





本文主要是采用Selenium来爬取CSDN的博文摘要,为后面对CSDN的热点技术、近几年专家发表的博客作数据分析。由于采用BeautifulSoup爬取该网站会报错"HTTPError: Forbidden",所以作者采用Selenium爬取。同时,在爬取过程中遇到了局部动态更新的问题,无法定位换页的问题,作者采用Firebug进行分析,也希望读者提出更好的方法。
代码下载地址:
一. CSDN博客网站分析及问题
本文主要爬取CSDN专家的博客,因为专家的论文水平相对高点,同时专栏较多,更具有代表性。网址:http://blog.csdn.net/experts.html
通过浏览器审查元素可以获取专家博客的URL链接,如下图所示:
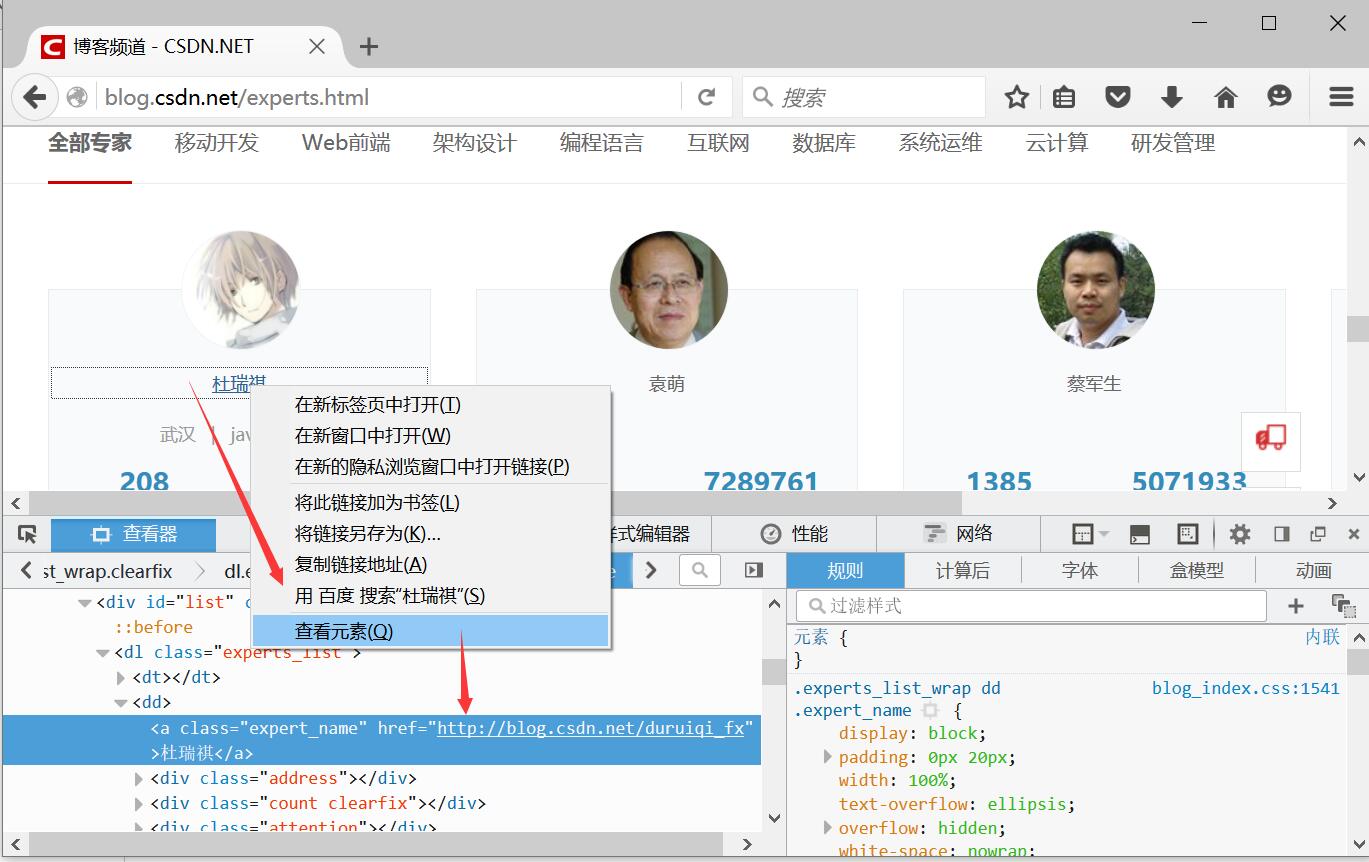
比如想访问我的所有博客,地址为:http://blog.csdn.net/eastmount/
通过分析,专家的信息位于节点下,通过下面的代码可以进行爬取:
urls = driver.find_elements_by_xpath("//div[@class=‘experts_list_wrap clearfix‘]/dl")
for u in urls:
print u.text然后需要执行的是翻页操作,同样的方法审查元素。但是难点是其页码是动态加载的,始终显示为:
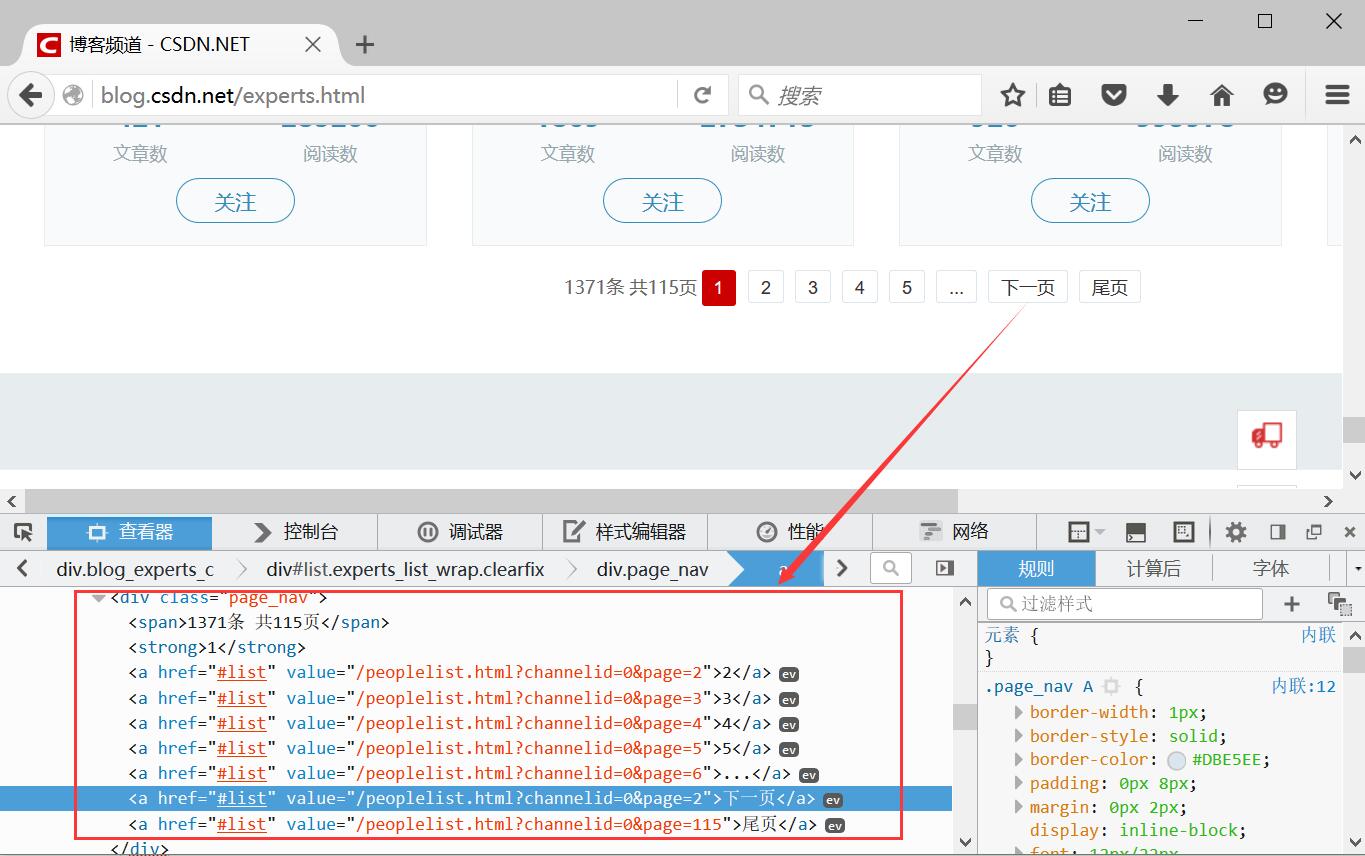
而且点击任何一页或下一页,顶部网址始终为:http://blog.csdn.net/experts.html#list
问题:
在写网络爬虫过程中,通常需要获取下一页,传统的方法是通过URL进行分析的,比如:
