





记录物理存储
定长记录
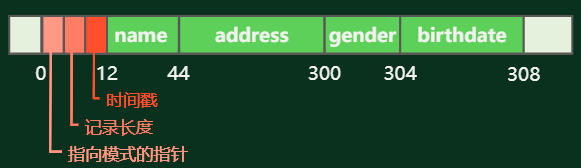
变长记录

多记录存储
物理邻接存储

指针连接存储


大字段存储(BLOBS)
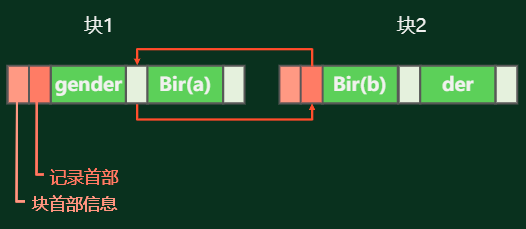
文件组织方式
- 堆文件
- 顺序文件
- 散列文件
- 插入删除快
- 存取快
- 不需要为存储索引
- 记录随机
- 不能排序
- 有可能导致桶倾斜
- 聚簇文件
- 把多个表物理存储在一起
- 提高多表关联查询
- 降低单表查询效率
- 按列存储
索引
聚集索引
索引的顺序与数据文件的顺序一致,例如mysql的主键索引,一般一个表只有一个聚集索引
辅助索引
索引的顺序与数据文件的顺序不一致,索引的值为主键,需要通过二级查询才能到达记录
稠密索引
为每个键建立索引
稀疏索引
在顺序文件中,只为每个块建立一个索引键
有序索引
索引是按序排列的,例如B+树索引
散列索引
索引是无序的,通过hash来访问数据
静态散列
动态散列
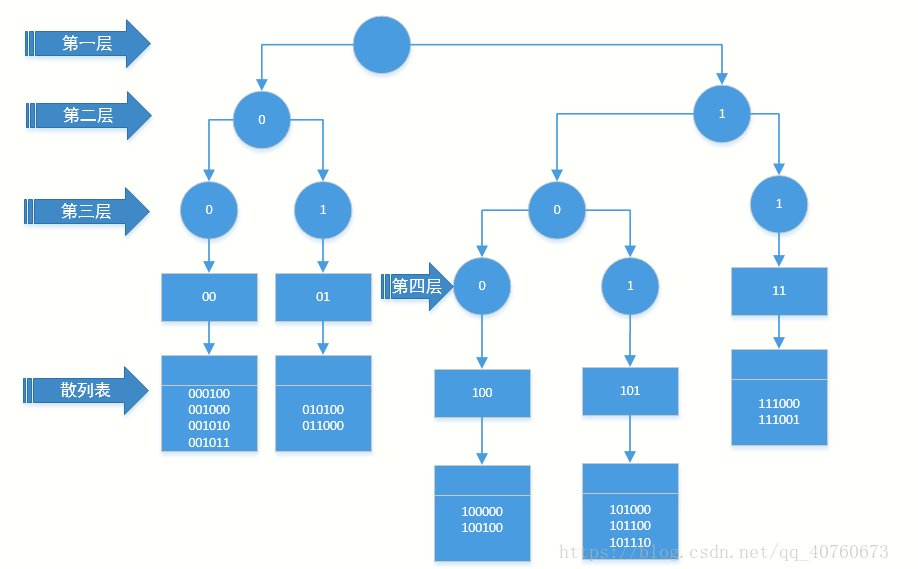
线性散列
index=hash(key)%n,当发生冲突时,index++
多段散列
多级索引
使用稠密和稀疏索引建立多级索引
查询与优化
查询代价的度量
响应时间 = 磁盘存储时间+CPU运算时间+数据传输时间
对于本地大型数据库一般只考虑磁盘存取时间
查询处理过程

