





单身久的我们,好像觉得一个人过也没什么的。但即使非常享受单身生活,大家也要保持“可勾搭”的待机状态,因为促进荷尔蒙分沁有益身心健康。在这个人人都在秀的时候,做为程序员我们也要操作起来!散发你们的荷尔蒙!今天就大家奉献上一个Python最强表白程序!此程序结合数据抓取 + 微信自动发消息 + 定时任务,实现一个能每天自动定时给你心爱的 ta 发送:你们相识相恋天数 + 情话 + 我爱你的图片。具体的消息如下。
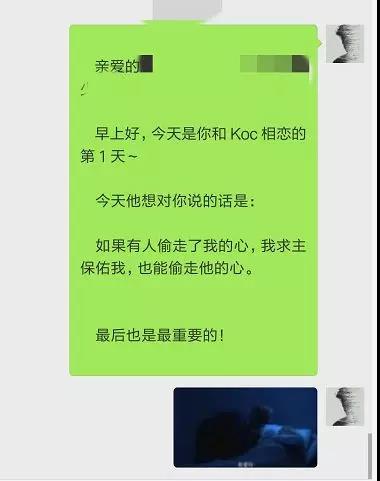
每天发送的消息格式如下:
message = """
亲爱的{}:
早上好,今天是你和 Koc 相恋的第 {} 天~
今天他想对你说的话是:
{}
最后也是最重要的!
""".format("你的好友名称", str(inLoveDays), love_word)
这里需要填写的第一个字段是 ta 的称呼,inLoveDays 为你们相识相恋的天数。love_word 是每天为 ta 精心准备情话内容,当然如果你的文笔好也可以自己写。

当然最后也是最重要的!每天不尽相同的「我爱你」图片!

程序思路
本次程序运行的环境是 windows10 + Python 3.5,此次主要用到的库有 selenium、itchat、request。程序主要分为两部分第一数据的抓取,一些情话信息和图片信息。另一部就是利用 itchat 自动发送消息给你的好友。
情话信息
如果对你的文笔有信心,那你可以自己写些情话。当然大部分人的文笔跟我一样是比较差的,所以这时候我们就可以利用网上的资源,比如下面的情话网站。
http://www.binzz.com/yulu2/3588.html

