



 本文介绍了索引查找的基本概念,包括分级查找、索引存储和索引查找算法的详细步骤。同时,文章还讨论了分块查找,这是一种介于顺序查找和二分查找之间的查找方法,适用于块间有序、块内无序的数组。通过C语言实现,展示了索引查找和分块查找的具体算法,包括如何查找索引项和在子表中搜索关键字的过程。
本文介绍了索引查找的基本概念,包括分级查找、索引存储和索引查找算法的详细步骤。同时,文章还讨论了分块查找,这是一种介于顺序查找和二分查找之间的查找方法,适用于块间有序、块内无序的数组。通过C语言实现,展示了索引查找和分块查找的具体算法,包括如何查找索引项和在子表中搜索关键字的过程。
1、基本概念
索引查找又称分级查找。
索引存储的基本思想是:首先把一个集合或线性表(他们对应为主表)按照一定的函数关系或条件划分成若干个逻辑上的子表,为每个子表分别建立一个索引项,由所有
这些索引项构成主表的一个索引表,然后,可采用顺序或链接的方式来存储索引表和每个子表。
索引表的类型可定义如下:
struct IndexItem
{
IndexKeyType index;//IndexKeyType为事先定义的索引值类型
int start; //子表中第一个元素所在的下标位置
int length; //子表的长度域
};
typedef struct IndexItem indexlist[ILMSize];//ILMSize为事先定义的整型常量,大于等于索引项数m
主表的类型可定义如下:
typedef struct ElemType mainlist[MaxSize];//MaxSize为事先定义的整型常量,大于等于主表中元素的个数n
在索引表中的每个索引项对应多条记录,则称为稀疏索引,若每个索引项唯一对应一条记录,则称为稠密索引。
2、索引查找算法
过程:
首先根据给定的索引值K1,在索引表上查找出索引值等于K1的索引项,以确定对应子表在主表中的开始位置和长度,然后再根据给定的关键字K2,在对应的子表中查找出
关键字等于K2的元素。
设数组A是具有mainlist类型的一个主表,数组B是具有indexlist类型的在主表A上建立的一个索引表,m为索引表B的实际长度,即所含的索引项的个数,K1和K2分别为给定
带查找的索引值和关键字,并假定每个子表采用顺序存储,则索引查找算法为:
int Indsch(mainlist A, indexlist B, int m, IndexKeyType K1, KeyType K2)
{//利用主表A和大小为 m 的索引表B索引查找索引值为K1,关键字为K2的记录
//返回该记录在主表中的下标位置,若查找失败则返回-1
int i, j;
for (i = 0; i < m; i++)
if (K1 == B[i].index)
break;
if (i == m)
return -1; //查找失败
j = B[i].start;
while (j < B[i].start + B[i].length)
{
if (K2 == A[j].key)
break;
else
j++;
}
if (j < B[i].start + B[i].length)
return j; //查找成功
else
return -1; //查找失败
}
若 IndexKeyType 被定义为字符串类型,则算法中相应的条件改为
strcmp (K1, B[i].index) == 0;
同理,若KeyType 被定义为字符串类型
则算法中相应的条件也应该改为
strcmp (K2, A[j].key) == 0
