





这门课程是由斯坦福大学在今年 4 月份推出的线上课程,主讲人是 Reza Zadeh ,总体来说主讲人讲解比较幽默,内容也是容易让人听得下去,不是那么晦涩难懂。课程内容分为两个部分:并行计算(parallel computing),分布式计算(distributed computing)。并行计算与分布式计算有啥区别呢?主要的区别在于:并行计算主要是在共享内存情况下的同时计算;而分布式计算则是更多需要考虑网路通信。
并行计算简介
为什么我们要研究并行计算呢?现在 CPU 性能这么强劲,为啥还要费力研究用多个核一起计算呢?主要原因在于 CPU 的性能优化受到以下限制:CPU 的运算会有上限,3 Gigahertz;并且 CPU 的散热也是有限的。但是与之相对的是:RAM,硬盘空间却是处于不断增长的情况。因为硬件制造商开始从开发更快的处理器,转为开发多核处理的系统。由于计算从连续计算变为了并行计算,我们也就需要开始研究并行计算算法。
要研究并行算法,我们首先要明确的一个问题就是我们如何来评估并行算法的效率。通常来说,一个算法的效率可以用完成该算法所需要的操作数目(operation)来评估。但是当我们研究并行算法的时候,情况可就大不一样了。一个高效的并行算法在单个处理器上可能并不高效,反之亦然。所以,为了评估并行算法是否高效,Reza 引入了 work-depth ,并且介绍了算法如何设计来优化该目标。
