





在对某在线视频网站抓包分析时,发现该站点采用m3u8格式进行视频文件传输。
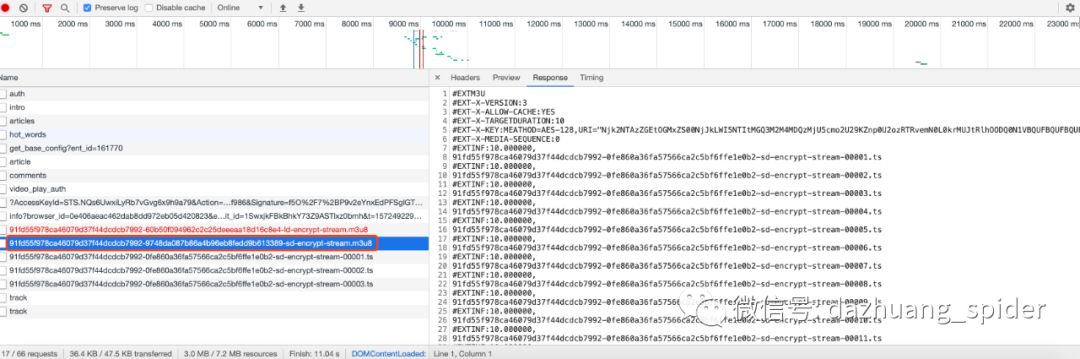
通过m3u8的response可以看到,m3u8格式文件由很多段ts文件组成。那么什么是m3u8,什么是ts呢?
M3U8是Unicode版本的M3U,用UTF-8编码。"M3U" 和 "M3U8" 文件都是苹果公司使用的 HTTP Live Streaming(HLS) 协议格式的基础,这种协议格式可以在 iPhone 和 Macbook 等设备播放。m3u8文件其实是 HTTP Live Streaming(缩写为 HLS) 协议的部分内容,而 HLS 是一个由苹果公司提出的基于 HTTP 的流媒体网络传输协议。
HLS 的工作原理是把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。
在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U (m3u8) playlist文件,用于寻找可用的媒体流。HLS 只请求基本的 HTTP 报文,与实时传输协议(RTP)不同,HLS 可以穿过任何允许 HTTP 数据通过的防火墙或者代理服务器。它也很容易使用内容分发网络CDN来传输媒体流。
我们来看一下,实际下载下来的m3u8文件到底长什么样。
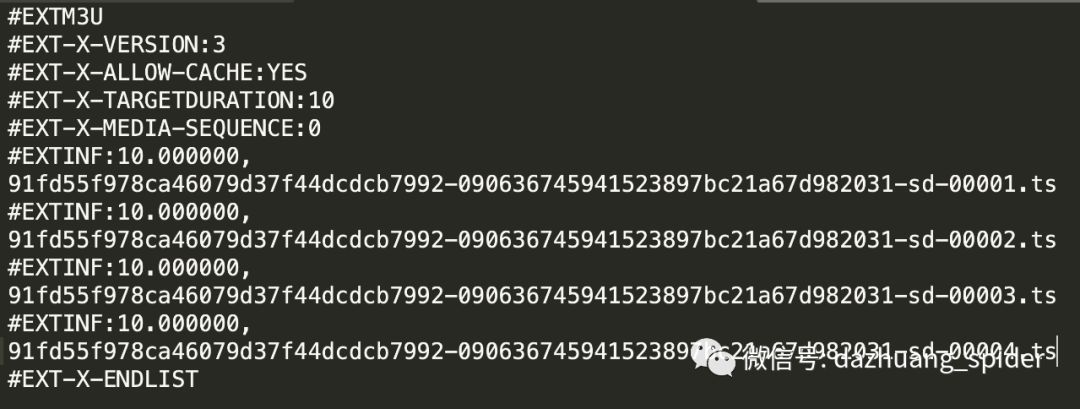
下面我们来分别说明一下相关的几个字段:
EXTM3U:这个是M3U8文件必须包含的标签,并且必须在文件的第一行,所有的M3U8文件中必须包含这个标签。
EXT-X-VERSION:M3U8文件的版本,常见的是3(目前最高版本应该是7)。
EXT-X-TARGETDURATION:该标签指定了媒体文件持续时间的最大值,播放文件列表中的媒体文件在EXTINF标签中定义的持续时间必须小于或者等于该标签指定的持续时间。该标签在播放列表文件中必须出现一次。
EXT-X-MEDIA-SEQUENCE:M3U8直播是的直播切换序列,当播放打开M3U8时,以这个标签的值作为参考,播放对应的序列号的切片。
EXTINF:EXTINF为M3U8列表中每一个分片的duration,如上面例子输出信息中的第一片的duration为10秒。在EXTINF标签中,除了duration值,还可以包含可选的描述信息,主要为标注切片信息,使用逗号分隔开。
那么这些ts文件是用来做什么的呢?
TS的全称则是Transport Stream。TS则主要应用于实时传送的节目,比如实时广播的电视节目。TS格式的特点就是要求从视频流的任一片段开始都是可以独立解码的。
大多数视频网站都采用渐进式下载,这意味着视频会下载到我的设备上。视频一般采用流式传输,这意味着我们不只是下载了1个文件,而是下载了很多小包(本文指的是.ts传输流切片文件)。比如我分析该视频网站时,看到他们对视频进行了分流加载,而且还是一个个的.ts格式传输流文件,给视频文件进行加密的同时又是一种性能优化手段,打开浏览器的开发者工具就可以清楚地看到它们在异步加载。