若每个子表在主表A中采用的是链接存储,则只要把上面算法中的while循环
和其后的if语句进行如下修改即可:
while (j != -1)//用-1作为空指针标记
{
if (K2 == A[j].key)
break;
else
j = A[j].next;
}
return j;
若索引表B为稠密索引,则更为简单,只需查找索引表B,成功时直接返回B[i].start即可。
索引查找分析:
索引查找的比较次数等于算法中查找索引表的比较次数和查找相应子表的比较次数之和,假定索引表的长度为m,子表长度为s,
则索引查找的平均查找长度为:
ASL= (1+m)/2 + (1+s)/2 = 1 + (m+s)/2
假定每个子表具有相同的长度,即s=n/m, 则 ASL = 1 + (m + n/m)/2 ,当m = n/m ,(即m = √▔n,此时s也等于√▔n), ASL = 1 + √▔n 最小 ,时间复杂度为 O(√▔n)
可见,索引查找的速度快于顺序查找,但低于二分查找。
在索引存储中,不仅便于查找单个元素,而且更方便查找一个子表中的全部元素,若在主表中的每个子表后都预留有空闲位置,则索引存储也便于进行插入和删除运算。
3、分块查找
分块查找属于索引查找,其对应的索引表为稀疏索引,具体地说,分块查找要求主表中每个子表(又称为块)之间是递增(或递减)有序的。即前块中最大关键字必须
小于后块中的最小关键字,但块内元素的排列可无序。它还要求索引值域为每块中的最大关键字。
下图是用于分块查找的主表和索引表的示例:
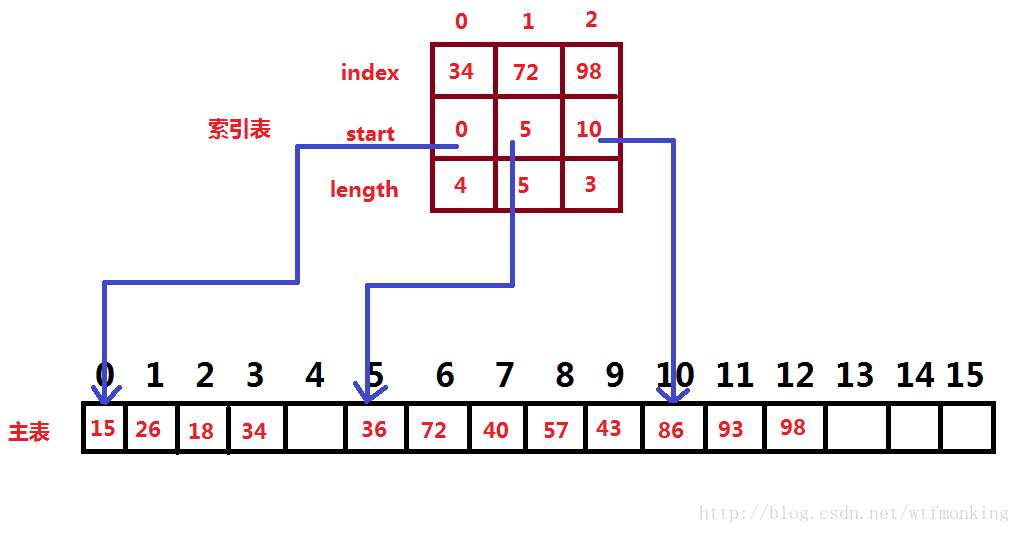
分块查找的算法同上面的索引查找算法类似,具体如下:
int Blocksch(mainlist A, indexlist B, int m, KeyType K)
{//利用主表A和大小为m的索引表B分块查找关键字为K的记录
int i, j;
for (i = 0; i < m; i++)
if (K <= B[i].index)
break;
if (i == m)
return -1; //查找失败
j = B[i].start;
while (j < B[i].start + B[i].length)
{
if (K == A[j].key)
break;
else
j++;
}
if (j < B[i].start + B[i].length)
return j;
else
return -1;
}
若在索引表上不是顺序查找,而是二分查找相应的索引项,则需要把算法中的for循环
语句更换为如下的程序段:
int low = 0, high = m - 1;
while (low <= high)
{
int mid = (low + high) / 2;
if (K == B[mid].index)
{
i = mid;
break;
}
else if (K < B[mid].index)
high = mid - 1;
else
low = mid + 1;
}
if (low > high)
i = low;
这里当二分查找失败时,应把low的值赋给i,此时b[i].index是刚大于K的索引值
当然若low的值为m,则表示真正的查找失败。
C语言两种查找方式(分块查找,二分法)
二分法(必须要保证数据是有序排列的): 分块查找(数据有如下特点:块间有序,块内无序):
c语言完成分块查找
首先要把一系列数组均匀分成若干块(最后一个可以不均匀) 每块中元素任意排列,即块中数字无序,但是整个块之间要有序.因此也存在局限性. #include //分块查找法 v ...