Parallel RAM 模型
第一个要介绍的并行算法是:Parallel RAM(PRAM)。RAM(Random Access Memory) 模型是典型的连续模型, 在 RAM 中,对于一个特定的内存单元

一般来说,这些情况中最常用的是同时读取,独占写入的情况。当然也会有同时写入的情况。
在处理同时写入情况时,需要仔细考虑多个处理器同时向同一内存的同一区域写入有冲突的情况,一般有以下方式来解决同时写入:
- Undefined/Garbage: 机器可能会挂掉或者写入的结果被当成垃圾处理
- Arbitrary: 没有事先定义好的确定处理器写入优先级的规则,每次都随机选取处理器进行写入
- Priority: 事先确定好各处理器写入的顺序
- Combination: 根据写入值来确定写入的顺序(比如最大值,负数等优先写入),与 Priority 方式不同点在于,这个利用了写入值来确定写入顺序,而前者则是根据处理器来决定顺序
通用 Parallel RAM 模型
Parallel RAM 模型主要有以下两类:
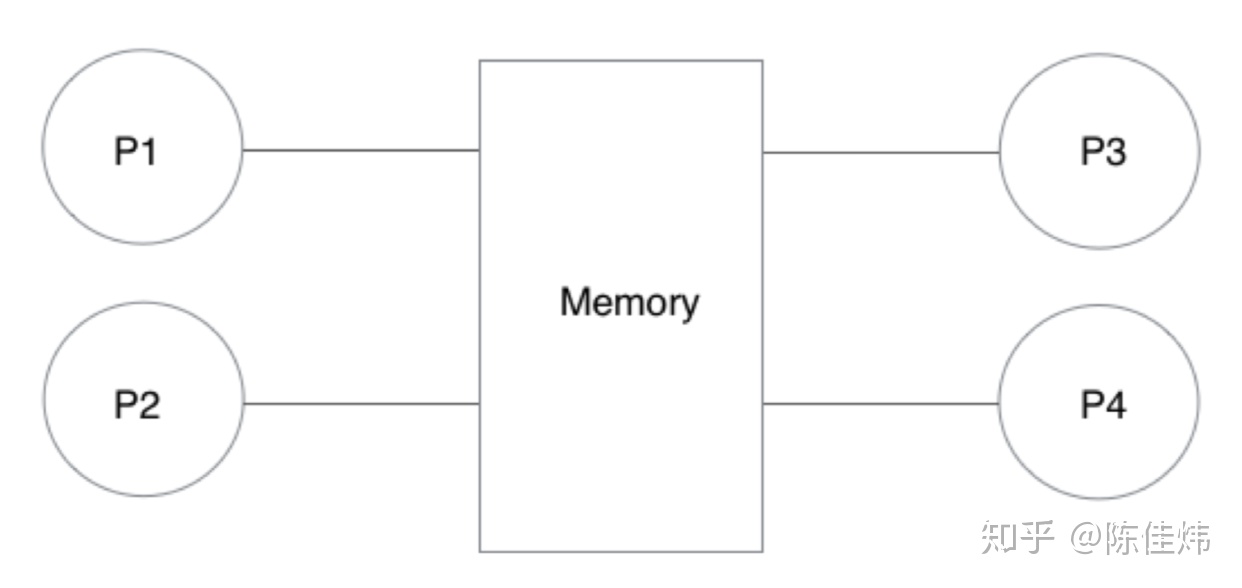