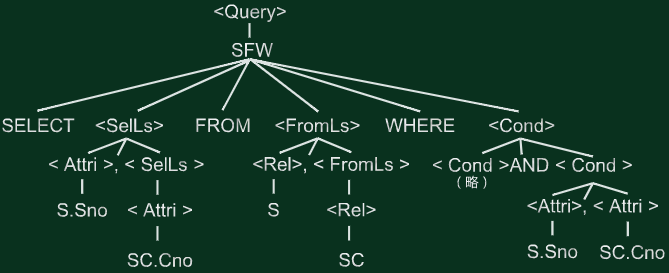
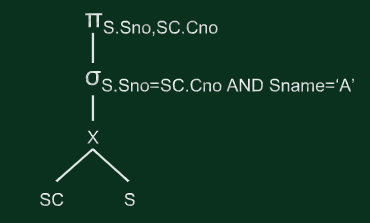
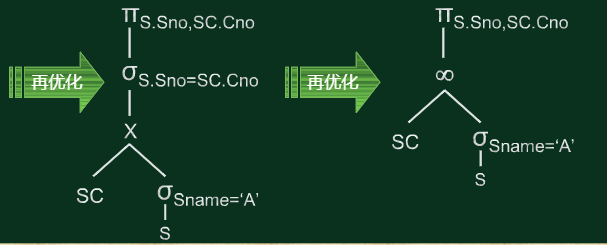

关系查询算法
选择/投影/连接
- 投影:select 子句
- 选择:where子句
- 连接:join子句
查询算法
- 基于排序的算法
- 基于散列的算法
- 基于索引的算法
- 一趟或多趟算法
一趟排序算法
实现的算法包括并,交,差,消除重复元组
如果内存可以至少容纳一个表的数据,可以把一个表的数据全部加载在内存,然后对键进行排序,然后通过扫描第二表表,一趟把结果计算出来
多趟排序算法
在两个表的数据都非常非常大,此时则需要先用归并算法得出两个表的排序记录,然后再在内存堆两个排序表进行并交差等运算,运算的过程中设计多次的磁盘读入和写出
多趟散列算法
- 为每个表建立k个桶
- 扫描每个表并发记录hash到k个桶
- 在内存中加载两个表的第i个桶,进行并交差运算
- 如果第i个桶的数据量大于内存可以装载的数量,则需要对第i个进行二次hash,直到内存可以装载为止
基于索引的算法
- 遍历第一个表
- 通过第一个表的键直接通过索引查询第二个表
- 在内存中进行并交叉运算
运算过程方式
实体化方法
每次运算的中间结果重新写回磁盘,下一个运算再次从磁盘读取中间结果并进行再次运算,直到得出结果
流水式方法
每次运算的中间结果保存在内存,下次运算直接从内存获得中间结果并进行再次运算,直到得出结果
查询优化
- 通过关系运算的等价变换简化逻辑查询
- 通过选择运算下移而减少查询代价
- 通过对多个方案的估量,选择一种物理查询,确定每个查询子句是否使用索引查询还是线性查询,是否使用归并
故障恢复
错误的数据输入
例如用户错误数据类型,效率低的sql
需要对客户端进行限制,并制定策略检测和禁止某些危险行为
系统错误
由于掉电,软件错误造成内存中数据丢失或者错误
通过数据库的恢复机制,从日志和事务中对数据进行恢复
介质故障
由于磁盘局部故障,例如磁头损坏,扇区损坏
通过存储的奇偶校验或者使用RAID技术
灾难性故障
发生不可逆转的灾难,导致数据据介质完全损坏,无法对介质进行任何的恢复
通过多地即时备份
事务
特定ACID
Atomicity 原子性
事务是一个不可分割的单元,要么全部成功,要么全部失败
Consistency 一致性
事务前后数据的完整性必须保证业务的一致性
Isolation 隔离性
多个事务在并发处理时,互相隔离
Durability 持久性
事务一旦提交,它对数据的修改是永久的,即时此时发生数据库发生系统故障,也不应该对此有任何影响
日志
SQL执行过程
日志记录的信息
- 事务开始
- 事务成功提交
- 事务提交失败
- 数据表更: 事务ID update A oldValue newValue
- 检查点
undo日志
规则
- 写日志到磁盘
- 更新数据到磁盘
- 把Commit T写入日志
恢复机制
从后往前找日志,把没有Commit T的事务进行撤销
检查点
检查点包括开始部分和结束部分
开始节点对目前正在活动的事务IdList进行记录
如果数据库检查到所有的IdList都已经完成,则打印一个结束检查点
- 如果从后往前遍历第一个遇到检查点的开始,则找上一个检查点的开始的位置开始遍历
- 如果从后往前遍历第一个遇到检查点的结束,则找此检查点的开始位置开始遍历
- 上一个检查点之前的事务是已经写入磁盘并进行了撤销
- 扫描此检查点之后的事务,对没有提交的事务进行撤销
- 事务有可能跨越多个检查点,此时需要再往前遍历
缺点
频繁将数据更新到磁盘,导致性能不高
redo日志
规则
- 先记录数据更新日志
- 写入Commit T
- 后把数据一次性从内存写入磁盘
恢复机制
重做已经提交的事务
检查点
与undo类似,只是把撤销改成重做
事务并发
问题
- 数据丢失
- 脏读,读到了未提交的数据
- 幻读,同一个事务两次读同一个变量,是不一样的值
调度
串行调度
两个事务,按照顺序一个接一个的执行
可串行化调度
两个事务,通过指令穿插的方式执行,执行的结果与串行执行的结果一致
冲突可串行化调度
不可串行化调度
在某个事务的一个并发结果与串行化调度的结果不一致
锁
保证可串行化的预防型策略
加锁产生的问题
- 在事务内随意的解锁,会导致不可串行化调度
- 两个事务加锁顺序不对,导致死锁
- 多个事务不断的加读锁,导致先加写锁的事务饿死
两阶段锁协议
- 增长阶段:事务获得锁,而不能解锁
- 缩减阶段:事务解锁,而不能获得锁
严格两阶段锁
在提交前释放锁
遵循两阶段锁的并发控制算法是冲突可串行化调度。但仍然存在死锁和级联回滚的发生。
强两阶段锁
在提交之前不允许释放任何锁
可以避免级联回滚,但依然存在死锁
多粒度锁

