






1. 问题简介
从文本文件input-data.txt获取数据,并分别使用快速、归并及堆排序来对数据进行排序,然后将排序后的数据写入文本文件output-data.txt中。
23, 34, 15, 19, 56, 57, 9 注:为进行区分,我们将从input-data.txt获取数据,分别使用快速、归并及堆排序进行排序后写入至文件output1-data.txt、output2-data.txt、output3-data.txt中。
2. 快速排序
2.1 快速排序原理
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序利用二分法和递归进行排序,简单过程如下:
- 挑选基准值:从数列中挑出一个元素,称为"基准"(pivot)。
- 分割:重新排序数列,把所有比基准值小的元素放在基准前面,把所有比基准值大的元素放在基准后面(与基准值相等的则可以到任意一边)。
- 递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
若以文本文件input-data.txt中的数据为例,则有如下过程:
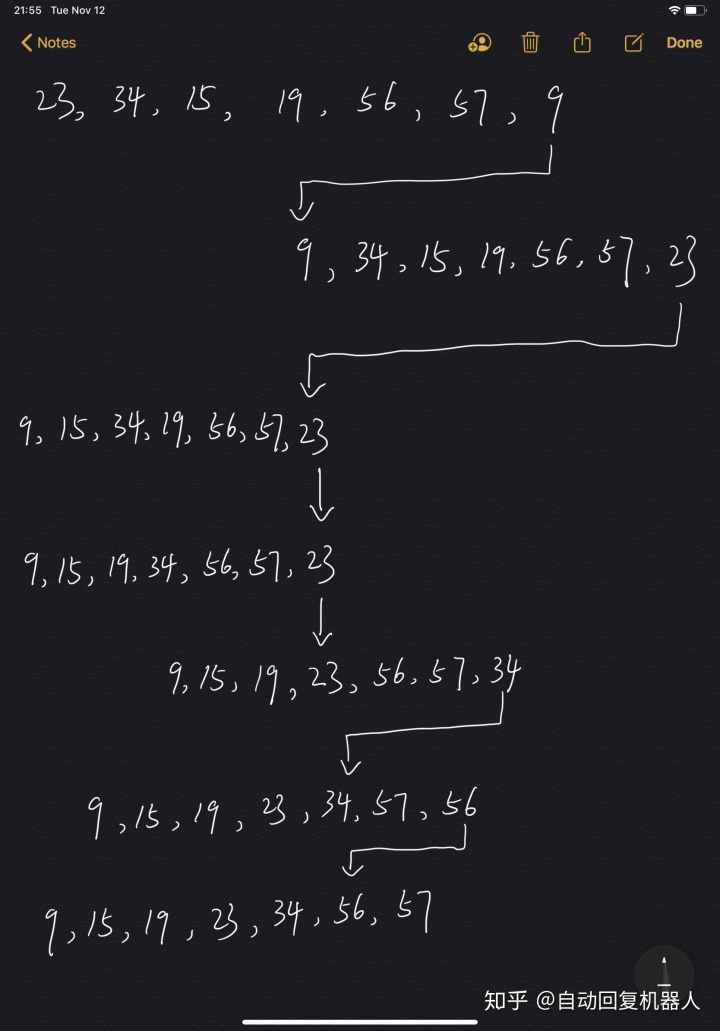
2.2 快速排序实现(Python)
#Quick sort function
def partition(data, low, high):
i = (low - 1)
pivot = data[high]
for j in range(low, high):
if data[j] <= pivot:
i = i + 1
data[i], data[j] = data[j], data[i]
data[i + 1], data[high] = data[high], data[i + 1]
return (i + 1)
def quickSort(data, low, high):
if low < high:
pi = partition(data, low, high)
quickSort(data, low, pi - 1)
quickSort(data, pi + 1, high)2.3 快速排序时间复杂度
快速排序是一种时间复杂度不稳定的算法,一般情况下它的时间复杂度为O(nlogn),但在极端条件下会退化为O(n2)。
3. 归并排序
3.1 归并排序原理
与快速排序相反,归并排序正好把排序和递归反过来。快速排序先排序再递归细分,排序是从上到下的。归并排序先递归细分再排序,排序是从下到上的,简单过程如下:
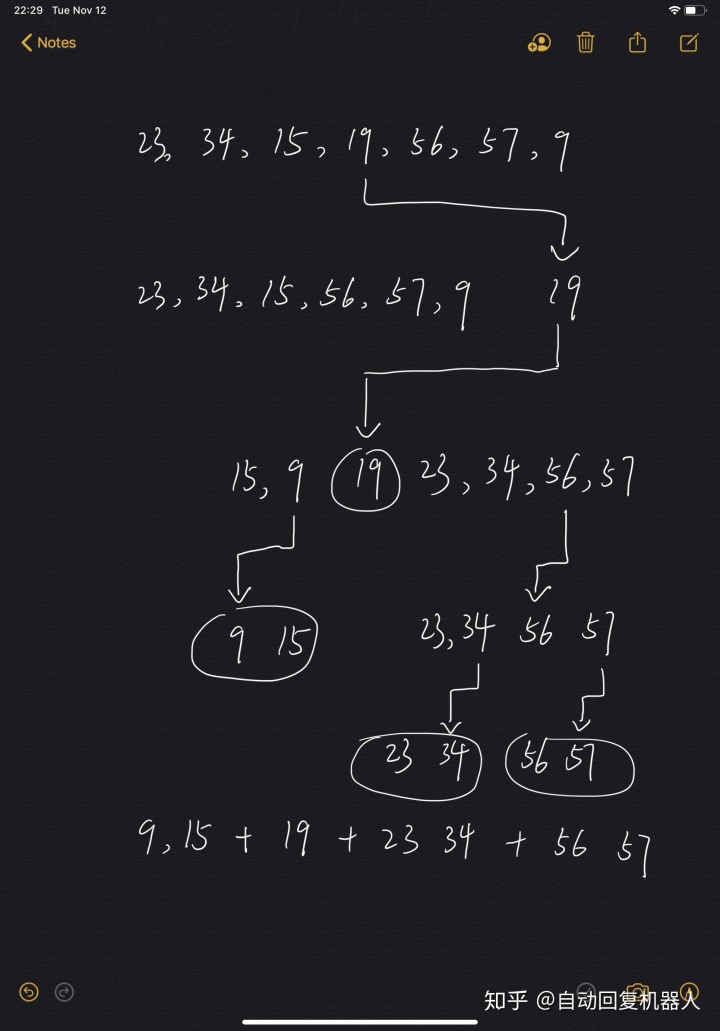
3.2 归并排序实现(Python)
#Merge sort function
def mergeSort(data):
if len(data) > 1:
mid = data[len(data)//2] #Find the mid-value in the data
left, right = [], []
data.remove(mid)
for i in data:
if i >= mid:
right.append(i)
else:
left.append(i)
return mergeSort(left) + [mid] + mergeSort(right)
else:
return data3.3 归并排序时间复杂度
归并排序的一大好处就是不管数据是什么样的,它的时间复杂度都为O(nlogn)。
4. 堆排序
4.1 堆排序原理
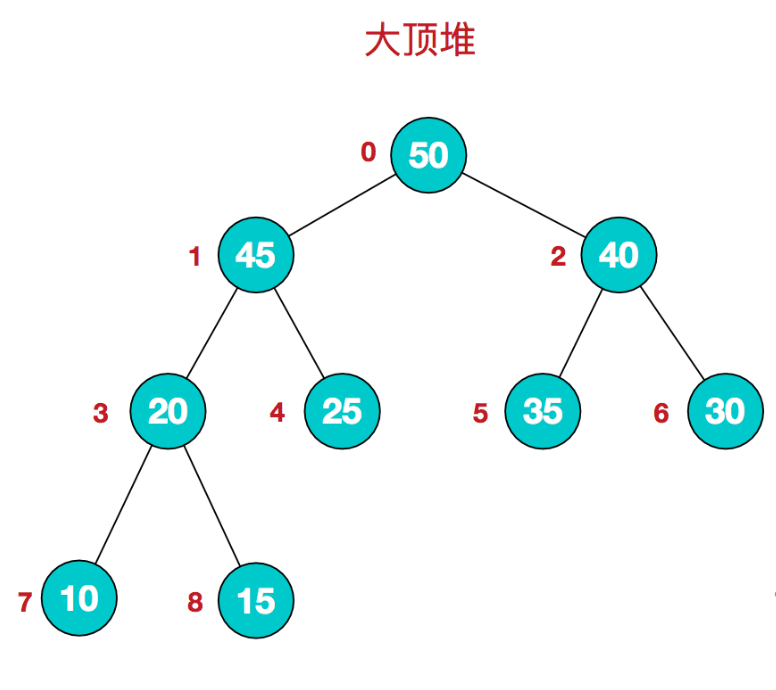
堆排序(英语:Heapsort)是指利用堆这种数据结构所设计的一种排序算法。
堆排序的简单过程如下:
- 最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点。
- 创建最大堆(Build Max Heap):将堆中的所有数据重新排序。
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算。
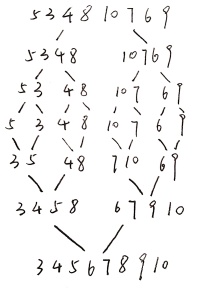
若以文本文件input-data.txt中的数据为例,则有如下过程:

4.2 堆排序实现(Python)
#Heap sort function
def big_endian(data, start, end):
root = start
child = root * 2 + 1 # 左孩子
while child <= end:
# 孩子比最后一个节点还大,也就意味着最后一个叶子节点了,就得跳出去一次循环,已经调整完毕
if child + 1 <= end and data[child] < data[child + 1]:
# 为了始终让其跟子元素的较大值比较,如果右边大就左换右,左边大的话就默认
child += 1
if data[root] < data[child]:
# 父节点小于子节点直接交换位置,同时坐标也得换,这样下次循环可以准确判断:是否为最底层,
# 是不是调整完毕
data[root], data[child] = data[child], data[root]
root = child
child = root * 2 + 1
else:
break
def heapSort(data): # 大顶堆排序
first = len(data) // 2 - 1
high = len(data) - 1
for start in range(first, -1, -1):
# 从下到上,从左到右对每个节点进行调整,循环得到非叶子节点
big_endian(data, start, high) # 去调整所有的节点
for end in range(high, 0, -1):
data[0], data[end] = data[end], data[0] # 顶部尾部互换位置
big_endian(data, 0, end - 1) # 重新调整子节点的顺序,从顶开始调整
return data4.3 堆排序时间复杂度
与归并排序类似,堆排序的时间复杂度为O(nlogn)。
5. 参考
快速排序算法_百度百科baike.baidu.com















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