http://www.medlive.cn/pubmed/pubmed_search.do?q=protein&page=1
但是有的网站会出现两种情况。
1.一种是下拉菜单刷新新页面,这种参考下面这篇文章。
Python爬虫爬取动态页面思路+实例(二) - 孔天逸
核心代码,在线笔记记录:
# 下拉滚动条,使浏览器加载出动态加载的内容,可能像这样要拉很多次,中间要适当的延时(跟网速也有关系)。
# 如果说说内容都很长,就增大下拉的长度。
driver.execute_script("window.scrollBy(0,10000)")
time.sleep(3)
# 很多时候网页由多个或组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
driver.switch_to.frame("app_canvas_frame")
soup = BeautifulSoup(driver.page_source, ‘xml‘)
contents = soup.find_all(‘pre‘, {‘class‘: ‘content‘}) # 内容
times = soup.find_all(‘a‘, {‘class‘: ‘c_tx c_tx3 goDetail‘}) # 发表时间
for content, _time in zip(contents, times): # 这里_time的下划线是为了与time模块区分开
print content.get_text(), _time.get_text()
# 当已经到了尾页,“下一页”这个按钮就没有id了,可以结束了
if driver.page_source.find(‘pager_next_‘ + str(next_num)) == -1:
break
# 找到“下一页”的按钮
elem = driver.find_element_by_id(‘pager_next_‘ + str(next_num))
# 点击“下一页”
elem.click()
# 下一次的“下一页”的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()2.第二种是动态加载,URL使用不便却能够翻页,如CSDN。
同时下一页的位置是不断变换的,可能是第5个,点击后"首页"、"上一页"出来,又变成第7个。

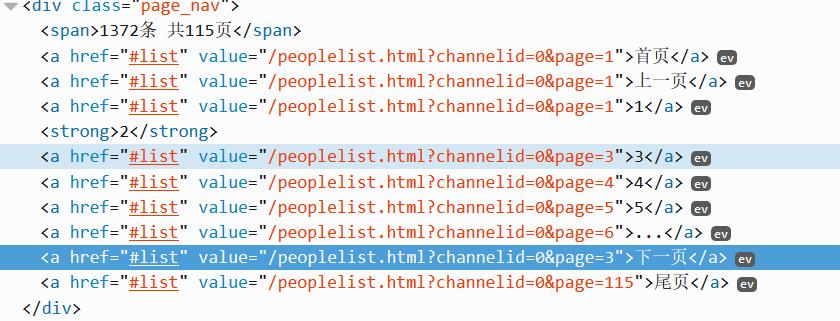
下图是跳转一次下页的Python代码,其中:
nextPage = driver.find_element_by_xpath("//div[@class=‘page_nav‘]/a[6]")
获取第6个,但是跳转后"下一页"的位置变换了。
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
import re
import os
#打开Firefox浏览器 设定等待加载时间 访问URL
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
driver.get("http://blog.csdn.net/experts.html")
#获取列表页数
print texts
m = re.findall(r‘(\w*[0-9]+)\w*‘,texts) #正则表达式寻找数字
print ‘页数:‘ + str(m[1])
return int(m[1])
#主函数
def main():
pageNum = getPage()
print pageNum
i=1
#循环获取标题和URL
