





前言
没有线程池的多线程分享是没有灵魂的,由人类创造的世界正在朝着黑盒化发展,究其根源只是少部分的聪明人创造出来一些东西让大多数的懒人更加的懒罢了,但是不可否认的是这些工具都非常的好用,我个人认为今天要分享的线程池就是其中的一员。使用线程池,他就会为线程从创建到销毁的全过程保驾护航,我们要做的就只是把task进行submit或者execute即可,废话不多说了,接下来我们一点点的揭开线程池的面纱,一睹其迷人且神秘的芳容。
正文
不得不说的Executor框架:
那什么是Executor框架呢?我们知道线程池就是线程的集合,线程池集中管理线程,以实现线程的重用,降低资源消耗,提高响应速度等。线程用于执行异步任务,单个的线程既是工作单元也是执行机制,从JDK1.5开始,为了把工作单元与执行机制分离开,Executor框架诞生了,他是一个用于统一创建与运行的接口。Executor框架实现的就是线程池的功能。
Executor框架的组成
其分为3部分:
- 任务:Runnable接口或者Callable接口;
- 执行器:Executor接口(执行者线程的定义和线程的运行分开),以及继承自Executor接口的ExecutorService接口(完善了线程池的生命周期)
- 计算结果:Future接口以及其实现类FutureTask类。
成员描述:
- Executor:执行器,执行者线程的定义和线程的运行分开,
- ExecutorService:继承了Executor,完善了线程池的生命周期
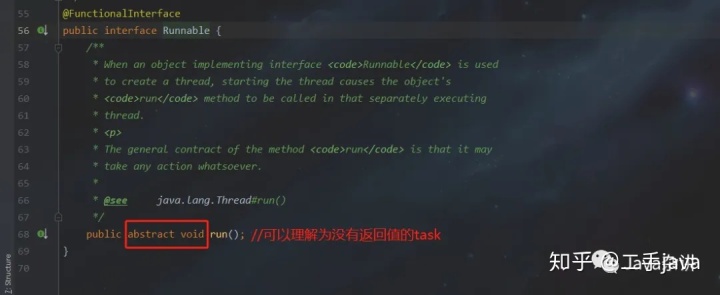
- Runnable:无返回值的task。
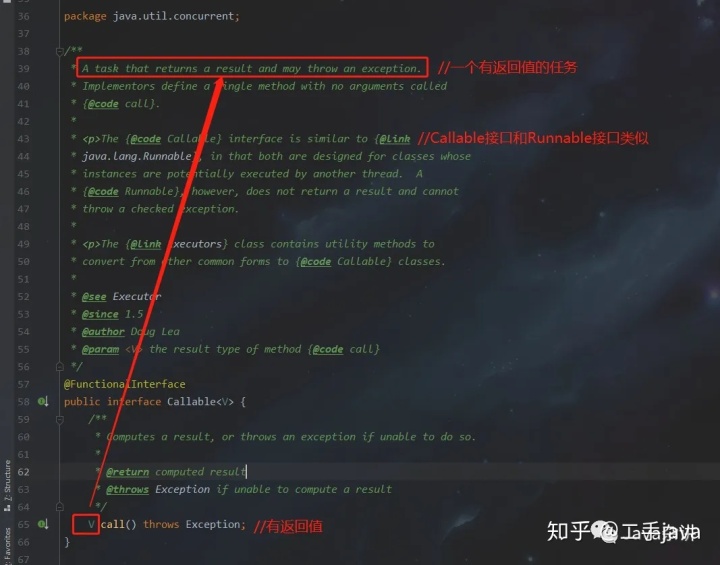
- Callable:有返回值的task,可以理解为有返回结果的Runnable.
- Future:存储执行的将来才会产生的结果。
- FutureTask:Future+Runnable.
- CompletableFuture:管理多个future结果.