查找->;静态查找表->;分块查找(索引顺序表)
文字描述 分块查找又称为索引顺序查找,是顺序查找的一种改进方法.在此查找算法中,除表本身外, 还需要建立一个”索引表”.索引表中包括两项内容:关键字项(其值为该字表内的最大关键字)和指针项(指示该子表 ...
HDOJ1251(前缀匹配---分块查找&;map应用)
分块查找算法 #include #include #include #include
分块查找(Blocking Search)
1.定义 分块查找(Blocking Search)又称索引顺序查找.它是一种性能介于顺序查找和二分查找之间的查找方法. 2.基本思想 分块查找的基本思想是: (1)首先查找索引表 索引表是有序表,可 ...
数据结构之二分查找——Java语言实现
场景描述:给出一个数据序列长度为N,然后查找 一个数是否在数据序列中,若是,则返回在序列中的第几个位置. 首先可能第一个想到的就是按照顺序,从前到后一个一个进行查找,直到找到为止,若最后都没有,则说明 ...
折半查找(C语言)
一.二分查找 在C和C++里,二分查找是针对有序数组所用的一种快速查找元素的方法. 二.二分查找的条件以及优缺点 条件:针对有序数组(元素从小到大或从大到小) 优点:查询速度较快,时间复杂度为O(n) ...
顺序查找&;二分查找&;索引查找
1.查找技术的分类.如下图: 2.什么是顺序查找呢?(无序表) 顺序查找的原理很简单,就是遍历整个列表,逐个进行记录的关键字与给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录.如 ...
JS-七大查找算法
顺序查找 二分查找 插值查找 斐波那契查找 树表查找 分块查找 哈希查找 查找定义:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录).查找算法分类:1)静态查找和动态查找:注 ...
随机推荐
DelphiXE10.1项目中增加预编译的方法
操作: 菜单选择Proceject->Options->Delphi Compilerz在Conditional Defines(第一行)中添加预编译标识.例:VCL代码:uses{$IF ...
【转】Selenium 面试题总结(乙醇Blog记录的面试题)
原文链接:http://www.cnblogs.com/tsbc/p/4922368.html ###selenium中如何判断元素是否存在? - isElementPresent ###sele ...
Haproxy安装及配置
1.安装 # wget http://haproxy.1wt.eu/download/1.3/src/haproxy-1.3.20.tar.gz # tar zcvf haproxy-1.3.20.t ...
【转】探讨android更新UI的几种方法----不错
原文网址:http://www.cnblogs.com/wenjiang/p/3180324.html 作为IT新手,总以为只要有时间,有精力,什么东西都能做出来.这种念头我也有过,但很快就熄灭了,因 ...
python socket编程学习笔记2
server.py: [服务端步骤]: 1.创建socket对象 2.将socket绑定到指定地址(bind) 3.监听连接请求(listen) 4.等待客户请求(accept) 5.处理请求(服务 ...
不同服务器之间使用svn钩子post-commit同步代码遇到的证书认证问题.md
遇到的问题,以下其他问题都是因解决这个问题引申出来的问题 VisualSVN hooks自动同步更新到web服务器 错误信息如下: Error validating server certificat ...
Linux 磁盘挂载分区
举例说明: 新增磁盘的设备文件名为 /dev/vdb 大小为100GB. #fdisk -l 查看新增的的磁盘 1.对新增磁盘进行分区 #fdisk /dev/vdb 按提示操作 p打印 n新增 d ...
proxool 连接池
今天配置proxool 连接池,发现可配置属性非常多,以前也只是用,没总结过,今天查了下网上的资料,总结一下 方便你我.其实网上很多英文资料都很全,网上很多人就是考翻译老外的文章赚些流量,其实也没啥意 ...
nodejs 文件系统
nodejs访问文件系统 所有的文件系统的调用,都需要加载fs模块,即var fs=require('fs'); nodejs提供的fs模块几乎所有的功能都有两种形式选择:异步和同步,如异步的wr ...
[计算机网络-传输层] 面向连接的传输:TCP
参考:http://blog.csdn.net/macdroid/article/details/49070185 在学习TCP之前我们先来看一下可靠数据传输需要提供什么样的机制: ·差错检测机制:检 ...

















 5219
5219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









