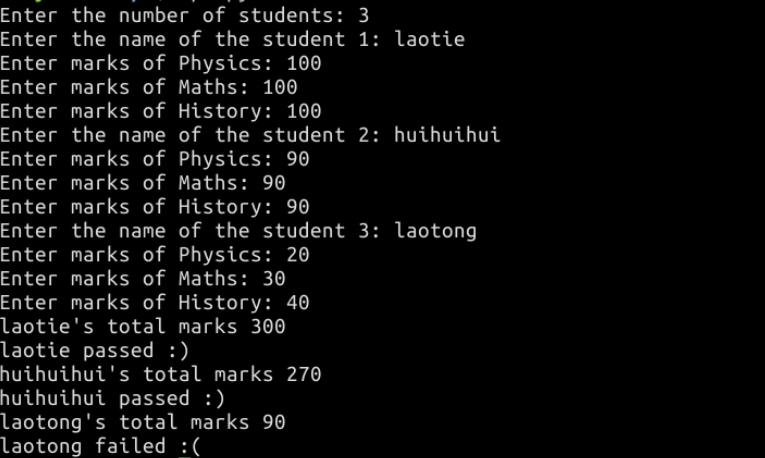
1.判断学生成绩是否达标:要求输入学生数量,以及各个学生物理、数学、历史三科的成绩,如果总成绩小于 120,程序打印 “failed”,否则打印 “passed”。
n = int(input("Enter the number of students: "))
data = {} 用来存储数据的字典变量
Subjects = ('Physics', 'Maths', 'History')
for i in range(1, n+1):
name = input('Enter the name of the student {}: '.format(i))
marks = []
for x in Subjects:
marks.append(int(input('Enter marks of {}: '.format(x))))
data[name] = marks
for x, y in data.items():
total = sum(y)
print("{}'s total marks {}".format(x, total))
if total < 120:
print(x, "failed :(")
else:
print(x, "passed :)")
运行如下:
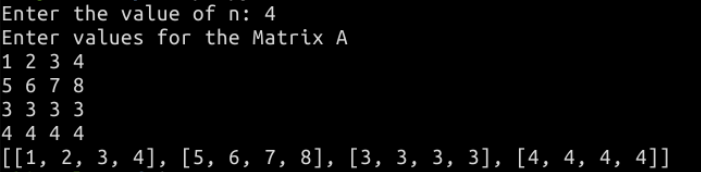
2.用以下代码解决矩阵问题:
n = int(input("Enter the value of n: "))
print("Enter values for the Matrix A")
a = []
for i in range(n):
a.append([int(x) for x in input().split()])
print(a)
其实这里不太理解为什么最后结果为列表嵌套列表(str.split(str="", num=string.count(str)),str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等,num -- 分割次数),而且以为这是生成 n × n 的矩阵,所以进行以下实践:

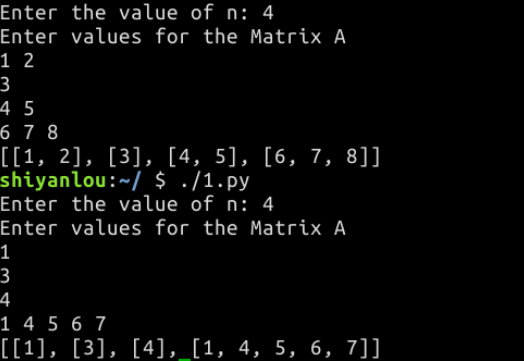
可以看出,split()最后拆成的是列表,以换行符结束一次循环,并不是生成n × n 的矩阵。相对于split(),join()使用指定字符连接多个字符串,它需要一个包含字符串元素的列表作为输入,然后连接列表内的字符串元素:
>>> "-".join("GNU/Linux is great".split())基于空格分割字符串(列表),再用 "-" 连接
'GNU/Linux-is-great'
六、字符串
三引号(triple quotes)
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
>>> h = '''hi
Jspo'''
>>> hi
'hi\nJspo'
>>> print hi
hi
Jspo
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。一个典型的用例是,当需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐。
此外,在 Python 里使用文档字符串(docstrings)来说明如何使用代码:
def longest_side(a, b):
"""
Function to
"""
return True
字符串常用操作
string.title() 返回字符串的标题版本,即单词首字母大写其余字母小写