线程池模型:维护两个集合,一个是线程的集合,一个是任务的集合。
- ThreadPool:多见于线程并发,阻塞时延比较长的,这种线程池比较常见,一般设置的线程个数根据业务性能要求会比较多。流程模型如下:
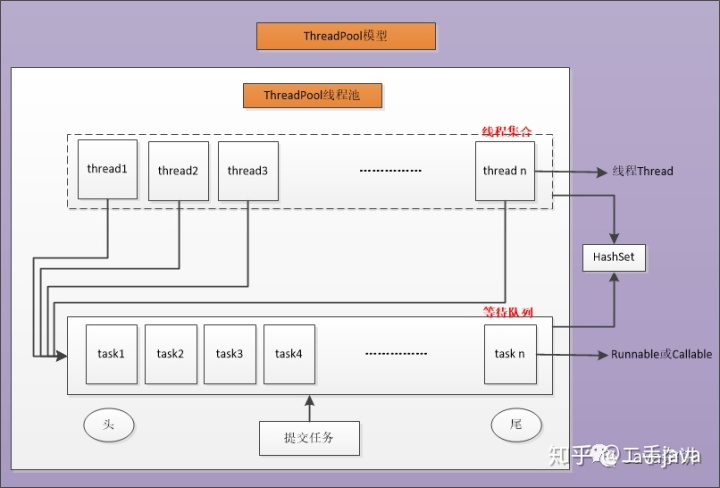
其维护一个线程的集合,一个任务集合,所有线程共用一个任务集合,当线程空闲时,就会从队列中认领工作。由于线程资源的创建与销毁开销很大,所以ThreadPool允许线程的重用,减少创建与销毁的次数,提高效率。
- ForkJoinPool:特点是少量线程完成大量任务,一般用于非阻塞的,能快速处理的业务,或阻塞延时比较少的。流程模型如下:
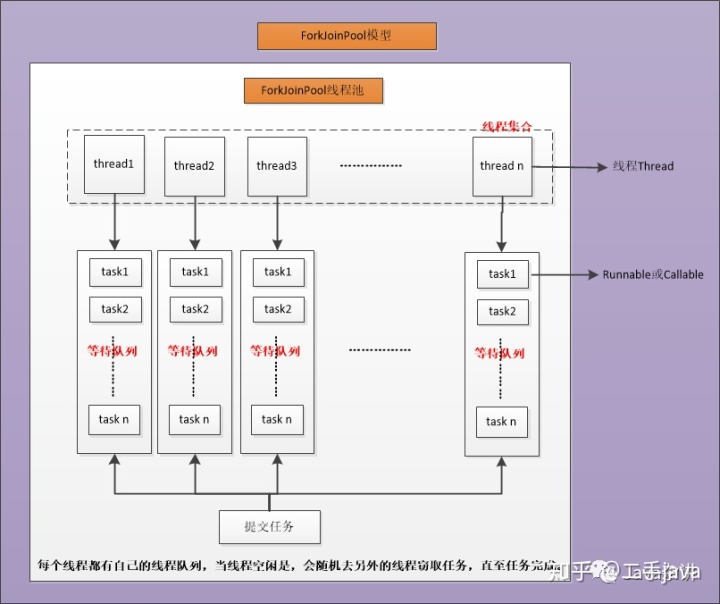
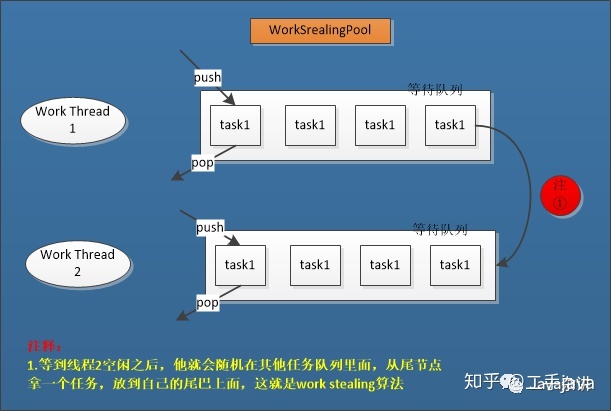
工作方式:使用一种分治算法,递归地将任务分割成更小的子任务,其中阈值可配置,然后把子任务分配给不同的线程并发执行,最后再把结果组合起来。该用法常见于数组与集合的运算。由于提交的任务不一定能够递归地分割成ForkJoinTask,且ForkJoinTask执行时间不等长,所以ForkJoinPool使用一种工作窃取的算法,允许空闲的线程“窃取”分配给另一个线程的工作。由于工作无法平均分配并执行。所以工作窃取算法能更高效地利用硬件资源。
线程池的使用
- 使用Executors - 线程池的工厂创建:
- SingleThreadExecutor:
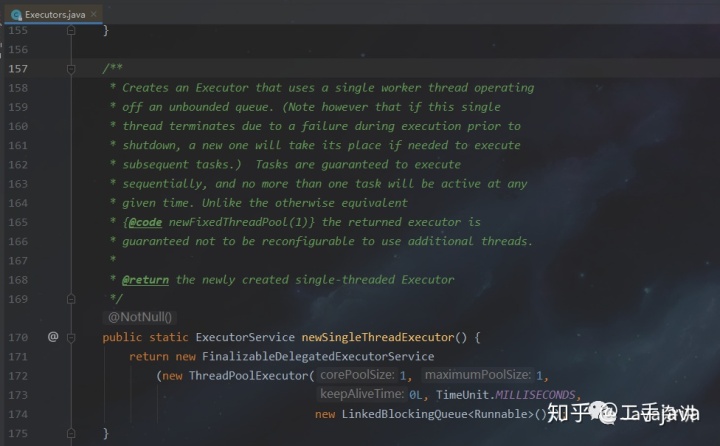
特性:
只有一个工作线程;
存活时间为0,即线程一但空闲就会被回收;
使用的队列是LinkedBlockingQueue,也就代表等待队列可以存放Interger的最大值个数的task。
思考:为什么要有一个线程的线程池?
