





python戏说NBA
python戏说NBA,是一个用python来戏说NBA大事的系列栏目,这里将结合python开发技术,融合现今发生的NBA大事,做一些有趣的实验,让我们一起看热闹的同时,也能学到一些技术。分析结果仅供娱乐,缺乏专业论点支撑~
注意!!!作者只是个看热闹的球迷,并非篮球专业人士,再强调一遍,论证结果不够严谨,重要的是,大家可以通过这些有趣的研究带动自己学习技术的兴趣!!!
先免责,再写,哈哈哈,省的被喷的怀疑人生。

直戳主题
本章没有什么球星之间的讨论、对比、互相伤害,你们可以先放下刀听我说下主题。很简单,今天突然想看看历届得分王,谁的出手最多,谁的得分最高之类的数据,然后就去扒拉数据。嗯,很块就找到了。突然想到,我已经三天没更新文章了,不能任自己这么装咸鱼。好吧,虽然没什么可争论的点,但还是写吧,不然今晚睡不着了,老想着没更新。所以,我马上来一个鲤鱼打挺,赶紧开动。

鲤鱼打挺
今天的主题是,看一下最近20年来的得分王,各项数据之最。
嘈点
写这篇文章的时候我已经想到几个开喷的点了,我先开:
- 搞这么复杂,这点数据我不会用excel更快吗?
- 你分析的这些数据有意义吗?这也写。
- 不同时代的数据含量不同,这么对比没意义啊。很多朋友认为以前防守强度大,所以现在的数据要打骨折。
- 你的代码写这样,还拿出来。这里其实可以这么写。
- ...
更多的欢迎大家去挖掘,作为一个厚脸皮的人,我就是不怕,你~们~喷~
温馨提示
平时大家上班生活都不容易,刷微博啊刷新闻啥的都是为了放松一下,我理解大家。所以如果看到这里对我的主题还感兴趣的,比如你也想看看得分王中谁出手最多、谁罚球最多、谁三分最准等等,可以直接跳到分析结果去看。如果你对编程有兴趣,不嫌弃枯燥的,可以接着往下看,顺便提示一下,文末有源码下载连接。并且由于我再写这段代码的时候,其实心也是比较烦闷的,注释啥的也没有很多,代码也写得比较简单,没有优化。有心的读者可以自己下来自己改一下。
我这些文章的目的不是为了讨论NBA,也不是为了显摆代码。我只是希望通过实际生活中感兴趣的事情,融入一点开发技术,大家学起来就没这么苦闷。
确立提取方案
首先要做的第一步是收集历届得分王的数据,很巧,有网站帮我们做好统计了,但是它缺少导出excel表的功能,其实如果我们只是看数据,可以通过网站肉眼观察。但既然为了学点技术,我们就不嫌弃麻烦,把这些数据搞下来,自己排序输出。这样观察的方便些。
第一步:打开得分王数据的网站,网址是:http://stat-nba.com/award/item14.html
首先我们观察一下该网站,打开网址后,是这样的一个页面:
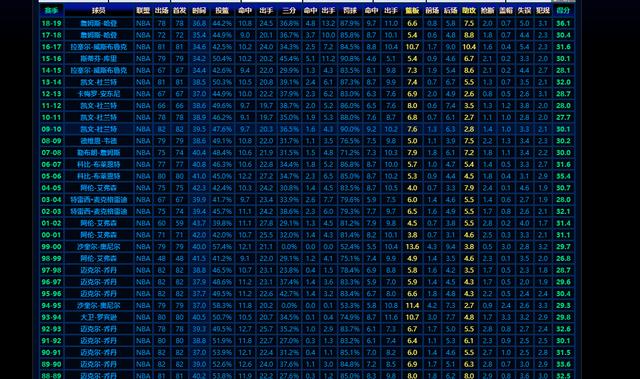
网站已经列出了历届得分王的数据,比如我们要看谁的篮板最高,我们可以看到篮板那一列,逐行进行比较得出。其它的数据项类似,但我嫌弃这样太累了,不如试着把数据搞下来,排序输出。
第二步:确立数据项。准备数据之前,我们应该知道我们要什么数据,就上图而言,我们待取的数据项分别是球员名字、出场次数、场均出场时间、投篮命中率、场均出手、三分命中率、三分出手、罚球命中率、场均罚球、场均篮板、场均助攻、场均抢断、场均得分。怎么确定你需要取哪项数据呢,如果你想看得分王中谁的篮板最高,那你就取篮板那一列数据,其它的类推。
第三步:确认数据范围。首先观察网站的整体结构,我们发现该页面有两个表格,第一个是NBA的数据,第二个是ABA的数据。因此,我们确认只需要第一个表格就行了,因为我们观察的是近二十年的得分王数据。
第四步:确认提取标签。首先要做的是,我们要确认提取哪项数据,这里以提取出场次数为例。将鼠标移动到出场该列的任一位球员的出场次数上(以13-14赛季凯文杜兰特为例),鼠标右击弹出菜单之后,选择检查后左击鼠标。会弹出如下页面。
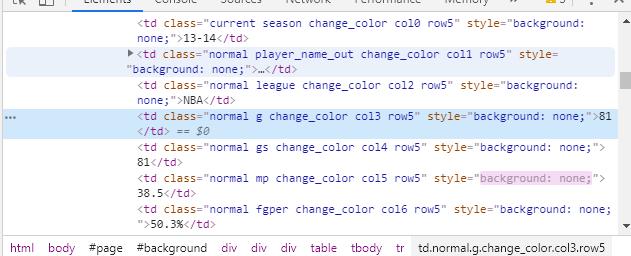
上述页面弹出的html标签中,可以看到有很多个td标签,那怎么选择我们要的标签呢。从页面可以看到13-14赛季杜兰特的出场次数是81场,我们找到有81的td标签,这个标签就是我们要的。为了唯一提取这个标签,我们需要观察这个标签跟其他标签有什么不同。通过观察可以得出,出场次数这个标签有一个g的class,这是其它td没有的,因此可以通过这个class来唯一获取这个数据。其它数据项类似,大家自己练习。
至此,我们的数据提取方案就确立了。
准备数据
既然已经确立好了提取方案,那么就可以开始提取数据了。这里用到python的requests、bs4进行抓取数据,所以大家要先安装这两个库。
抓取步骤是这样的:访问网页-->获取网站返回内容-->转往网页位beatifulsoup对象-->根据前面的提取方案提取数据-->将数据存储到变量中去。
代码如下:
tags = {"player_name_out": "球员名称















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









