





之前学过的都忘了,也没好好做过总结,现在总结一下。
时间复杂度和空间复杂度的概念:
1、空间复杂度:
是程序运行所以需要的额外消耗存储空间,一般的递归算法就要有o(n)的空间复杂度了,简单说就是递归集算时通常是反复调用同一个方法,递归n次,就需要n个空间。
2、时间复杂度:
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f (n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
按数量级递增排列,常见的时间复杂度有:
常数阶O(1),对数阶O(log2n),线性阶O(n),
线性对数阶O(nlog2n),平方阶O(n2),立方阶O(n3),...,
目前我已经学过的排序算法包括
1、二次排序:
1、插入排序
2、选择排序
2、递归排序:
1、归并排序
2、快速排序
3、希尔排序
4、冒泡排序
一、冒泡排序
原理:冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。
评价:是效率最低的一种排序算法。
时间复杂度:最差和平均均为O(n2)
稳定性:由于相等的元素不需要交换,所以比较稳定
代码:
C实现:
#include#include#include
int msort(int array[],intn)
{int exchange = 0;inti,j;
i=j=0;for(i=0;i
{
j=n-1;while(j >i)
{int temp=0;//printf("%d",array[j]);
if (array[j]
{
temp=array[j];
printf("%d",temp);
array[j]= array[j-1];
array[j-1] =temp;
exchange= 1;
}
j=j-1;
}if (exchange == 0)break;
}for(i=0;i
printf("%d\n",array[i]);
}int main(void)
{int SIZE=9;int array[9]={5,2,8,2,7,9,10,20,15};int i=0;for(i=0;i
printf("%d\n",array[i]);
msort(array,SIZE);return 0;
}
Python实现:
importtimeitdefmsort(array):
exchange=Falsefor i inxrange(len(array)):
j=len(array)-1
while(j>i):if array[j]
array[j-1],arra[j]=array[j],array[j-1]
exchange=True
j=j-1
if exchange!=True:break
printarraydefmain():
array=list(range(0,10000))
msort(array)if __name__=="__main__":
t=timeit.Timer("main()",'from __main__ import main')print t.timeit(1)
二、选择排序
原理:简单点说就是从数组第一个位置开始,给每个位置在剩余的元素中都找到最小的值放上去。
评价:由于每次都要寻找最值,所以选择排序效率不高
时间复杂度:最坏,最优和平均时间复杂度都是O(n2).
稳定性:由于交换,可能导致相等元素的前后顺序发生变化,所以不稳定。比如举个例子,序列5 8 5 2 9, 我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了
代码:
C实现:
#include#include
void ssort(int array[],intn)
{inti,j;intsmall;for(i=0;i
{
small=i;for(j=i+1;j
{if (array[j]
small=j;
}int temp=0;if (small!=i)
{
temp=array[i];
array[i]=array[small];
array[small]=temp;
}
}for(i=0;i
printf("%d",array[i]);
}int main(void)
{int array[7]={7,3,1,6,4,2,8};
ssort(array,7);
}
Python实现:
defssort(array):for i inxrange(0,len(array)):
j=i+1small=iwhile j
small=j;
j+=1
if i!=small:
array[small],array[i]=array[i],array[small]returnarray
array=[2,62,7,3,8,1,1]print 'any',all(array)print ssort(array)
三、插入排序:
原理:为当前有序序列插入元素,插入到正确的位置。当然,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开 始,也就是想要插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面,否则一直往前找直到找到它该插入的位置。
评价:对于比较有序的数组列表来说,效率是线性的,相当快。
稳定度:如果碰见一个和插入元素相 等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳 定的。
时间复杂度:最差的情况是逆序的,需要O(n2),平均也是O(n2),最优的是线性的。
C实现
#include#include
int isort(int array[],intn)
{int i=0;intj;for(i=1;i
{int temp=array[i];for(j=i;j>0&&array[j-1]>temp;j--)
{
array[j]=array[j-1];
}
array[j]=temp;
}for(i=0;i<7;i++)
{
printf("%d",array[i]);
}
}int main(void)
{int array[7]={8,2,7,1,9,3,0};int result[7];
isort(array,7);
}
Python实现:
def isort(array):for i in xrange(1,len(array)):
temp=array[i]
j=iwhile j>0 and array[j-1]>temp:
array[j]=array[j-1]
j=j-1array[j]=tempreturnarray
print isort([6,3,2,1,8,4])
四、归并排序
原理:采用分治法,将数组分成两部分元素,如此下去,知道只剩下一个元素,采用递归调用。两部分数组比较,需要一个临时数组,存储有序值。
评价:算法很快,但是需要分配临时数组,耗费内存。
稳定度:由于在比较时,两个相等值可以保证位置不变,所以是稳定的。
时间复杂度:最优,最差和平均都是O(nlogn)
代码:
Python:
defmerge(L1,L2):
sorted_array=[]while L1 andL2:if L1[0] <=L2[0]:
sorted_array.append(L1.pop(0))else:
sorted_array.append(L2.pop(0))ifL1:
sorted_array.extend(L1)ifL2:
sorted_array.extend(L2)returnsorted_arraydefmersort(array):if len(array)<=1:returnarray
center=int(len(array)/2)returnmerge(mersort(array[:center]),mersort(array[center:]))if __name__=="__main__":
array=[8,20,15,4,6,3,7,2,1,9]printmersort(array)
五、快速排序
原理:和归并排序的思想是相同的,都采用分治法,但是不同的是需要选择一个基准数,根据基准数把数组分为两段,比基准数小的在左边,比基准数大的在右边。左右两边再分别采用这种方法,如此递归调用下去,知道只剩下一个元素。
评价:关键是找到基准数,基准数一般是随机选择三个值,选择中间值,或者选择数组第一个元素,但是如果第一个元素是最小的或最大的就糟糕了。
稳定性:不稳定。比如序列为5 3 3 4 3 8 9 10 11, 现在基准元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法
时间复杂度:最坏的情况是O(n2),最好喝平均都是O(nlogn)
python实现:
importrandomdefpartition(array,left,right):if right-left==1:if array[left]>array[right]:
array[left],array[right]=array[right],array[left]returnNone