线程池有任务队列;
线程池有完整的生命周期;
- CachedThreadPool:
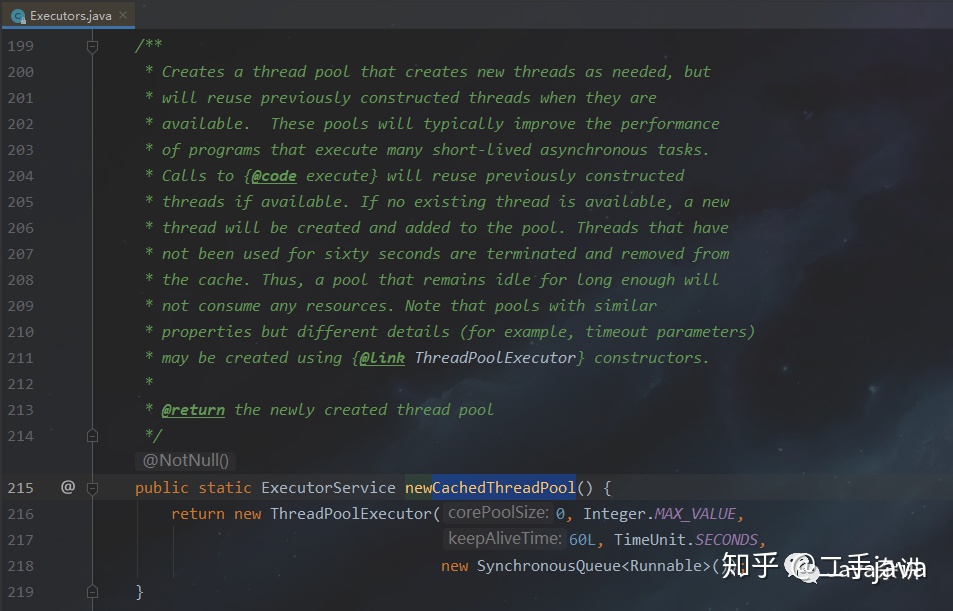
特性:
没有核心线程;
线程最大数量为Interger的最大值;
线程空闲60秒就会被回收;
任务队列为SynchronousQueue,即队列不会存储任务,当来一个任务,就需要一个线程去处理,有闲置线程的情况下,闲置线程处理;没有闲置线程,那么新创建一个线程去处理。一般不会使用这个线程池,因为启动的线程可能太多。只有在调用数量起伏比较大,但是必须保证有线程去处理时使用。
- FixedThreadPool:

特征:
只有核心线程,且数量可以自己手动设置;
等待队列的长度为Interger的最大值;
适用于调用数量比较平稳的情况。
- ScheduledThreadPool:执行定时任务的线程池
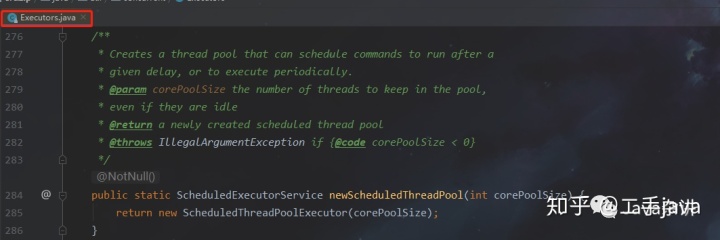
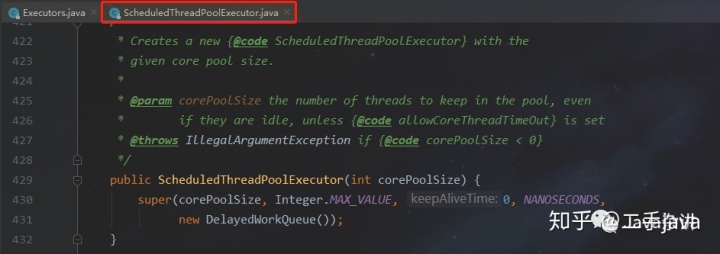