while(i<=2): #pageNum即为总页码
urls = driver.find_elements_by_xpath("//div[@class=‘experts_list_wrap clearfix‘]/dl")
for u in urls:
print u.text
nextPage = driver.find_element_by_xpath("//div[@class=‘page_nav‘]/a[6]")
print nextPage.text
nextPage.click()
time.sleep(2)
i = i + 1
else:
print ‘Load Over‘
main()输出如下图所示:

二. Firebug审查元素
接下来采用Firebug分析网页数据,这个是非常有用撸站工具,后面写篇文章来介绍。
安装比较简单,直接通过Firefox浏览器下载插件进行安装,如下图所示:
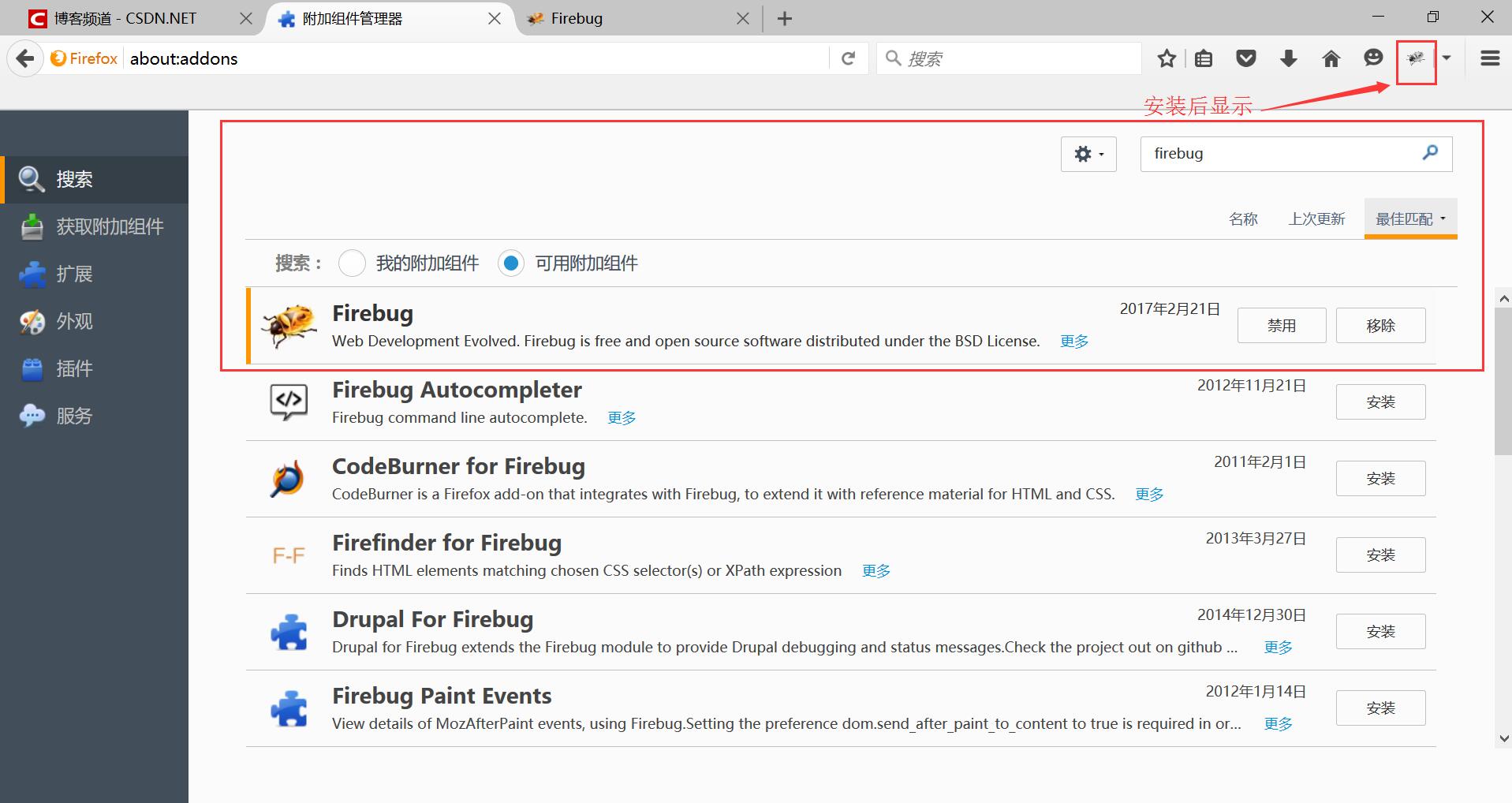
安装成功后,显示一个爬虫,再右键使用Firebug审查元素。
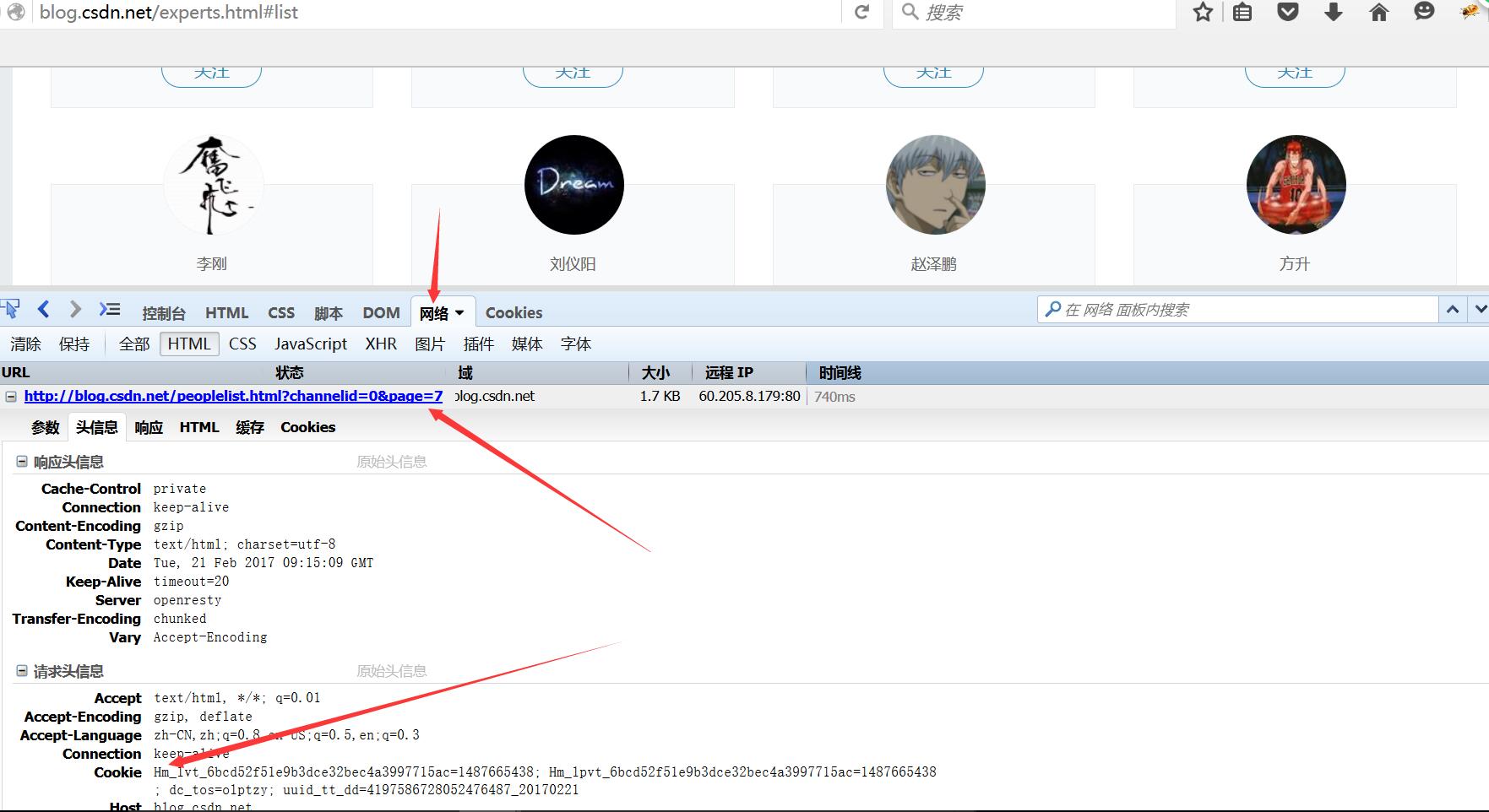
其实前面的代码也能发现,它是通过value进行传值局部跳转刷新的。
然后再使用Selenium爬取该网址的信息即可,再分析网站就比较方便了。
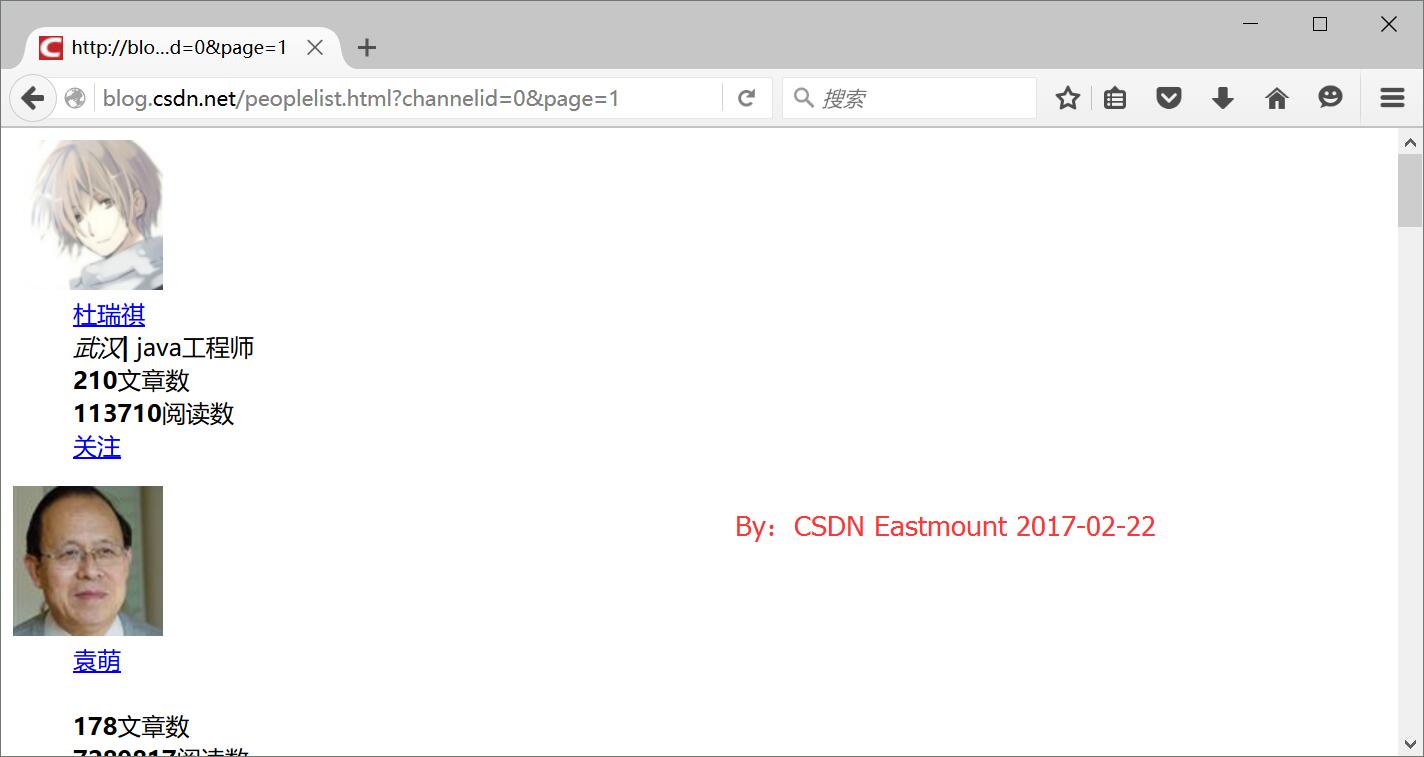
PS:肯定有更好的方法直接爬取的,而不是通过这种方法,但是这里主要想引入Firebug插件,后面有时间详细介绍。
三. Selenium爬取专家信息及URL
通过Firebug获取新的文章网址后,下面先获取专家的个人信息及博客地址URL。
分析如下图所示:
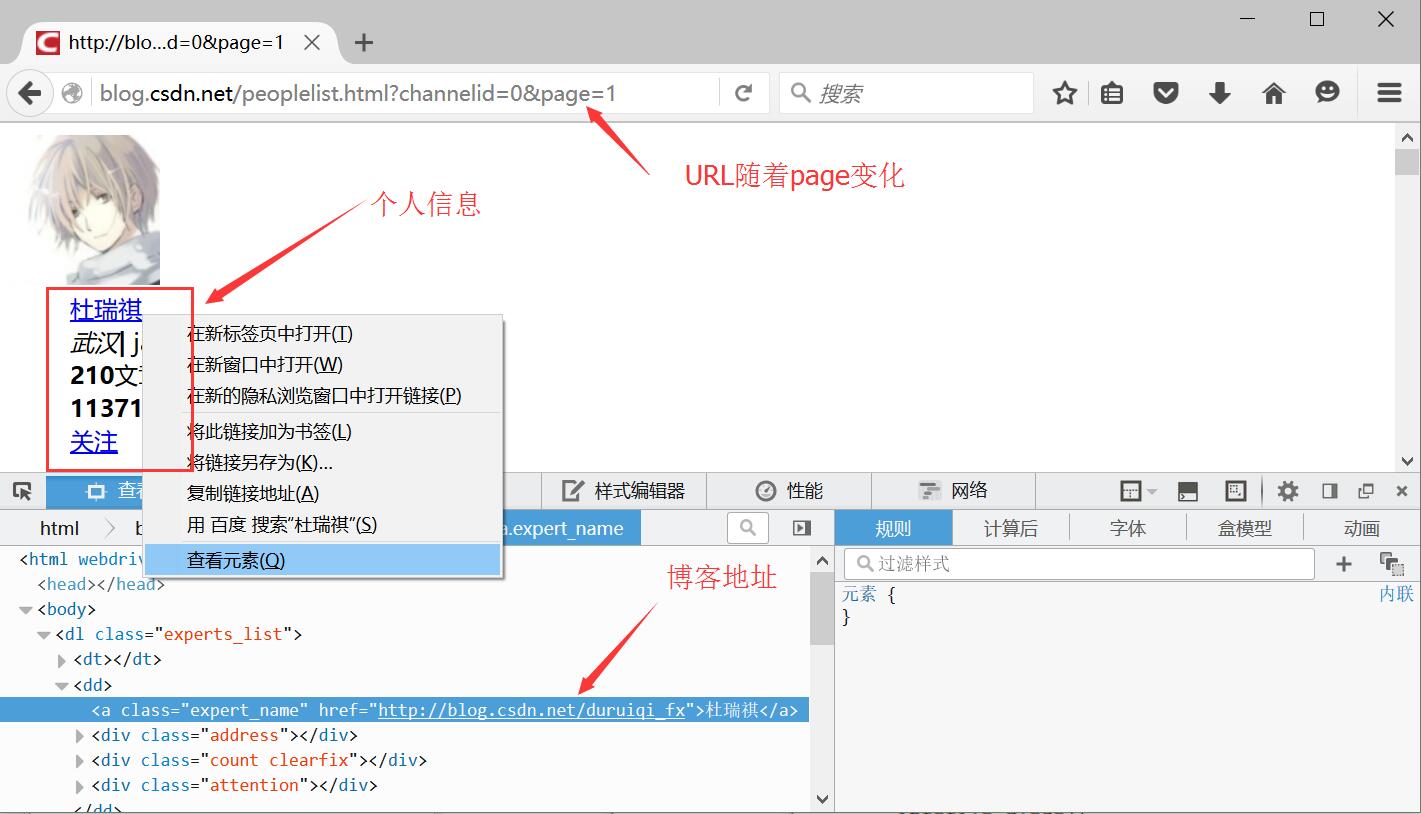