base=array[left]
big_index,small_index= left+1,rightwhile big_index
big_index+= 1
while array[small_index] >= base and small_index >left:
small_index-=1
if big_index
array[big_index],array[small_index]=array[small_index],array[big_index]
array[left],array[small_index]=array[small_index],basereturnsmall_indexdefqsort(array,left,right):if right >left:
mid=partition(array,left,right)if mid is notNone:
qsort(array,left,mid)
qsort(array,mid+1,right)if __name__=="__main__":
array=[]for i in xrange(0,50):
array.append(random.randint(0,30))
qsort(array,0,(len(array)-1))printarray
其实快速排对大数组很有效率,但如果小数组,插入排序比较好,经验表明,元素数目小于15时,可以改为插入排序
Python:
importrandomfrom insert.isort import importisortdefpartition(array,left,right):if right-left==1:if array[left]>array[right]:
array[left],array[right]=array[right],array[left]returnNone
base=array[left]
big_index,small_index= left+1,rightwhile big_index
big_index+= 1
while array[small_index] >= base and small_index >left:
small_index-=1
if big_index
array[big_index],array[small_index]=array[small_index],array[big_index]
array[left],array[small_index]=array[small_index],basereturnsmall_indexdefqsort(array,left,right):if right-left>15:
mid=partition(array,left,right)if mid is notNone:
qsort(array,left,mid)
qsort(array,mid+1,right)else:
isort(array)if __name__=="__main__":
array=[]for i in xrange(0,50):
array.append(random.randint(0,30))
qsort(array,0,(len(array)-1))print array
六、希尔排序
原理:采用不同的步长,分别进行插入排序,直到步长为1.原理解释最直观的如下:
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
最后以1步长进行排序(此时就是简单的插入排序了)。
评价:选择步长是关键,选择好了,比较快,一般步长初始选择数组长度除以2,一直除以2,一直到步长为1.
稳定度:不稳定,不同部分数组排序,很有可能打破相等元素的顺序。
时间复杂度:(摘抄):
需要大量的辅助空间,和归并排序一样容易实现。希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间复杂度与增量序列的选取有关,例如希尔增量时间复杂度为O(n²),而Hibbard增量的希尔排序的时间复杂度为O(
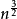
),但是现今仍然没有人能找出希尔排序的精确下界。希尔排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(
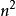
)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要的个数很少,但数据项的距离很长。当n值减小时每一趟需要和动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使希尔排序效率比插入排序高很多。
Python实现:
defshsort(array):
interval= len(array)/2
while interval >= 1:
i=intervalwhile i
j=i-interval
temp=array[i]while j >=0 and array[j] >temp:
array[j+interval]=array[j]
j-=interval
array[j+interval]=temp
i+=1interval/=2
returnarrayif __name__=="__main__":
array=[3,6,9,5,7,4,8,2,1]print shsort(array)
七、基数排序
原理:又名桶子排序,有10个桶。首先把个位数按照顺序放到桶子中,个位数相同的就放在同一个桶子里;然后再按照十位数的大小顺序放到桶子里,依次类推,最后得到结果。
评价:基数排序的时间复杂度是 O(k·n),其中n是排序元素个数,k是数字位数。注意这不是说这个时间复杂度一定优于O(n·log(n)),k的大小取决于数字位的选择(比如比特位数),和待排序数据所属数据类型的全集的大小;k决定了进行多少轮处理,而n是每轮处理的操作数目。
以排序n个不同整数来举例,假定这些整数以B为底,这样每位数都有B个不同的数字,k = logB(N),N是待排序数据类型全集的势。虽然有B个不同的数字,需要B个不同的桶,但在每一轮处理中,判断每个待排序数据项只需要一次计算确定对应数位的值,因此在每一轮处理的时候都需要平均n 次操作来把整数放到合适的桶中去,所以就有:
k 约等于 logB(N)
所以,基数排序的平均时间T就是:
T ~= logB(N)·n
其中前一项是一个与输入数据无关的常数,当然该项不一定小于logn
稳定度:很稳定.基数排序基于分别排序,分别收集,所以其是稳定的排序算法
时间复杂度:O(k·n)
Python实现:
def rsort(array):
length=len(str(max(array)))
locat=0while locat
bucket=[]for n in xrange(0,10):
bucket.append([])for i inarray:
index=i%10 if not locat else i/(locat*10)%10bucket[index].append(i)
array=[]for i inbucket:
array.extend(i)
locat+= 1
returnarrayprint rsort([35,8611,84,36,745,154,39,4,3])
八、堆排序
原理:构成堆,将末端值与根节点交换
稳定度:不稳定
时间复杂度:nlogn
Python实现:
defmake_heap(array,start,end):
lchild= lambda x:2*x+1rchild= lambda x:2*x+2root=startwhileTrue:
left=lchild(root)if left >end:breakright=rchild(root)
child= right if right <= end and array[left]
else:
array[root],array[child]=array[child],array[root]
root=childdeflist_heap(array):for i in xrange(len(array)/2,-1,-1):
make_heap(array,i,len(array)-1)defhsort(array):
list_heap(array)for end in xrange(len(array)-1,0,-1):
array[0],array[end]=array[end],array[0]
make_heap(array,0,end-1)return array
if __name__=="__main__":
array=[3,7,1,8,230,56,100,34,12,40,9,54,67,24,26]
print hsort(array)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









