





1.拷贝、引用
执行下面的代码的结果如下:
class Solution:
def rotate(self, matrix):
"""
Do not return anything, modify matrix in-place instead.
"""
n = len(matrix)
temp = [[0]*n for _ in range(n)]
#temp = matrix
#temp = copy.deepcopy(matrix)
print(temp, matrix)
matrix = temp[:]
print(temp,matrix)
x = [[1,2,3],[4,5,6],[7,8,9]]
Solution().rotate(x)
print(x)
matrix = temp[:] 修改为 matrix[:] = temp

错误的原因:在调用函数时,传递给形参的是实参matrix的地址,用后一种切片复制,可以根据这个地址对实参进行原地修改;而如果用前一种,函数里的matrix就不再是实参的地址了,而是matrix_new的一个引用,即使修改了,也不会影响实参。
执行下面的代码:
class Solution:
def rotate(self, matrix):
"""
Do not return anything, modify matrix in-place instead.
"""
n = len(matrix)
#temp = [[0]*n for _ in range(n)]
temp = matrix[:]
#temp = copy.deepcopy(matrix)
print(temp, matrix)
temp[0][0] = 0
print(temp,matrix)
x = [[1,2,3],[4,5,6],[7,8,9]]
Solution().rotate(x)
print(x)
按理说temp是matrix的拷贝,不应该出现matrix同时被更改的情形啊?这个就是浅层拷贝的问题。
将 temp = matrix[:] 改成 temp = copy.deepcopy(matrix),结果如下