通过
详细代码如下,"01 csdn_blog_url.py"文件。
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
import re
import os
import codecs
#打开Firefox浏览器 设定等待加载时间
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#主函数
def main():
page = 1
allPage = 115
infofile = codecs.open("Blog_Name.txt", ‘a‘, ‘utf-8‘)
urlfile = codecs.open("Blog_Url.txt", ‘a‘, ‘utf-8‘)
#循环获取标题和URL
while(page <= 2): #只爬取2页,正常应该是allPage
url = "http://blog.csdn.net/peoplelist.html?channelid=0&page=" + str(page)
print url
driver.get(url)
#获取URL
name_urls = driver.find_elements_by_xpath("//dl[@class=‘experts_list‘]/dt/a")
for url in name_urls:
u = url.get_attribute("href")
print u
urlfile.write(u + "\r\n")
#保存信息
info = driver.find_elements_by_xpath("//dl[@class=‘experts_list‘]/dd")
for u in info:
content = u.text
content = content.replace(‘\n‘,‘ ‘) #换行替换成空格 写入文件方便
print content
infofile.write(content + "\r\n")
page = page + 1
infofile.write("\r\n")
else:
infofile.close()
urlfile.close()
print ‘Load Over‘
main()输出如下,并且写入文件,这里只爬取了2页的信息。Blog_Name.txt存储个人信息。

Blog_Url.txt存储专家博主的URL。
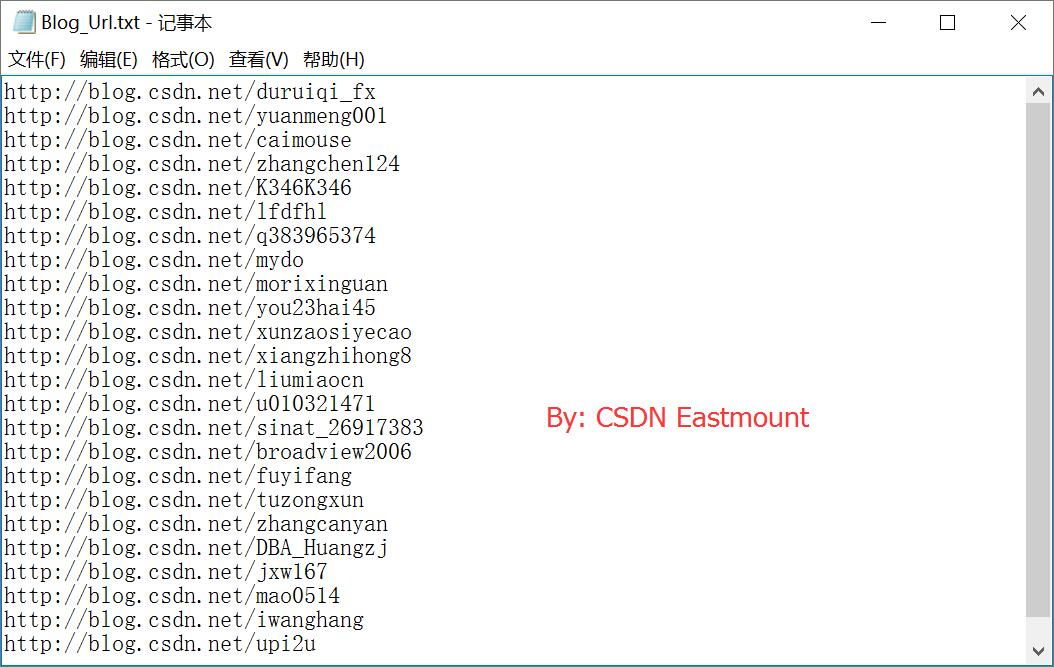
四. Selenium爬取博文信息
最后爬取每个博主的博客信息,这里也需要分析翻页,但是博客翻页采用的是URL连接,比较方便。如:http://blog.csdn.net/Eastmount/article/list/2
故只需要 :1.获取总页码;2.爬取每页信息;3.URL设置进行循环翻页;4.再爬取。
也可以采用点击"下页"跳转,没有"下页"停止跳转,爬虫结束,接着爬取下一个博主。
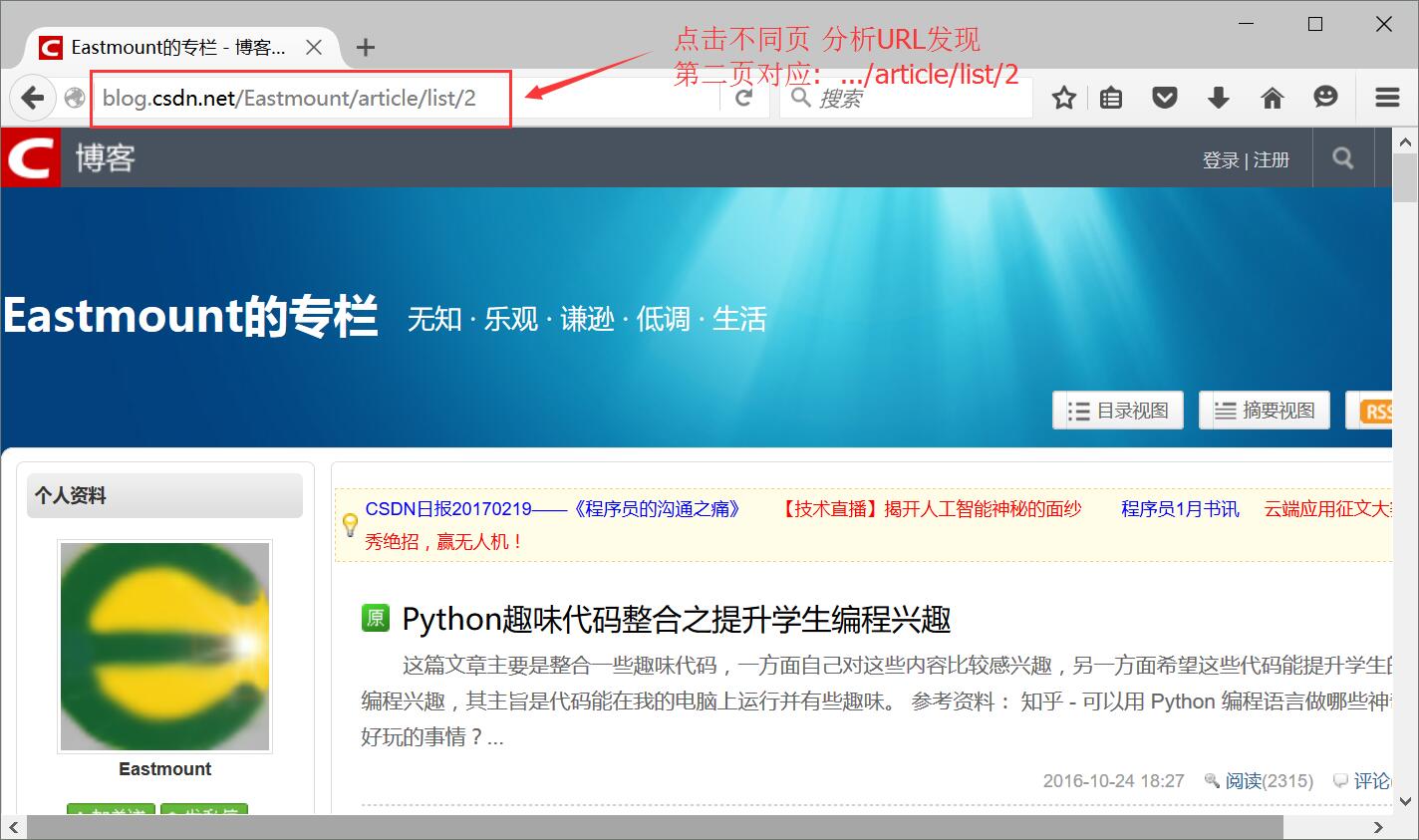
然后审查元素分析每个博客页面,如果采用BeautifulSoup爬取会报错"Forbidden"。
发现每篇文章都是由一个
组成,如下所示,只需要定位到该位置即可。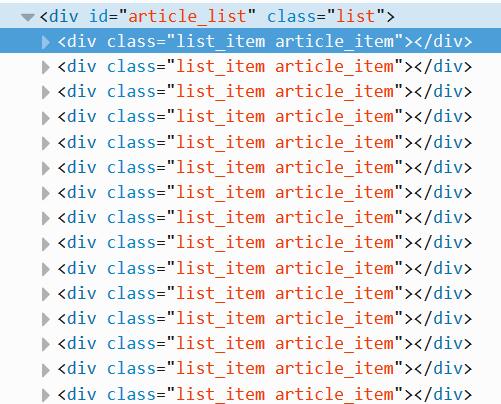
这里定位到该位置即可爬取,有时需要分别定位标题、摘要、时间,也是一样的方法。
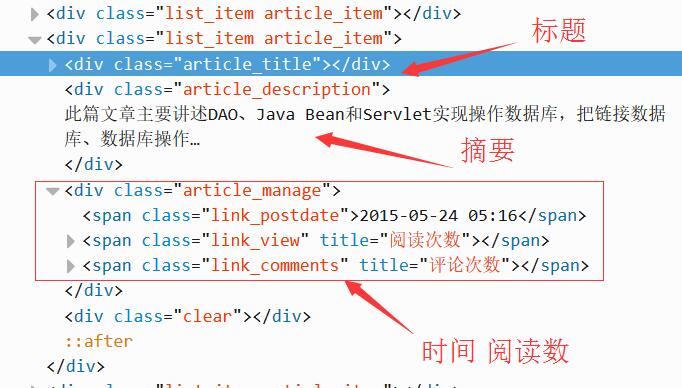
