






Python数据结构(七)排序算法 quickSort
上文:
莫同学:Python数据结构(七)排序算法 ShellSortzhuanlan.zhihu.com
一、快排逻辑
我在重新写排序这个系列的文章时候就开始思考这个问题:为什么大家都说快排很难,面试又经常考快排,一个不稳定的排序算法值得费这么多时间吗?
gaogle和BB站看了一些关于quicksort的资料,深感于一些不伦不类的解说视频在浪费大家的时间(有的连low high 指针合并后怎么进行与pivot 交换的条件都没有明说,有的用接近两个小时成功把自己讲晕的讲师……),于是我决定写一篇连中学生都能看懂的quicksort科普文,如果本文看一遍还不懂,请极其严重地评论或者私信我,告诉我令你困惑的地方。
快排的核心思想:
quick sort 是60年代的产物,是bubblesort 的改进版本。时间复杂度在大O(n logn)与大O(n^2)之间,空间复杂度为大O(1),不需要额外空间。
和折半查找的“折半”思维类似,每次都在数组中确定一个元素,元素的左边都是比这个元素要小的,右边都是不小于这个元素的(这个不小于相当的重要,代码能不能写对就看你能不能领悟这句话);
划分完成后,把元素的左半边数组送去做quicksort,右半边数组也送去做quicksort,直到每个数组剩下。
先举一个quicksort的动态图做示范。

注意看上面gif下面的两个移动的index,以及每一次都闪烁的那两个条状物。
数组的第一个条状物闪烁意思是说选择当前数组的第一个元素作为本次的pivot,也就是中轴线,剩下那个一直在移动并且闪烁条状物是当前正在进行比较的index(总共有两个index一个low另一个high)。
如果当前正在进行比较的index对应的元素比pivot 小,则一直往下移动,直到碰到index对应的元素比pivot 大,则和high对应的元素进行交换,并且接下来换做high 来移动,执行的逻辑和上面的一样。
再举一个栗子。
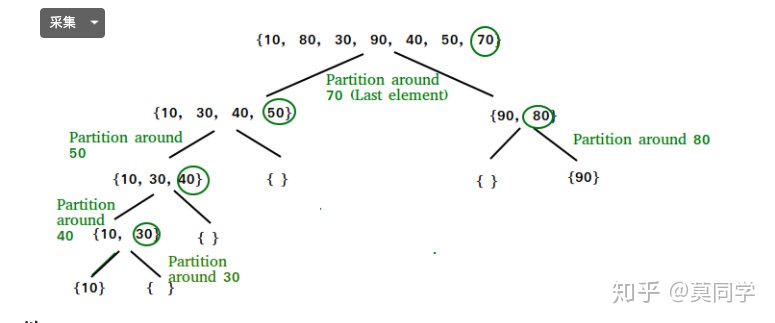
上图中,原数组的为 {10,80,30, 90,40,50,70}.
1) 以最右边70作为pivot,把数组分成左右两个部分,左边全部比70小,右边不小于70,70不用参与下一个循环;
2) 右边数组 {10,30,40,50},选择50作为pivot,把数组分成左右两个部分,左边{10,30,40},右边{},50不用参与下一个循环;
3) 左边数组{90.80},选择80作为pivot,把数组分成左右两个部分,左边{},右边{90},80不用参与下一轮循环;
4) 左边数组{10,30,40},选择40作为pivot,把数组分成两个部分,左边{10,30},右边{},40不用参与下一轮循环;
。。。
finally) 最后数组要么是只有一个元素,要么是空数组,排序完毕。
二、python实现
在我亲自实现quicksort 之前,我决定先股沟一下有没有一些比较trick的实现方式,果然,有一位大佬做到了。
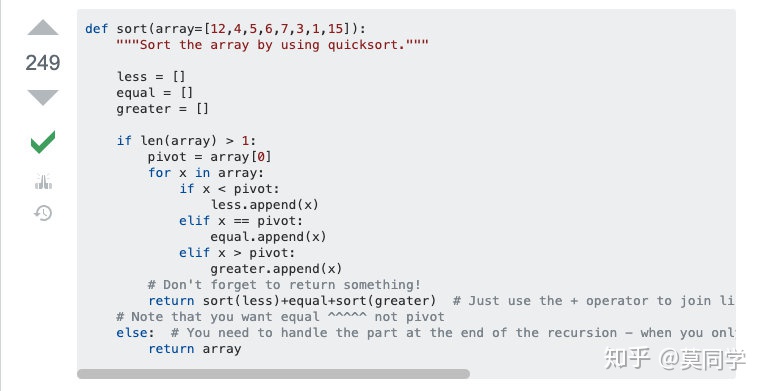
不知道大家能否理解,反正我看完,第一个感受就是这个算法的空间复杂度也太高了吧?! 每一轮的递归都要开辟三个新的list,我大概画一下图给你们分析一下这个空间是如何消耗的。
我们考虑这个空间复杂度的上界,也就是这个数组刚好是从大到小完全逆序的,我们要把它排成从小到大的正序。