最后对比一下
temp = [[1]*n for _ in range(n)] 和 temp = [[1]*n]*n


后面一种会出现莫名奇妙的错误,仅仅执行了 temp[0][0]=0 。原因在于,因为列表是可变变量,[1,1,1] * 3 后是3个地址一样的[1,1,1],并没有创建更多的列表.
详细的可以看这个链接。
python 深入理解 赋值、引用、拷贝、作用域 - 江召伟 - 博客园www.cnblogs.com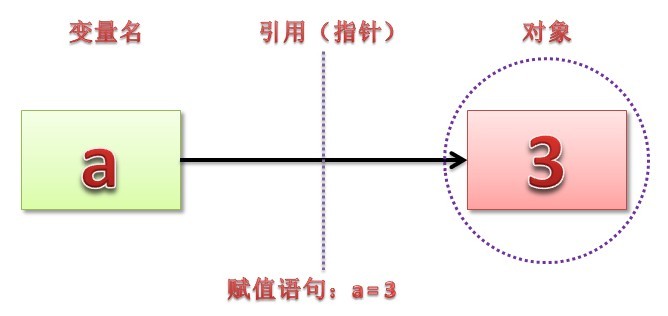
2.关于排序的那些事
n = len(intercopy)
for i in range(n):
for j in range(i+1,n):
if intercopy[i]>intercopy[j]:
intercopy[i],intercopy[j]=intercopy[j],intercopy[i]上面是冒泡排序,和python 自带的sort 函数做对比,结果耗时差距是2个数量级 。
intercopy.sort(key = lambda x:x[0])下面一篇文章对10种常见排序做了分析,还有动图。
十大经典排序算法(动图演示) - 一像素 - 博客园www.cnblogs.com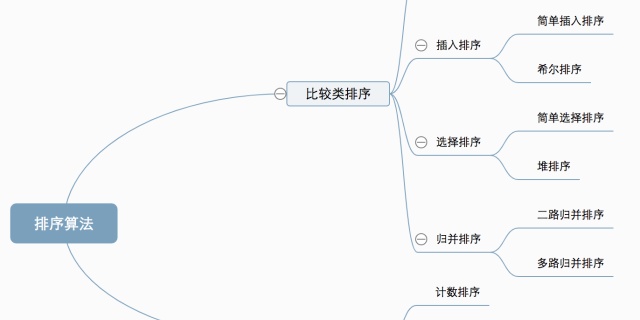
下面一篇则是对sort排序算法详细分析(timesort的)
python sort函数内部实现原理www.cnblogs.com
看完以后,默默删除了自己写的冒泡算法。
3.二叉树
今天刷leetcode二叉树,遇到一个超时的问题。解题思路用的是中序遍历。
class Solution:
def convertBiNode(self, root: TreeNode) -> TreeNode:
def judge(root: TreeNode) -> (TreeNode,TreeNode):
begin=end=root
if root:
if root.left:
begin,end = judge(root.left)
#end.left = None # 这句话没什么用,因为返回的end必然没有子节点
end.right = root
end = root
root.left = None # 这句话必须要有,root的左子节点必须修改
if root.right:
root.right,end = judge(root.right)
return begin,end
return judge(root)[0]上面#注释的2句话,仔细分析了一下,发现第二句话必须加上去,第一句话是无效操作。
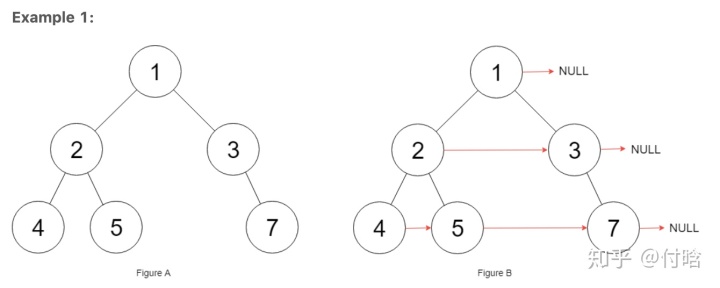
class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root: return None
#dummy = Node() #位置2
p = root
while p:
dummy = Node() #位置1
nextlevel = dummy
while p:
if p.left :
nextlevel.next = p.left
nextlevel = p.left
if p.right:
nextlevel.next = p.right
nextlevel = p.right
p = p.next
p = dummy.next
return root 如上图和代码块,位置1的这句话如果放在位置2会导致循环出不来,debug之后发现当遍历完树的最下面一层,dummy.next还是会指向最后一层的第一个元素。所以必须初始化,让dummy.next = None
20200724
x = (l+r)//2 #1 l<=r,且是整形
x = l+(r-l)//2 #2原理上看,两者没有区别。但是第二种在某些语言下(如c)可以防止数据溢出
20200728
在处理将二叉树转换成链表的题目中,遇到一个bug,如果用#2的方式编译会超时,#1则不会。百思不得其解,用同样的测试用例,在本地编译器上运行一遍,结果正确。
错误信息为:Found cycle in the TreeNode。怀疑编译器的版本不一样。
力扣leetcode-cn.comclass Solution:
def convertBiNode(self, root: TreeNode) -> TreeNode:
if not root: return None
lastp = None
p = root
stack = []
while p or stack:
while p:
stack.append(p)
p = p.left
p = stack.pop()
#p.left = None #1
if lastp:
lastp.left = None #2
lastp.right = p
else:
res = p
lastp = p
p = p.right
return res20200730:
今天遇到一个小bug,#1是c语言的写法,自己还没习惯python的写法,#2是正确写法。
class Solution:
def maximalRectangle(self, matrix: List[List[str]]) -> int:
if not matrix: return 0
m,n = len(matrix),len(matrix[0])
# 遍历整个数组 找出需要计算的行 存入栈
A = []
for i in range(m):
tmp = []
for j in range(n):
if i==0:
#tmp.append((int)matrix[i][j]) #1
tmp.append(int(matrix[i][j])) #2
else:
if matrix[i][j] == "0":
tmp.append(0)
else:
tmp.append(A[i-1][j]+1)
A.append(tmp)20200731:
积累两个二叉树遍历的模版,前序和中序竟然可以统一成一个模版。
前序遍历的模版:
def preorder1(root):
while root:
if root.right:
stack.append(root.right)
#do something
if root.left:
root = root.left
elif stack:
root = stack.pop()
else:
root = None前序、中序遍历的统一模版:
def inorderTraversal(self, root: TreeNode) -> List[int]:
stack = []
while root or stack:
while root:
# do something 前序
stack.append(root)
root = root.left
root = stack.pop()
# do something 中序
root = root.right














 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