特性:
可以设置核心线程数;
最大线程数为Integer的最大数;
使用的队列为DelayedWorkQueue(),这就代表可以为其任务的消费进行定时。
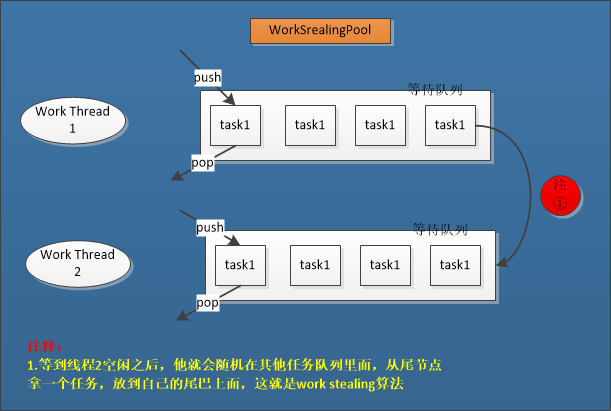
- WorkStealingPool:
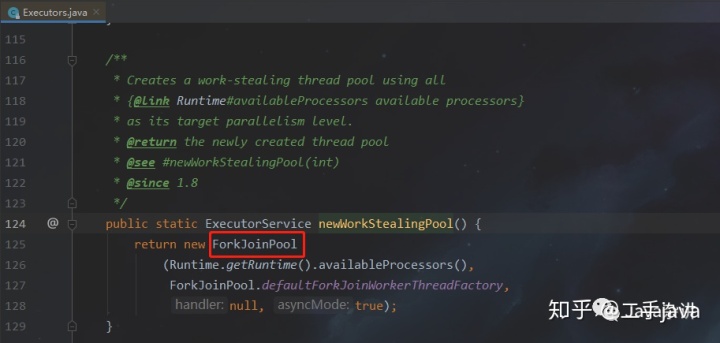
特点:
每个线程都有一个单独的队列,本质是一个ForkJoinPool。
使用Work Stealing算法,示例图如下:
- ForkJoinPool:
特点:适合将大任务切分成小任务,还可以做结果汇总,思想上有些类似大数据中的MapReduce;
继承RecursiveAction,这个玩意不带返回值,继承RecursiveTask有返回值。
思考:对于阿里操作手册上面为什么不希望开发人员使用jdk提供的SingleThreadExecutor、CachedThreadPool、FixedThreadPool、ScheduledThreadPool呢?