在抓取这个网站的情话时,如果你利用普通的爬取思路,即利用 request 进行请求,你会发现网页获取的数据是乱码并且不完整。所以在这块为了操作方便,我利用了 selenium 的 Firefox的无头模式,来获取网站的信息。
通过 selenium + xpath 我们就可以很轻松的获取到网页情话,最后把获取到的数据保存到当前目录下的「love_word.txt」方便之后的读取。
表白图片资源
为了配合此次七夕表白程序,我专门去找了些带有「我爱你」的图片资源。通过下面的贴吧贴子,我们就可以获取到大量的这样资源。
http://tieba.baidu.com/p/3108805355
此贴并没有很强的反爬措施,所以我简单的利用 request + re 来获取到图片资源,并保存到当前目录的下「img」文件里。在保存图片资源之前,我会先检查当前目录下是否有「img」文件夹,如果没有则会自动创建。
表白源码程序:
此次表白程序主要有 5 个函数
crawl_Love_words()
此函数通过 selenium + xpath 来抓取情话网站的资源,并存入到当前目录下的「love_word.txt」文件。
def crawl_love_words():
print("正在抓取情话...")
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
browser = webdriver.Firefox(options=options)
url = "http://www.binzz.com/yulu2/3588.html"
browser.get(url)
html = browser.page_source
Selector = etree.HTML(html)
love_words_xpath_str = "//div[@id='content']/p/text()"
love_words = Selector.xpath(love_words_xpath_str)
for i in love_words:
word = i.strip("\n\t\u3000\u3000").strip() ###\u3000 是全角的空白符
with open("love_word.txt","a")as file:
file.write(word+"\n")
print("情话抓取完成")
crawl_love_image()
此函数用来爬取贴吧带有「我爱你」的图片资源,通过 request + re 来实现。代码并不复杂,在正则表达式那也简单的写了一个,用来匹配当前也所有的图片资源。
def crawl_love_image():
print("正在抓取我爱你图片...")
for i in range(1,5):
url = "http://tieba.baidu.com/p/3108805355?pn={}".format(i)
response =requests.get(url)
html = response.text
pattern = re.compile(r'
.*?image_url = re.findall(pattern,html)
for j,data in enumerate(image_url):
pics = requests.get(data)
mkdir("pic_path")
fq = open("pic_path"+'\\'+str(i)+"_"+str(j)+'.jpg','wb') #下载图片,并保存和命名
fq.write(pics.content)
fq.close()
print("图片抓取完成")
mkdir(path)
此函数用来在当前目录下创建一个新的文件夹,以便存储相应的数据。
def mkdir(path):
folder = os.path.exists(path)
if not folder: ##判断是否存在文件夹如果不存在则创建文件夹
os.makedirs(path) ##makedirs创建文件时如果路径不存在会创建这个路径
print("---new folder---")
print("--- OK ---")
else:
print("正在保存图片中...")
send_new()
此函数通过利用 itchat 库,实现给你的微信好友自动发送消息。在这个函数中我利用 datetime 来计算你们之间相识相恋的时间。并且在登录的时候添加了一个「hotReload=True」,这样你就可以不用每次运行程序的时候都要登录。关于 itchat 更多的操作,大家可以去网上查找相应的资料。
def send_news():
###计算相恋的天数
inLoveDate = datetime.datetime(2014,2,14) ##相恋的时间
todayDate = datetime.datetime.today()
inLoveDays = (todayDate - inLoveDate).days
####获取情话
file_path = os.getcwd() + '\\'+ "love_word.txt"
with open(file_path,"r") as file:
love_word = file.readlines()[random.randint(0,123)].split(':')[1] ###这用中文:,因为文件中是以中文:分割的
itchat.auto_login(hotReload=False) ##热启动,不需要多次扫码登录
my_friend = itchat.search_friends(name="橙子")
girlfriend = my_friend[0]["UserName"]
print(girlfriend)
message = """
亲爱的{}:
早上好,今天是和你相恋的第{}天~
今天想对你说的话是:
{}
最后也是最重要的!
""".format("玲玲",str(inLoveDays),love_word)
itchat.send(message,toUserName=girlfriend)
pic_path = os.getcwd() + "\\" +"pic_path"
files = os.listdir(pic_path)
file = files[random.randint(0,66)]
love_image_file = pic_path +"\\" + file
try:
itchat.send_image(love_image_file,toUserName=girlfriend)
except Exception as e:
print(e)
main()
main() 函数就是我们主逻辑函数,程序运行的逻辑顺序就是在这个函数里规定的。在 main() 里我首先判断下当前路径下是否有「love_word.txt」文件,如果有则提示相应的信息,没有的话才去执 crawl_Love_words() 函数,去网上抓取一些情话数据。
其次再判断下当前目录下是否有「img」文件夹,用来判断我们是否有图片资源,没有则执行 crawl_love_image() 来抓取贴吧上的图片资源。
最后我们所需的数据都已准备完善,则调用 send_news() 函数,整理下要发送的数据格式,然后自动给你的 ta 发送消息。
def main():
file = os.path.exists("love_word.txt")
if not file: ##判断是否存在love_word.txt,没有的话就去爬取
crawl_love_words()
img = os.path.exists("pic_path")
if not img:
crawl_love_image()
send_news()
定时任务
每天定时发送我主要是用 while True 简单的实现,通过判断当前的时间是否是你所需要发送的时间,来达到每天定时发送。
if __name__ == '__main__':
while True:
curr_time = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
love_time = curr_time.split(" ")[1]
if love_time == "19:13:00":
main()
time.sleep(60)
else:
print("爱你的每一天都是如此美妙,现在时间:"+ love_time)
总结
此次的程序还有很多可以继续添加的地方。比如对于发送的消息字段,我们还可以继续添加天气信息、星座信息、娱乐新闻、最近的趣事、最近好看的电影等等。只要你能想到的内容,都可以添加上去。
这些信息在网上都可以获取的到,我们只要通过同样的思路,先抓取到本地,然后进行读取。当然如果你觉得存储本地会有被删的风险,那么你也可以保存到云端,在云端上进行存储。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