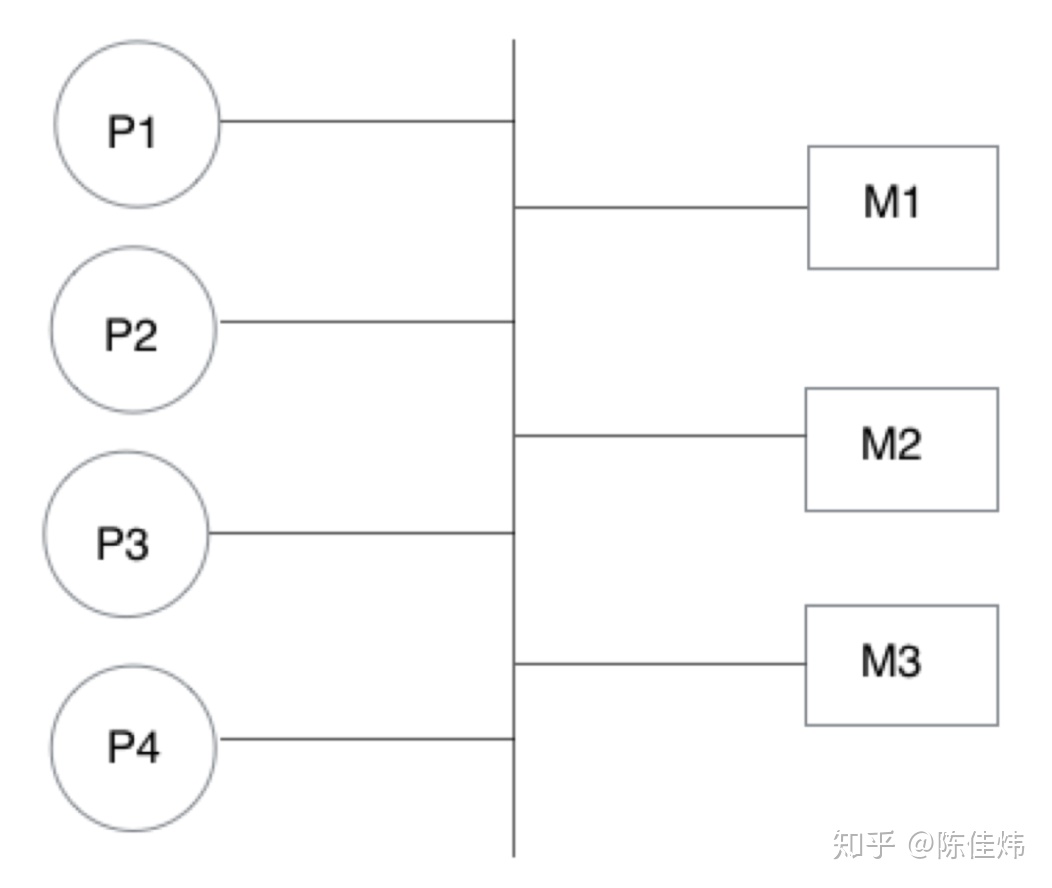
在实际使用的过程中,处理器与内存之间可能还存在额外的 cache 层。
work 与 depth 的实际意义
work :算法的 work 是指完成算法消耗的时间乘以完成算法消耗的处理器的数目
depth:在并行算法中,我们需要等待计算最缓慢的处理器完成计算,整个计算过程才算真正完成,这个时间就是算法的 depth
对于同样一个算法,如果该算法在单个处理器上进行处理,其耗时定义为:
这也是分布式算法希望达到的下界。
算法的 DAG 表示
我们可以使用一个有向无环图来表示算法中不同操作之间的依赖关系。可以这样来将算法构建为 DAG: 当节点
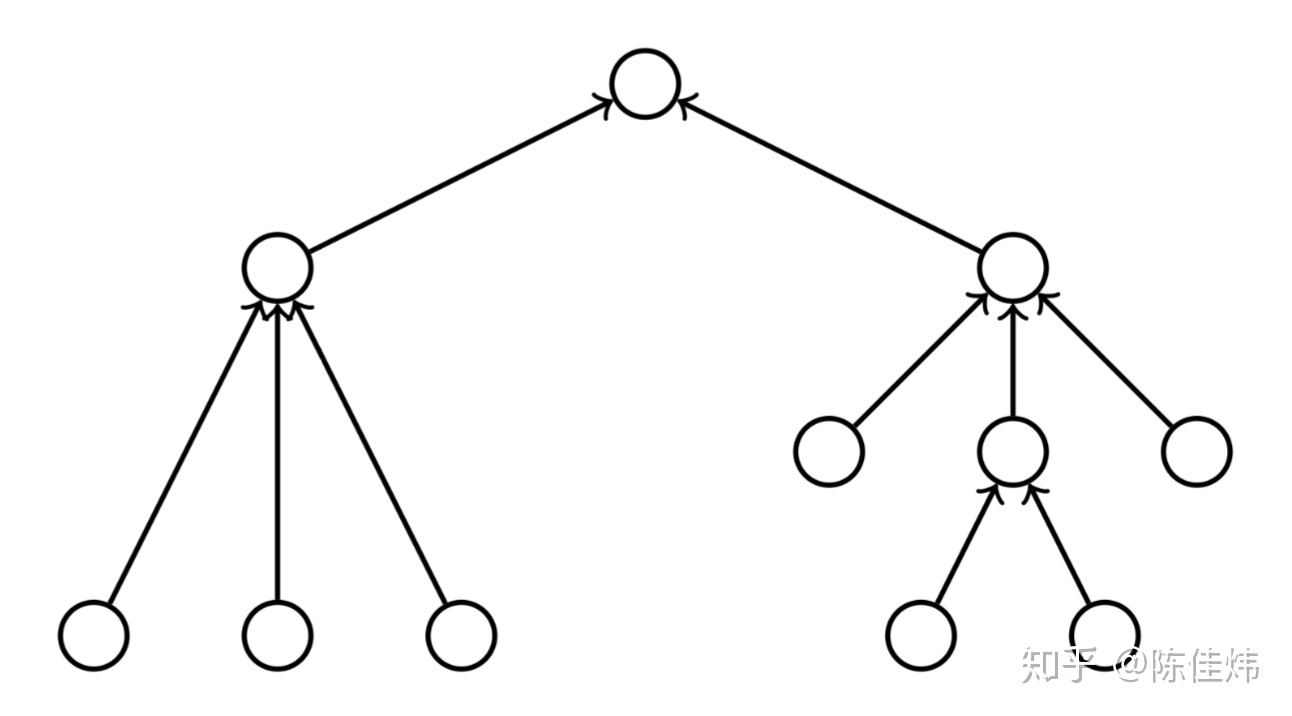
我们可以把 DAG 看成是一棵树,它的 root 的 depth 是 0,root 的 children 的 depth 是 1,以此类推。将
那么当我们拥有无限的处理器的时候,执行算法的耗时是多少呢?耗时就是算法的 depth。定义如下:
Brent's 定理
定义:假设算法的各过程是最优调度的














 2238
2238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