可想而知,空间消耗是有多大。
这个还有一个优雅实现版本,用到了list comprehension,看着有点像pythonistic 的风格了。

虽然我想找一些trick 的实现方式,但不是这种huge trick!
trick = 就好像国外大学会比赛谁写的下象棋游戏编译出来的文件体积最小。
我看了下国内对于这种快排的实现的讨论,大意是这种实现方式虽然简洁但是不是真正意义上的quicksort,因为真正意义上的quicksort 是in-place的,i.e.,也就是空间复杂度大O(1),每次递归都是在原来的数组上操作。
三、quickSort的真正实现
没错,我比较赞同认为上述的两种实现方式不是真正quicksort的评价,所以我决定根据自己理解写下空间复杂度大O(1)的quicksort.
我参考的是geekforgeek里的python 实现,源代码在引用[3]。
def 关于这个partition函数,我自己做了一个gif演示,虽然简陋但是能明确表明排序是如何进行的。
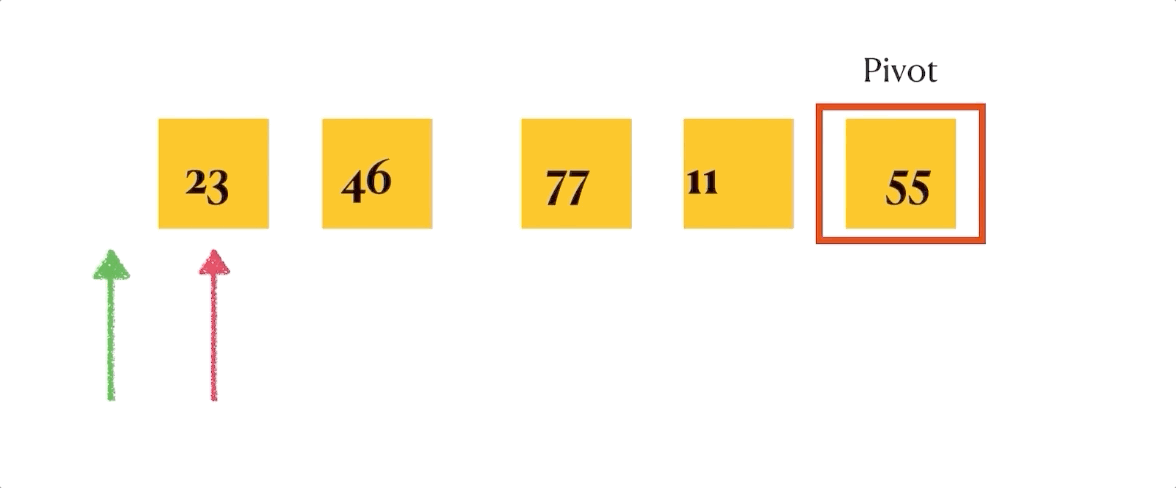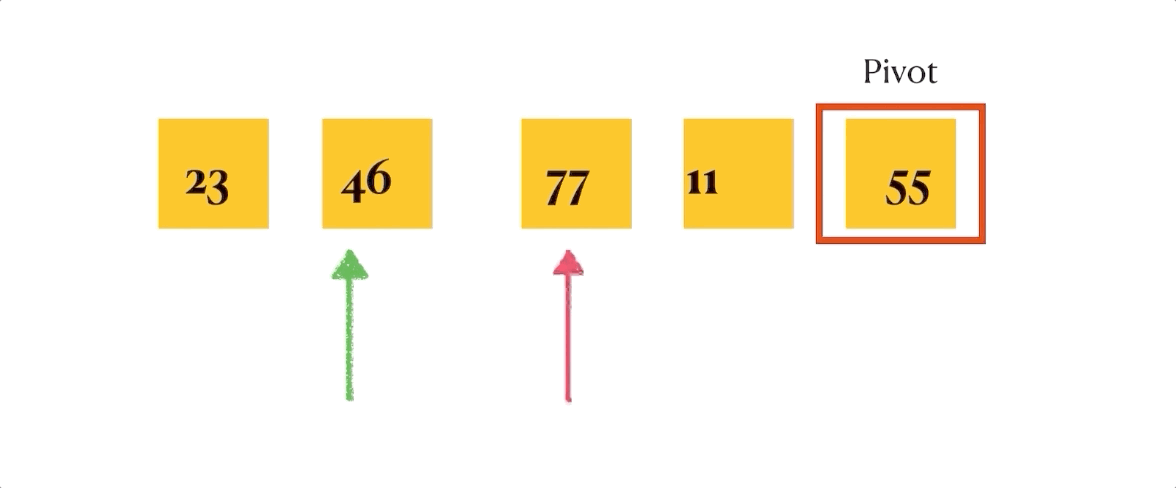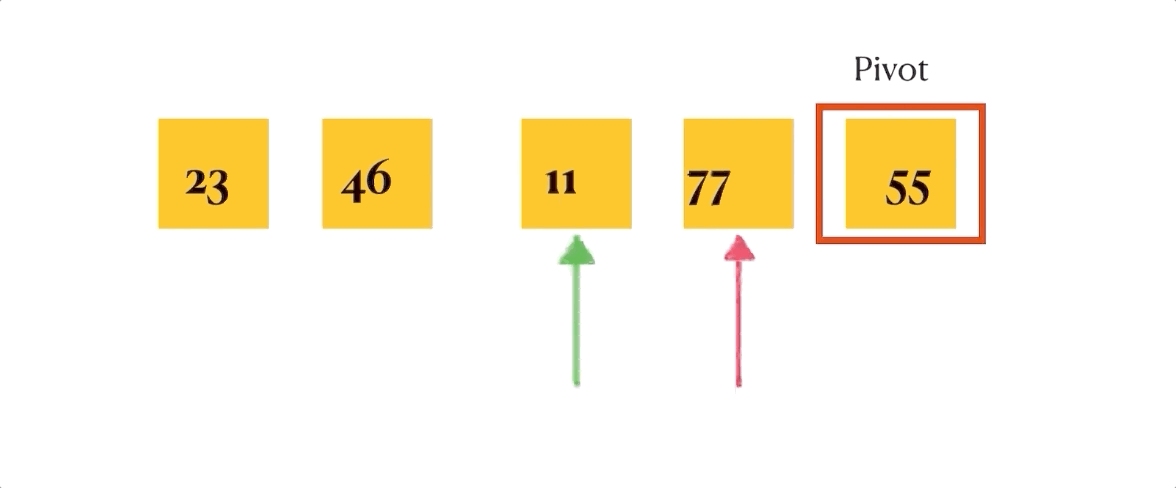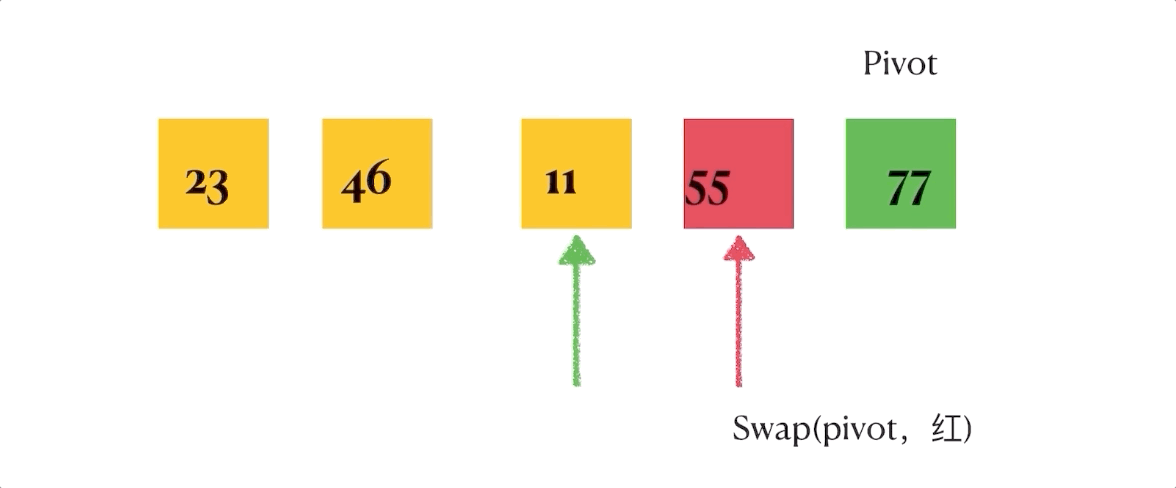
总结
回到开头的问题,快排确实因为稳定性的原因排不上排序算法的T0阵容,但是通过快排可以了解一名选手对算法边界问题的思考,比如在排序过程中low 和 high 指针(懂意思即可)重叠的时候怎么停止,所以,对算法的理解除了时间和空间复杂度,还应该清楚每个算法的边界条件,这才是这些基础算法给我们的启示(想想quicksort 早已经是60年代的产物)。
引用
[1] quicksort with python
[2] geekforgeekQuickSort















 2543
2543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









