





好久不见,各位看官。步入职场已有4年有余,从大学时期的论文《基于Hadoop的电子商务数据存储架构的设计与研究》,初学Hadoop、Hive、HDFS,到工作后学习Spark,学习各种大数据框架,到如今也算是老菜鸟了。
在广告行业混迹了三年之多,对于DMP、OLAP、BI等也算是有了浅显的了解。接触了很多大佬,也了解了很多牛逼的架构设计。但是别人的永远是别人的,个人要想提升自己,认识了解后必须自己去尝试实践,只有实践后才知道适不适合。所以本篇为初实ClickHouse(初次实践)。
废话不说,进入正题。
介绍
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
ClickHouse官方中文文档:https://clickhouse.yandex/docs/zh/
ClickHouse官方英文文档:https://clickhouse.yandex/docs/en/
Performance comparison of analytical DBMS:https://clickhouse.yandex/benchmark.html
OLAP场景的关键特征
大多数是读请求
数据总是以相当大的批(> 1000 rows)进行写入
不修改已添加的数据
每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
宽表,即每个表包含着大量的列
较少的查询(通常每台服务器每秒数百个查询或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
事务不是必须的
对数据一致性要求低
每一个查询除了一个大表外都很小
查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解):
行式
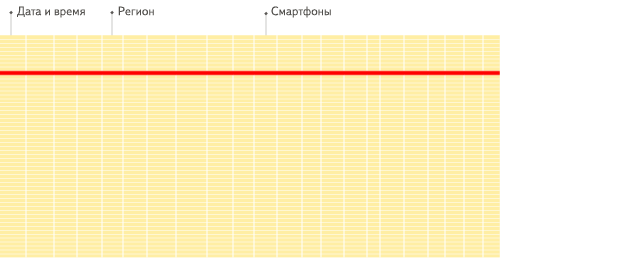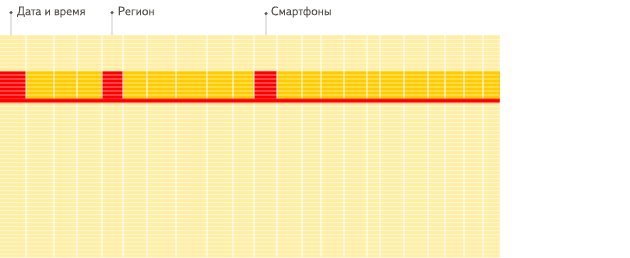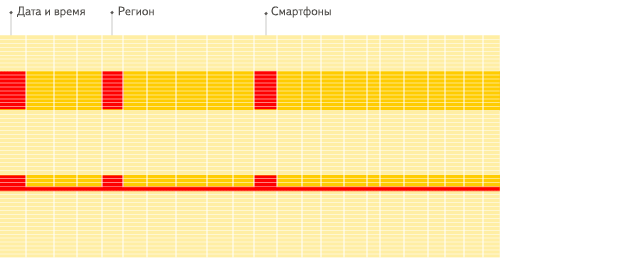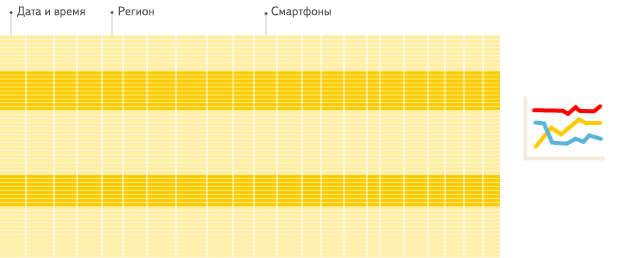
列式
集群部署
安装教程参考:部署运行(https://clickhouse.yandex/docs/en/getting_started/)
数据摄取
目前主要通过 Spark 任务离线导入,22亿条、9个字段,ORC格式400G数据摄入,平均每秒约摄入130万条,对相关查询进行了压力测试,效率比较符合预期,由于涉及真实线上场景,暂不做具体分享。
网上有大神开源相关摄入代码可以参考,但是在实际开发过程中经常会需要多个PARTITION,我做了稍微的改进,已上传本人GitHub(https://github.com/wjf0627/bigdata/tree/master/clickhouse),后期会陆续将更新其他操作,欢迎关注。
后期目标及展望
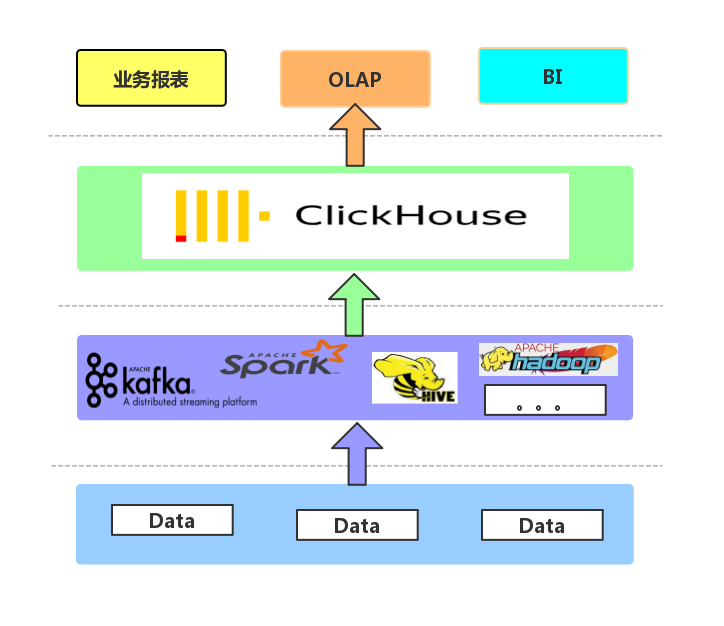
PS:图的画有点糙,各位看官请见谅。
谢谢您的宝贵时间!下期将浅谈 DMP 及如何通过数据更有效的变现,期待您的关注。















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