- 显式加锁:对元组单独加锁时,为显式加锁
- 隐式加锁:对元组加锁时,会同时对它的所有祖先加意向锁
意向锁
- IS锁:当后代显式加S锁时,对此节点加意向读锁
- IX锁:当后代显式加X锁时,对此节点加意向写锁
- SIX锁:对该节点加S锁,并加IX锁
可串行化多粒度锁协议
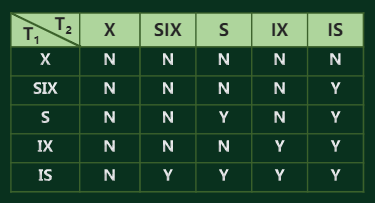
- 加锁时遵循上面的矩阵
- 从根节点由上往下加锁
- 遵循两阶段锁协议
- 由下往上解锁
死锁
- 对锁进行排序,再加锁
- 死锁检测,系统定时加测是否存在T1->T2->T1这样的依赖环,并根据策略回滚环中的其中一些事务,来打破死锁等待的局面
- 抢占与回滚技术:对事务赋予一个时间戳,如果事务回滚,则重启该事务,并保持原有时间戳,通过比较两个事务的时间错的大小,来决定回滚哪个事务
- 超时机制:为每个事务定义一个等待超时时间,超时则回滚
选择事务回滚的策略:
- 选择代价最小的事务
- 为了防止饿死,将回滚次数考虑到代价中
- 锁的协议开销大,并发提升有限
基于时间戳的调度协议
保证可串行化的预防型策略
- TS(T):事务开始执行的时间戳
- W(Q):在Q数据项上,写入的事务最大的时间戳
- R(Q):在Q数据项上,读取的事务最大的时间戳
执行协议
T执行Read(Q)
if TS(T) < W(Q),回退
if TS(T) > W(Q),执行,并更新R(Q) = (TS(T), R(Q))
T执行Write(Q)
if TS(T) < R(Q),回退
If TS(T) < W(Q),回退(可以优化成忽略T对Q的写,并继续执行来提高并行度)
否则执行,并更新W(Q) = TS(T)
T回退,并赋予新的时间戳,重新执行
基于有效性检验的调度协议
保证可串行化的诊治型策略
- 读阶段:读数据并保存在局部变量,并在局部变量中更新数据
- 有效性检查阶段:检查如果把局部变量更新到数据库中而不违背可串行性
- 写阶段:把数据更新到数据库
协议的术语
- start(T):T开始执行的时间
- validation(T):完成有效性检查的时间
- Finish(T):完成写的时间
- RS(T):读数据项的集合
- WS(T):写数据项的集合
有效性检查失败情况
- 场景1
- U比T先开始
- RS(T)和WS(U)有交集
- U先确认
- T校验失败
- 场景2
规则
对于T和先于它执行的U满足以下某一条件,则U和T可串行化
- finish(U)<start(T)
- WS(U)与RS(T)无交集,finish(U)<validation(T)
- WS(T)与RS(T)无交集,WS(U)与WS(T)无交集,validation(U)<validation(T)
事务隔离性级别
严格执行隔离会严重降低吞吐量,因此需要系统根据应用灵活设置隔离级别















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