string.upper() 返回字符串全部大写版本
string.lower() 返回字符串全部小写版本
string.swapcase() 返回字符串大小写交换后的版本
string.isalnum() 检查所有字符是否为字母数字
string.isalpha() 检查字符串之中是否只有字母
string.isdigit() 检查字符串是否所有字符为数字
strip(chars)用来剥离字符串首尾中指定的字符,不指定参数则默认剥离掉首尾的空格和换行符。用 lstrip(chars) 或 rstrip(chars) 只对字符串左或右剥离:
>>> s = "www.foss.in"
>>> s.lstrip("cwsd.") 删除在字符串左边出现的'c','w','s','d','.'字符
'foss.in'
>>> s.rstrip("cnwdi.") 删除在字符串右边出现的'c','n','w','d','i','.'字符
'www.foss'
文本搜索
find() 能帮助找到第一个匹配的子字符串,没有找到则返回 -1。string.find(str, beg=0, end=len(string))
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1。
s.startswith(str) 检查字符串是否以 str 开头
s.endswith(str) 检查字符串是否以 str 结尾
字符串更多操作详见:Python 字符串
例题(挑战:字符串操作)
String.txt文件内容为awe3fa8fa4aewfawijfa;fjaweawfeawawefargaefaef5awefasdfeargfasdcds2awea4afadszsdvzxefafzsdva7fasdczdvafedszv6zvczvdsf2awefafzsdccsea,请把该文件中所有的数字组成一个新的字符串,并且打印出来。
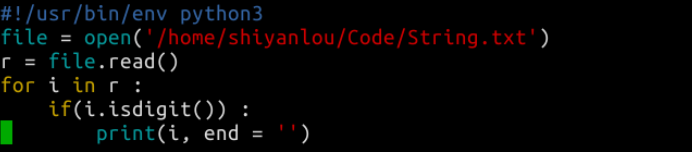

注:学了后面的课程发现这个挑战自己没将文件关闭(file.close()),要养成习惯,不然记得使用 with!
七、函数
def 函数名(参数列表):
函数体
不带表达式的return相当于返回 None。
参数传递
在 python 中,类型属于对象,变量是没有类型。如a=[1,2,3]和a="Jspo",[1,2,3] 是 List 类型,"Jspo" 是 String 类型,而变量 a 是没有类型,仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了
python 函数的参数传递:
不可变类型:类似值传递,传递的只是a的值,没有影响a对象本身(加global变为全局变量)
可变类型:类似引用传递
参数类型
必需参数:以正确的顺序传入函数,调用时的数量必须和声明时的一样
关键字参数:形如 keyword = value,使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值
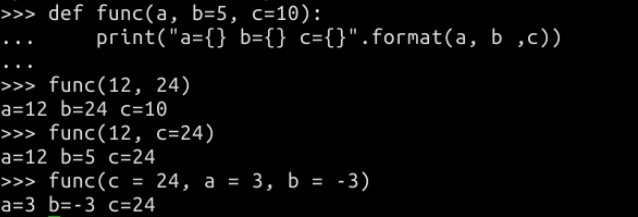
默认参数:调用函数时,如果没有传递参数,则会使用默认参数,默认参数必须放在最后。如上图如果调用者未给出 b、c 的值,那么它们的值默认为5和10
不定长参数:需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名
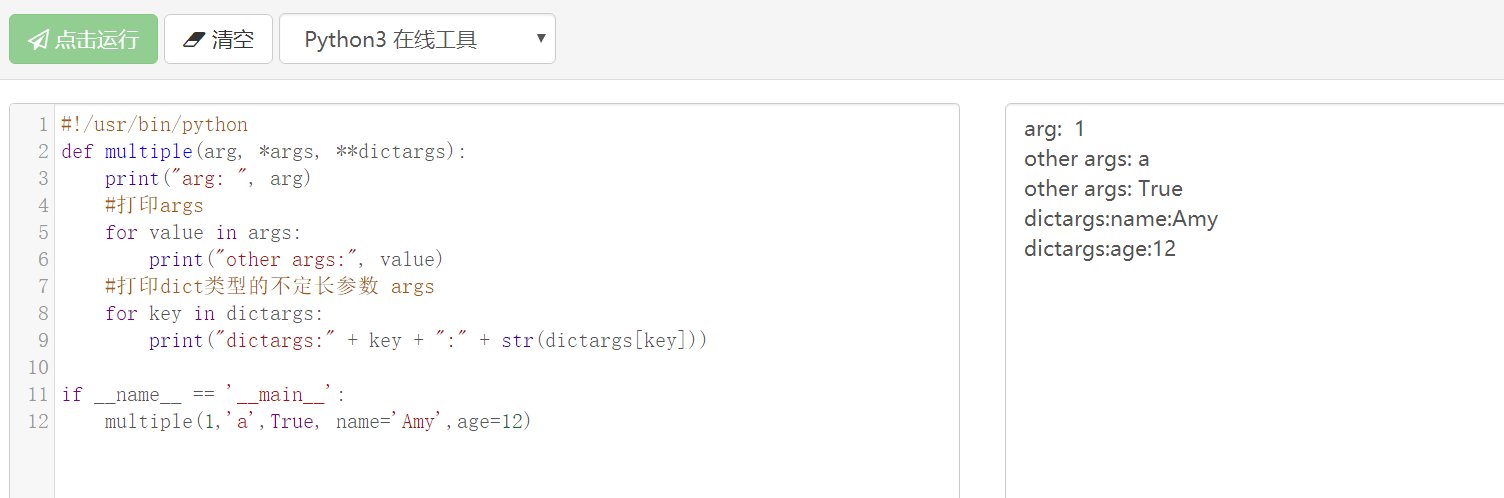
对不定长参数再说几句:加了星号(*)的变量名会存放所有未命名的变量参数,不能存放dict。加了星号(**)的变量名会存放所有未命名的变量参数(如果在函数调用时没有指定参数,它就是一个空元)。举个例子:
def multiple(arg, *args, **dictargs):
print("arg: ", arg)
#打印args
for value in args:
print("other args:", value)
#打印dict类型的不定长参数 args
for key in dictargs:
print("dictargs:" + key + ":" + str(dictargs[key]))
if __name__ == '__main__':
multiple(1,'a',True, name='Amy',age=12)
高阶函数
map 接受一个函数和一个序列(迭代器)作为输入,然后对序列(迭代器)的每一个值应用这个函数,返回一个序列(迭代器),其包含应用函数后的结果。
>>> lst = [1, 2]
>>> def s(num):
... return num * num
...
>>> print(list(map(s, lst)))
[1, 4]

注:千万别忘了map前加list!
八、文件处理
常见操作
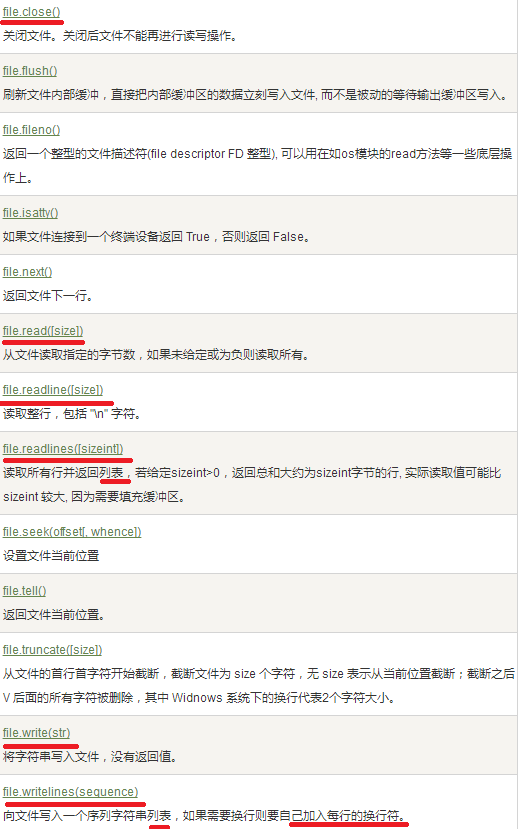
使用 open() 函数打开文件,需要两个参数,第一个参数是文件路径或文件名,第二个是文件的打开模式:
"r",以只读模式打开,你只能读取文件但不能编辑/删除文件的任何内容
"w",以写入模式打开,如果文件存在将会删除里面的所有内容,然后打开这个文件进行写入
"a",以追加模式打开,写入到文件中的任何数据将自动添加到末尾
例题
例1:拷贝给定的文本文件到另一个给定的文本文件:
import sys
if len(sys.argv) < 3:
print("Wrong parameter")
print("./copyfile.py file1 file2")
sys.exit(1)
f1 = open(sys.argv[1])
s = f1.read()
f1.close()
f2 = open(sys.argv[2], 'w')
f2.write(s)
f2.close()
sys模块:sys.argv 包含所有命令行参数。
sys.argv 的第一个值是命令自身的名字:
import sys
print("First value", sys.argv[0])
print("All values")
for i, x in enumerate(sys.argv):
print(i, x)
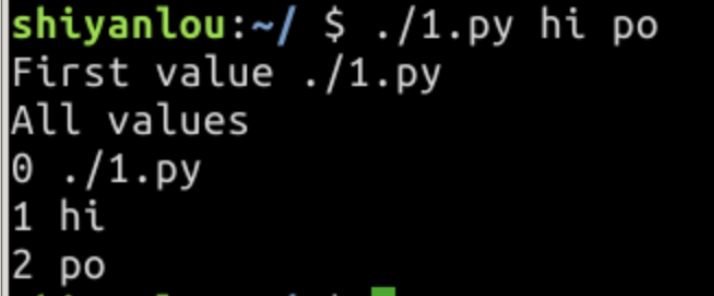
enumerate(iterableobject)可以同时得到索引位置和对应值。
例2:对任意给定文本文件中的制表符、行、空格进行计数。
import os
import sys
def parse_file(path):
fd = open(path)
i = 0
spaces = 0
tabs = 0
for i,line in enumerate(fd):
spaces += line.count(' ')
tabs += line.count('\t')
# 现在关闭打开的文件
fd.close()
# 以元组形式返回结果
return spaces, tabs, i + 1
def main(path):
if os.path.exists(path):
spaces, tabs, lines = parse_file(path)
print("Spaces {}. tabs {}. lines {}".format(spaces, tabs, lines))
return True
else:
return False
if __name__ == '__main__':