下面是详细的代码,主要爬取两个人的详细信息。# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
import re
import time
import os
import codecs
#打开Firefox浏览器 设定等待加载时间
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#获取每个博主的博客页面低端总页码
def getPage():
number = 0
texts = driver.find_element_by_xpath("//div[@class=‘pagelist‘]").text
print texts
m = re.findall(r‘(\w*[0-9]+)\w*‘,texts) #正则表达式寻找数字
print ‘页数:‘ + str(m[1])
return int(m[1])
#主函数
def main():
#获取txt文件总行数
count = len(open("Blog_URL.txt",‘rU‘).readlines())
print count
n = 0
urlfile = open("Blog_URL.txt",‘r‘)
content = codecs.open("Blog_Content.txt", ‘a‘, ‘utf-8‘)
#循环获取每个博主的文章摘信息
while n < 2: #这里爬取2个人博客信息,正常情况count个博主信息
url = urlfile.readline()
url = url.strip("\n")
print url
driver.get(url)
#获取总页码
allPage = getPage()
print u‘页码总数为:‘, allPage
time.sleep(2)
m = 1 #第1页
while m <= 2:
ur = url + "/article/list/" + str(m)
print ur
driver.get(ur)
article_title = driver.find_elements_by_xpath("//div[@class=‘list_item article_item‘]")
for title in article_title:
con = title.text
print con + ‘\n‘
con = con.replace(‘\n‘,‘\r\n‘) #换行替换成空格 写入文件方便
content.write(con + "\r\n")
m = m + 1
else:
content.write("\r\n")
print u‘爬取下一个博主文章\n‘
n = n + 1
else:
content.close()
urlfile.close()
print ‘Load Over‘
main()爬取的结果如下图所示:
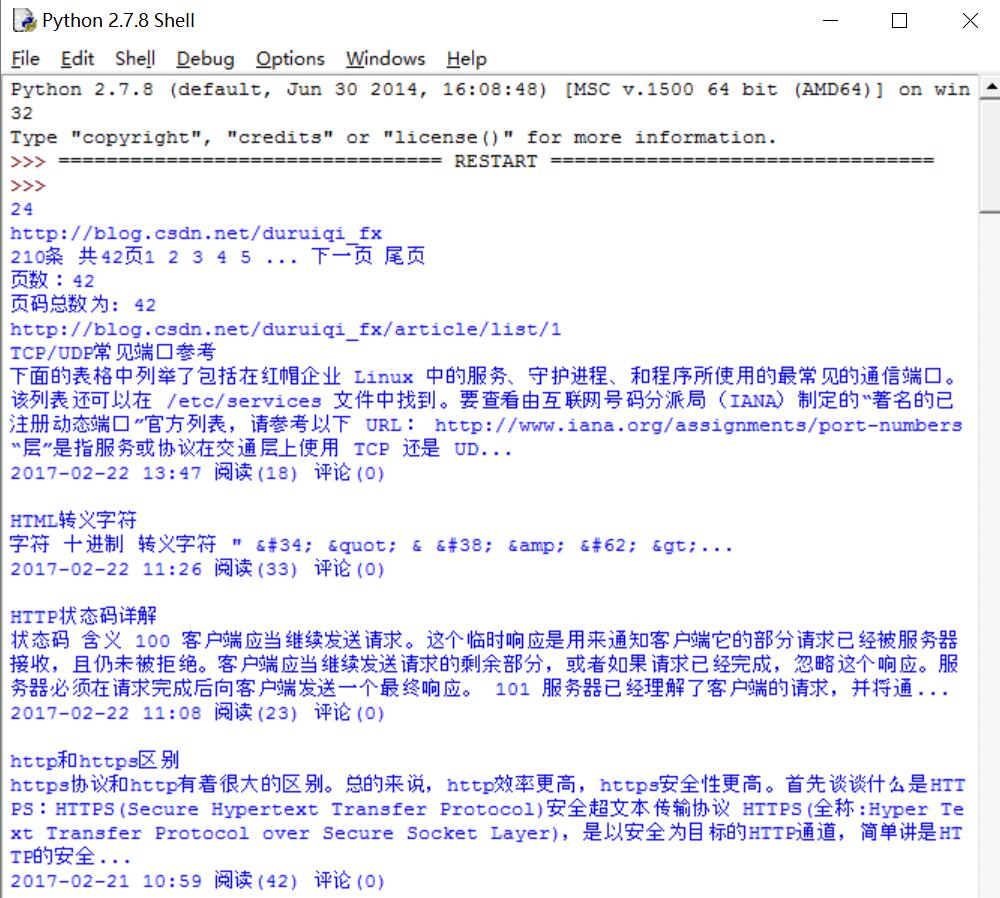
最后希望文章对你有所帮助,如果文章中存在错误或不足之处,还请海涵~
新的一学期开始了,改掉很多毛病,提高效率,提升科研,认真教学,娜美人生。
(By:Eastmount 2017-02-22 下午2点半http://blog.csdn.net/eastmount/)
原文地址:http://blog.csdn.net/eastmount/article/details/56479962















 2653
2653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









