





导语
Pandas是数据分析中一个至关重要的库,它是大多数据项目的支柱。如果你想从事数据分析相关的职业,那么你要做的第一件事情就是学习Pandas。
通过这一课,您将会:
1、对Pandas有一个全面的认识;
2、学会安装和导入Pandas;
3、掌握Pandas的核心概念并初步实践。
pandas简介
1.pandas可以用来做什么?
pandas可以说是数据的管家。通过pandas,您可以通过清理、转换和分析数据来熟悉您的数据。
例如,假设您希望研究存储在计算机上的CSV中的数据集。pandas将从CSV中提取数据到DataFrame中,这时候数据可以被看成是一个Excel表格,然后让你做这样的事情:
- 计算统计数据并回答有关数据的问题,比如每一列的平均值、中值、最大值或最小值是多少?列A和列B相关吗?C列中的数据分布情况如何?
- 通过删除缺失的值和根据某些条件过滤行或列来清理数据
- 在Matplotlib的帮助下可视化数据。绘制条形图、线条、直方图、气泡等。
- 将清理后的数据存储到CSV、其他文件或数据库中
在开始建模或复杂的可视化之前,您需要很好地理解数据集的性质,而pandas是实现这一点的最佳途径。
2.pandas和其它工具包的关系
pandas不仅是数据科学工具箱的中心组件,而且与该集合中的其他工具包一起使用:
- pandas构建在NumPy包的顶部,这意味着在pandas中使用或复制了许多NumPy的结构。
- pandas中的数据通常用到SciPy中的统计分析
- pandas中的数据分析结果展示会通过Matplotlib中的绘图函数
- pandas中的数据处理后会通过Scikit-learn中的机器学习算法挖掘信息。
- Jupyter Notebook为使用pandas进行数据探索和建模提供了良好的环境,但是pandas也可以轻松地用于文本编辑器。与运行整个文件相比,Jupyter Notebook使我们能够在特定的单元中执行代码。这在处理大型数据集和复杂转换时节省了大量时间。
3.学习pandas需要准备什么
如果您没有任何用Python编写代码的经验,那么您应该在学习panda之前把基础打牢。您应该先熟练掌握基础知识,比如列表、元组、字典、函数和迭代。此外,我还建议您熟悉NumPy,因为上面提到pandas是建立在NumPy基础之上。
4.pandas安装和导入
pandas是一个易于安装的包。打开您的终端程序(针对Mac用户)或命令行(针对PC用户),然后使用以下命令之一安装它:
pip install pandasconda install pandas为了导入pandas,我们通常用一个更短的名字来导入它,因为它使用得太多了:
import pandas as pdpandas的核心
1.Series和DataFrame
pandas的两个主要核心是 Series 以及 DataFrame.
Series本质上是一个列, 而DataFrame是一个由Series集合组成的多维表:
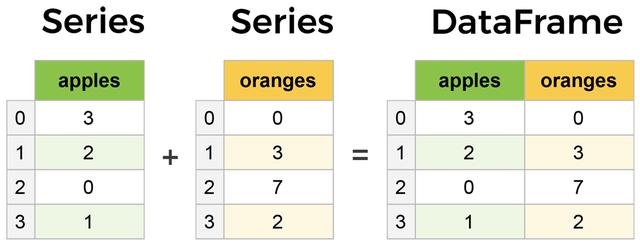
DataFrame和Series在许多操作上非常相似,一个操作可以执行另一个操作,比如填充空值和计算平均值。
2.创建DataFrame
在Python中正确地创建DataFrame非常有用,而且在测试在pandas文档中找到的新方法和函数时也非常有用。从头创建DataFrame有许多方法,但是一个很好的选择是使用简单的dict字典
假设我们有一个卖苹果和橘子的水果摊。我们希望每个水果都有一列,每个客户购买都有一行。要把这个组织成一个熊猫字典,我们可以这样做:
import pandas as pddata = { 'apples': [3, 2, 0, 1], 'oranges': [0, 3, 7, 2]}然后将其传递给pandas DataFrame构造函数:
purchases = pd.DataFrame(data)print (purchases)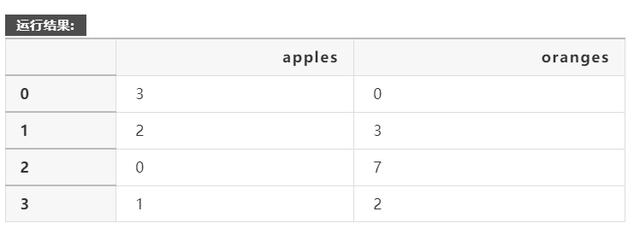
这是怎么做到的呢?
数据中的每个(键、值)项对应于结果DataFrame中的一个列。这个DataFrame的索引在创建时被指定为数字0-3,但是我们也可以在初始化DataFrame时创建自己的索引。
让我们有客户的名字作为我们的索引(index):
import pandas as pddata = { 'apples': [3, 2, 0, 1], 'oranges': [0, 3, 7, 2]}purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David'])print (purchases)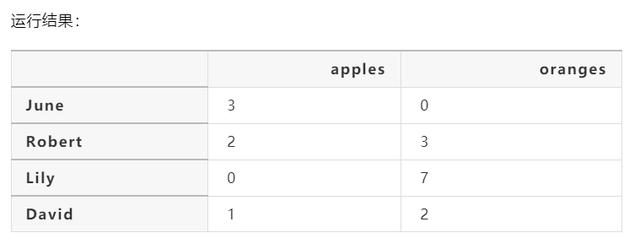
所以现在我们可以通过使用客户的名字来定位他们的订单:
purchases.loc['June']
另外,DataFrame中一些简单的函数:
print(purchases['apples']) #打印一列print(purchases.dtypes) #打印数据属性print(purchases.index) #打印行的索引print(purchases.columns) #打印列的索引请大家逐一尝试这些函数。














 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