一部分原因是因为,在声明线程池的时候,最好可以自己定义线程的生产工厂类,这样可以给线程添加自己的名称,利于排查错误。
一部分原因如下:
最大线程数太大,导致oom:
ScheduledThreadPool、CachedThreadPool
线程的等待队列长度太大,导致oom:
SingleThreadExecutor、FixedThreadPool
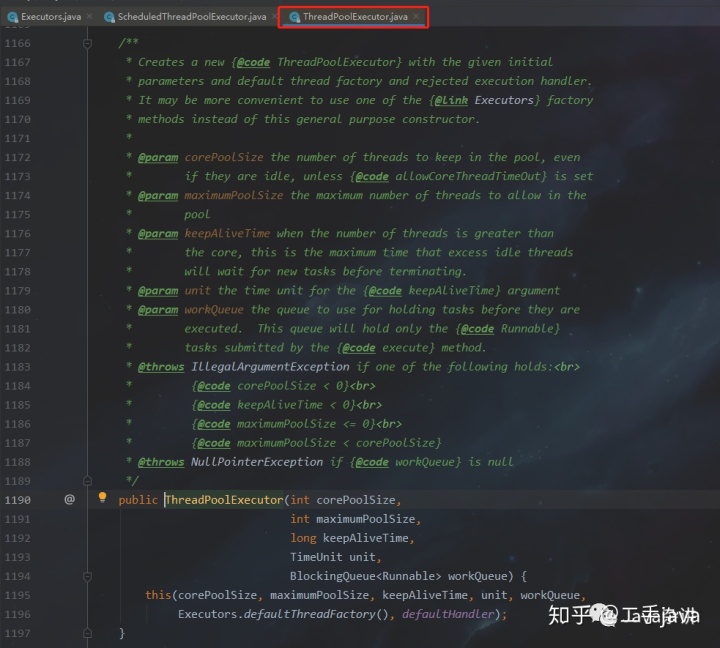
既然阿里手册上面不建议直接使用jdk自带的线程池的实现方式,那么我们就通过ThreadPoolExecutor来自定义我们的线程池吧:
2.通过ThreadPoolExecutor来自定义的创建线程池:
方法如下:

使用示例:
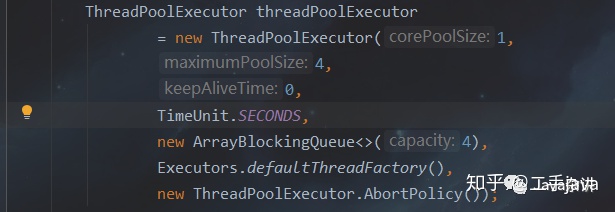
这就是“著名”的7个参数,其他的创建线程池的方法(ThreadPoolExecutor创建)都是在其基础上添加一些默认值进行组装的,接下来介绍一下这七个参数。
- corePoolSize:核心线程数,如果调用了prestartAllCoreThread()方法,那么线程池会提前创建并启动所有基本线程。
- maximumPoolSize:能够扩展的最大线程数,即线程池的大小。
- keepAliveTime:线程多久没有任务之后会归还给操作系统(OS),核心线程不会归还,这里指的是非核心线程(核心线程归还与否是可以设置的)
- timeUnit:keepAliveTime的时间单位,有天(DAYS)、小时(HOURS)、分(MINUTES)、秒(SECONDS)、毫秒(MILLISECONDS)、微秒(MICROSECONDS)、纳秒(NANOSECONDS)。
- workQueue:存储队列,常用的队列如下:
ArrayBlockingQueue:可以限定长度
LinkedBlockingQueue:最多可以使Interger的最大值的个数的任务
SynchronusQueue:线程池中只能有一个任务,添加一个任务就需要去处理,队列里面不存储任务。
- 实现ThreadFactory:
就是产生线程的方式,默认的是defaultThreadFactory(),阿里开发手册中声明在创建线程池的时候,需要自己定义线程工厂,为每个线程赋予其独特的名称,方便排查错误是定位错误所在。 - 拒绝策略:
一般情况下需要自定义拒绝策略。在线程池里面添加任务的时候有一个顺序,首先填充满核心线程然后在队列里面放,放满了然后是非核心线程,再然后才会触发拒绝策略。
jdk默认四种(可以自定义):- AbortPolicy:这是默认的策略,直接抛出异常;
- CallerRunsPolicy:只是用调用者所在线程来运行任务;
- DiscardOldestPolicy:丢弃队列中最老的任务,并执行当前任务;
- DiscardPolicy:不处理,直接把当前任务丢弃;
使用ThreadPoolExecutor参数配置

上图为计算线程数量的方法,需要根据判断场景是io密集型还是cpu密集型,以及你期望cpu的使用率等因素进行设置,根据经验,大部分的使用场景为cpu密集型场景,所以线程数量的设计即为电脑的核数,当然无论是按照公式还是按照自己的经验进行配置,最后都要进行压测已达到计算机最大使用率。
放在最后的话:
线程池分为ThreadPoolExecutor以及ForkJoinPool两种,今天解释的是我们最常见的也是变化较为多的ThreadPoolExecutor,ForkJoinPool一笔带过,他的使用还是比较简单的,学会RecursiveAction(无返回值)以及RecursiveTask(有返回值)两个类的使用就差不多了。

点关注不迷路,请搜索《杂讲java》微信公众号,上面会持续更新更多技术分享文章!!














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









