






作者:才哥
由于在工作中需要处理很多日志文件数据,这些数据并不存在于数据库,而是以每日1个单文件的形式存在,为了让我们在日常数据处理中更方便的进行一些基础的数据合并、清洗筛选以及简单的分组或数据透视处理,结合PyQt5与pandas库,制作了一个简单的数据处理可视化工具。
执行效果
我们运行脚本打包后的 exe 可执行文件,设定相关参数后点击“数据处理并导出”即可等待处理~
以下是29文件共1400余万行数据的处理结果,差不多用了10分钟合并并处理导出所需结果~
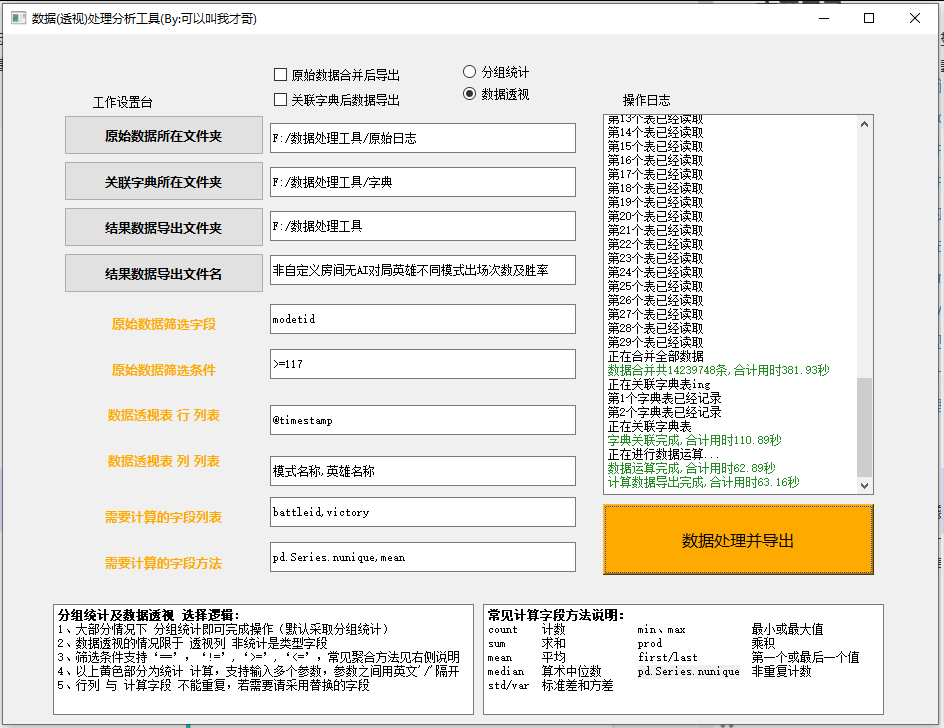
1.窗体可视化设计
采用PyQt5进行可视化界面设计,具体设计过程可以直接在QT designer中进行操作,然后转化为可视化界面的py文件。
界面效果如下图:
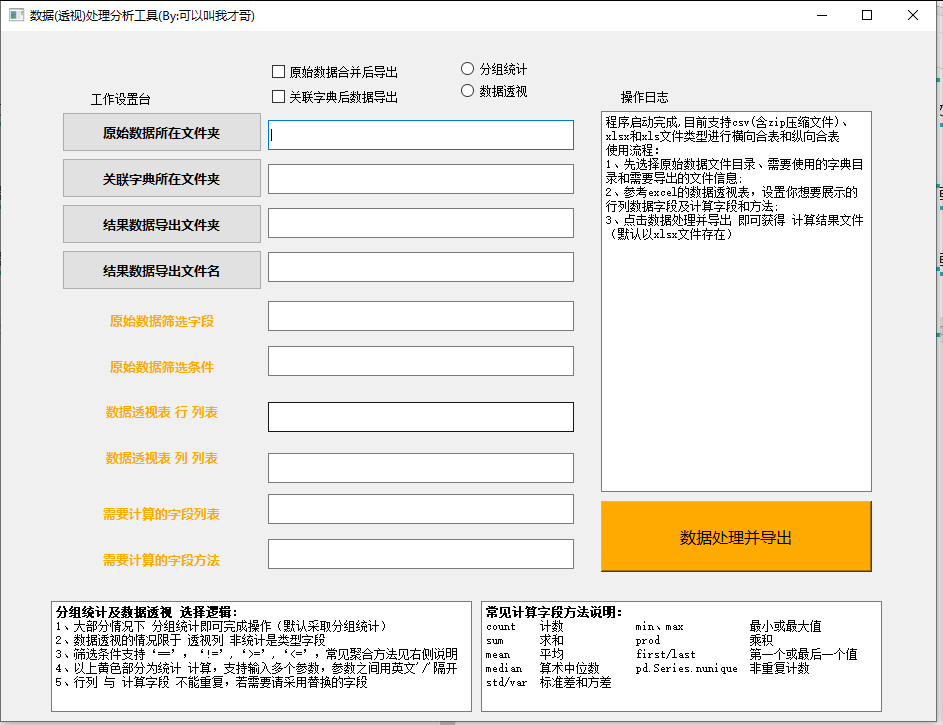
对于我们的操作界面,支持以下功能:
- 选择原始数据所在的文件夹
- 选择需要vlookup的文件所在的文件夹
- 选择处理后结果导出的文件夹
- 输入结果导出的文件名
- 在原始数据中用于过滤筛选的字段
- 在原始数据中用于过滤筛选的条件
- 如果做数据透视的行(index)
- 数据透视的列(column)
- 用于计算的字段
- 用于计算的方法
2.多文件合并
由于我们拿到的原始数据是以日期为文件名的csv文件,如果需要处理多天的数据,需要进行简单的数据合并后再做相关数据处理操作。
这一步其实有4个操作:①获取文件夹下的文件列表 ②根据文件类型进行文件读取 ③对读取的文件进行简单的数据清洗 ④合并清洗后的数据
2.1.获取文件夹下的文件列表
获取文件夹下文件列表可以使用os.walk方法,产生3-元组 (dirpath, dirnames, filenames)【文件夹路径, 文件夹名字, 文件名】。
根据文件夹路径+文件名即可组成改文件的绝对路径,用于后续文件读取。
1]: 2.2.根据文件类型进行文件读取
由于在实际操作过程中,可能存在原始文件是csv压缩包zip格式,或者xlsx格式。我们需要根据文件名后缀进行判断,然后选择对应的读取文件数据方法。
采用os.path.splitext(“文件路径”) 分离文件名与扩展名,默认返回(fname,fextension)元组。
这里我们只考虑两种情况:csv(含zip)以及xlsx(含xls):
if filetype == 2.3.对读取的文件夹下简单的数据清洗
对于读取的文件数据,并不是所有的数据都是我们需要用到的,或者说我们需要用到的数据可能是需要满足指定条件的。
比如对于下面这个情况,读取 9.csv 文件后,我们看到 usernum 每个值出现的次数,然后我希望取满足uesrnum为10的数据。
'F:\数据处理工具\测试数据\9.csv')我们用到布尔索引即可df[df['usernum']==10]
'usernum']==10]但是,因为我们的筛选字段及条件都是通过可视化操作界面进行输入的,输入的数据类型在程序中是字符串,所以我们需要将其处理成为可以用于条件筛选的形式。而且,我们在进行清洗的时候字段及条件可能是多个的。
比如我输入的字段为:usernum/victory;输入的条件为:>=6/==1。
那我们实际上需要进行的清洗过程是df = df[df['usernum']>=6] 和 df = df[df['victory']==1],为实现这个效果,可以用最简单的字符拼接的形式 s = f"Li['{checkli[0]}']{conditionli[0]}",然后进行eval(s)转化。