回到文章的开始,面对这种类型的视频文件,我们该如何采集呢,这里我们需要介绍一下ffmpeg。
什么是ffmpeg:
FFmpeg的名称来自MPEG视频编码标准,前面的“FF”代表“Fast Forward”,FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。可以轻易地实现多种视频格式之间的相互转换。
包括如下几个部分:
libavformat:用于各种音视频封装格式的生成和解析,包括获取解码所需信息以生成解码上下文结构和读取音视频帧等功能,包含demuxers和muxer库。libavcodec:用于各种类型声音/图像编解码。libavutil:包含一些公共的工具函数。libswscale:用于视频场景比例缩放、色彩映射转换。libpostproc:用于后期效果处理。ffmpeg:是一个命令行工具,用来对视频文件转换格式,也支持对电视卡实时编码。ffsever:是一个HTTP多媒体实时广播流服务器,支持时光平移。ffplay:是一个简单的播放器,使用ffmpeg 库解析和解码,通过SDL显示。ffprobe:收集多媒体文件或流的信息,并以人和机器可读的方式输出。通俗的,粗暴的讲,ffmpeg就是用来对视频进行格式转换的,本文将通过ffmpeg对m3u8格式视频文件转换为mp4。
首先安装ffmpeg工具,并将ffmpeg工具加入环境变量。
ffmpeg工具官网:
http://ffmpeg.zeranoe.com/builds/可以选择相应版本进行下载安装。
我们可以通过命令进行转换:
ffmpeg -i "m3u8地址" "保存的文件名.mp4"我们可以构造请求并对返回数据进行解析:
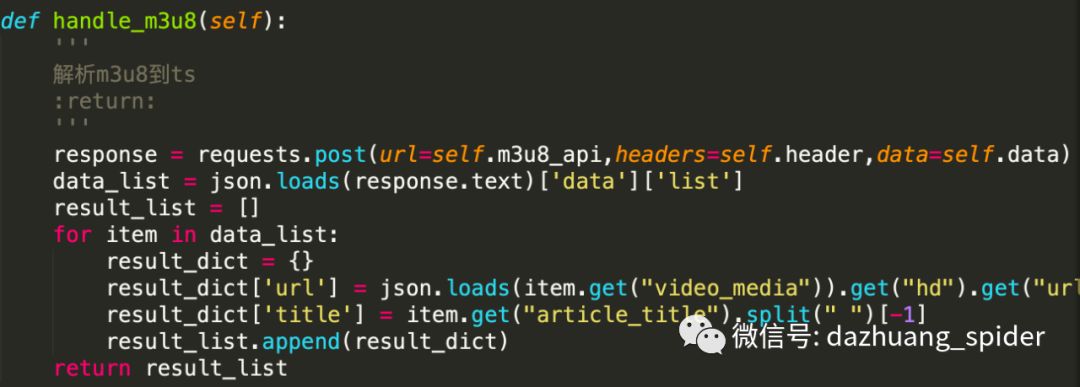
并通过os模块调用ffmpeg对m3u8文件转换为mp4

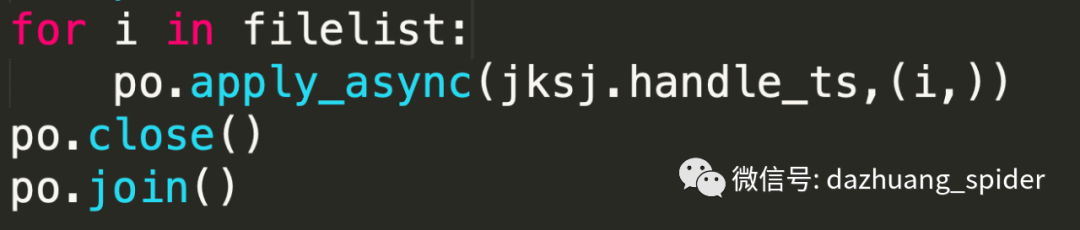
为了加快抓取速度,我们可以调用python的进程池,并发抓取
原文参考:
视频文件M3U8和TS格式切片,讨论一下?https://juejin.im/post/5ced18e0f265da1b763881













 1784
1784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