if len(sys.argv) > 1:
main(sys.argv[1])
else:
sys.exit(-1)
sys.exit(0)
小Tips:
如果要统计文件的行数,可以用count = len(open(filepath, 'r').readlines()),虽然简单,但是可能比较慢,当文件比较大时甚至不能工作。因此可以利用enumerate():
count = 0
for index, line in enumerate(open(filepath,'r')):
count += 1
此外,使用 with 语句处理文件对象会在文件用完后会自动关闭,就算发生异常也没关系。它是 try-finally 块的简写:
with open('sample.txt') as f:
for line in f:
print(line, end = '')
九、异常
在 Python3 中使用 Python2 独有的语法就会发生 SyntaxError
当有人试图访问一个未定义的变量则会发生 NameError
当操作或函数应用于不适当类型的对象时引发TypeError,一个常见的例子是对整数和字符串做加法
try--except
首先,执行 try 子句 ,如果没有异常发生,except 子句 在 try 语句执行完毕后就被忽略了。
如果在 try 子句执行过程中发生了异常,那么该子句其余的部分就会被忽略。
如果异常匹配于 except 关键字后面指定的异常类型,就执行对应的 except 子句。然后继续执行 try 语句之后的代码。
如果发生了一个异常,在 except 子句中没有与之匹配的分支,它就会传递到上一级 try 语句中。
如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
except可以处理一个专门的异常,也可以处理一组圆括号中的异常,如果except后没有指定异常,则默认处理所有的异常。
raise
raise 语句抛出一个异常。如"挑战:玩转函数"中要求用户能够通过命令行输入分钟数,程序需要打印出相应的小时数和分钟数。如果用户输入的是一个负值,程序需要报错 ValueError,在屏幕上打印出ValueError: Input number cannot be negative 提示用户输入的值有误。
import sys
def ToHours(time):
print("{} H, {} M".format(*divmod(time, 60)))
time =int (sys.argv[1])
if time < 0:
try:
raise ValueError
except ValueError:
print("ValueError: Input number cannot be negative")
else:
ToHours(time)

finally
不管有没有发生异常,finally 子句在程序离开 try 后都一定会被执行。当 try 语句中发生了未被 except 捕获的异常(或者它发生在 except 或 else 子句中),在 finally 子句执行完后它会被重新抛出:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
KeyboardInterrupt
Traceback (most recent call last):
File "", line 2, in ?
在真实场景的应用程序中,finally 子句用于释放外部资源(文件或网络连接之类的),无论它们的使用过程中是否出错。














 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