#获取输入的筛选字段(用‘/’分割),我们用'/'拆分为列表关于数据清洗处理,我们会在pandas学习笔记中进行详细介绍~
2.4.合并清洗后的数据
这一步就比较简单了,直接将需要合并的数据添加的列表中,然后concat合并即可。不过,需要做个简单的判断,如果原始只有1个文件,直接就取改文件即可;超过1个文件情况下,才需要执行合并操作。
#...读取并清洗数据...3.多文件拼接(merge)
这个其实也比较简单,我们事先把需要用于横向拼接的文件放到指定目录后,读取文件列表逐一和第2节中的处理过的原始数据进行merge处理。
基于第2节中介绍过的文件夹下文件列表读取,这里只介绍merge处理。
还是一样的逻辑,先判断是否有需要merge的文件,然后再执行后续操作,我们需要用到左连接方式处理。
#...读取需要用于merge的文件组合成列表...4.数据处理
数据处理中我们可以用到pivot_table方法或者数据透视分组统计groupby方法,具体根据自己的需求选择。
这一部分我们在后续 pandas学习笔记中也会详细介绍~
4.1.数据透视(pivot_table)
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
以下举例,简单介绍下其使用方式
"A": [4.2.分组统计(groupby)
DataFrame.groupby([]).agg(dict)
分组统计是pandas很大的模块,这里也不做过多的介绍,大家可以关注后续 pandas学习笔记系列。
简单举个例子:
In [13]: df
Out[13]:
A B C D E
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
In [14]: df.groupby('A')['D'].mean()
Out[14]:
A
bar 5.5
foo 2.2
Name: D, dtype: float64
#agg传字段参数更合适,可以和pivot_table统一化
In [15]: df.groupby(['A']).agg({'D':'mean','E':'sum'})
Out[15]:
D E
A
bar 5.5 32
foo 2.2 22
4.3.数据处理函数
由于行列以及计算字段和方法都是在可视化操作界面输入,我们需要对获取参数后进行字符串有关处理,从而组合成为最终的计算方式。
#获取输入的行、列、计算字段和方法将计算字段和计算方法进行组合成为字典
dic = {}
for i in range(len(fangfa)):
#需要注意,这里对于非重复计数,其组合形式有点特别,不能用引号
if fangfa[i] == 'pd.Series.nunique':
dic[ziduan[i]] = eval(fangfa[i])
else:
dic[ziduan[i]] = fangfa[i]
判断在可视化操作界面是否选中了数据透视操作,然后执行数据处理
if self.radioButton_toushi.isChecked():5.总结
以上主要三部分:
- 先创建好可视化操作界面,
- 然后编写功能槽函数和可视化操作界面功能进行关联,
- 最后就是打包源代码成可执行文件exe。
在进行每一步的操作时,最好都能加上边界条件处理,避免出现异常报错导致程序崩溃的情况。
每个槽函数其实都是利用到的python基础知识或者pandas基础数据处理知识,熟练掌握后便可很方便理解和实现。
下载代码
在【凹凸数据】公众号回复“0908”,可以领取源代码



















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









